S-ar putea să vă placă și
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- Excel Sales Report TemplateDocument3 paginiExcel Sales Report TemplateMark11311100% (1)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Disomat Tersus: Instruction ManualDocument268 paginiDisomat Tersus: Instruction ManualMohamed Hamad100% (1)
- Synthetic Fiber Reinforced ConcreteDocument13 paginiSynthetic Fiber Reinforced ConcreteSahir Abas0% (1)
- Openstack 888Document68 paginiOpenstack 888Subbarao AppanabhotlaÎncă nu există evaluări
- Openstack 888Document68 paginiOpenstack 888Subbarao AppanabhotlaÎncă nu există evaluări
- Using H2 As A Gas Turbine FuelDocument8 paginiUsing H2 As A Gas Turbine FuelFutureGreenScienceÎncă nu există evaluări
- 522 UNIX Process (w3 1)Document37 pagini522 UNIX Process (w3 1)Subbarao AppanabhotlaÎncă nu există evaluări
- Lecture 10Document14 paginiLecture 10Subbarao AppanabhotlaÎncă nu există evaluări
- Pagingspace MemoryDocument2 paginiPagingspace MemorySubbarao AppanabhotlaÎncă nu există evaluări
- Earl Jew Part II How To Monitor and Analyze AIX VMM and Storage IO Statistics Apr4-13Document39 paginiEarl Jew Part II How To Monitor and Analyze AIX VMM and Storage IO Statistics Apr4-13Subbarao AppanabhotlaÎncă nu există evaluări
- AIX I/O Performance TuningDocument16 paginiAIX I/O Performance TuningSubbarao AppanabhotlaÎncă nu există evaluări
- Linux Memory ManagementDocument32 paginiLinux Memory ManagementRaja AfzaalÎncă nu există evaluări
- MSPP Aix VugDocument41 paginiMSPP Aix VugSubbarao AppanabhotlaÎncă nu există evaluări
- Vcs Gab LLT BasicsDocument1 paginăVcs Gab LLT Basicsjsdksahdkjas77Încă nu există evaluări
- VughaintrodemosDocument63 paginiVughaintrodemosSubbarao AppanabhotlaÎncă nu există evaluări
- A Performance Analysis of Hadoop Clusters in Openstack Cloud and in Real SystemDocument6 paginiA Performance Analysis of Hadoop Clusters in Openstack Cloud and in Real SystemSubbarao AppanabhotlaÎncă nu există evaluări
- Linux TCSDocument229 paginiLinux TCSAmarnath ReddyÎncă nu există evaluări
- AIX VIOS DiskAndAdapterQueueTuningV1.2 1Document46 paginiAIX VIOS DiskAndAdapterQueueTuningV1.2 1Subbarao AppanabhotlaÎncă nu există evaluări
- AN121 G 01Document23 paginiAN121 G 01Manoranjan SahooÎncă nu există evaluări
- 10 Red Hat® Linux™ Tips and TricksDocument9 pagini10 Red Hat® Linux™ Tips and Tricksm.tousif.n.kÎncă nu există evaluări
- Beginning Python 5584af342bbeaDocument24 paginiBeginning Python 5584af342bbeaSubbarao AppanabhotlaÎncă nu există evaluări
- GRUB 2 Bootloader - Full TutorialDocument47 paginiGRUB 2 Bootloader - Full TutorialaminvogueÎncă nu există evaluări
- Serve Well Group Pty LTD in VoiceDocument1 paginăServe Well Group Pty LTD in VoiceSubbarao AppanabhotlaÎncă nu există evaluări
- SvnmapDocument1.210 paginiSvnmapSubbarao AppanabhotlaÎncă nu există evaluări
- V4la Linuxessentials Studysheet 1434756799Document28 paginiV4la Linuxessentials Studysheet 1434756799Subbarao AppanabhotlaÎncă nu există evaluări
- Serve Well AgreementDocument10 paginiServe Well AgreementSubbarao AppanabhotlaÎncă nu există evaluări
- GC WeakrefDocument4 paginiGC WeakrefSubbarao AppanabhotlaÎncă nu există evaluări
- KVMDocument1 paginăKVMSubbarao AppanabhotlaÎncă nu există evaluări
- RHEL7 Good MustreadDocument334 paginiRHEL7 Good MustreadSubbarao Appanabhotla100% (2)
- Special BuildsDocument5 paginiSpecial BuildsSubbarao AppanabhotlaÎncă nu există evaluări
- Special BuildsDocument5 paginiSpecial BuildsSubbarao AppanabhotlaÎncă nu există evaluări
- ReadmeDocument3 paginiReadmeSubbarao AppanabhotlaÎncă nu există evaluări
- Beginning Python 5584af342bbeaDocument24 paginiBeginning Python 5584af342bbeaSubbarao AppanabhotlaÎncă nu există evaluări
- Polymer-Plastics Technology and EngineeringDocument6 paginiPolymer-Plastics Technology and Engineeringsamuelben87Încă nu există evaluări
- Leadership Quality ManagementDocument8 paginiLeadership Quality Managementselinasimpson361Încă nu există evaluări
- Management - Ch06 - Forecasting and PremisingDocument9 paginiManagement - Ch06 - Forecasting and PremisingRameshKumarMurali0% (1)
- Silver Nanoparticles DataDocument6 paginiSilver Nanoparticles DataSanwithz SittiÎncă nu există evaluări
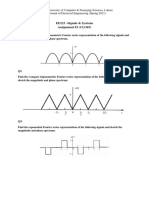
- EE223 - Signals & Systems Assignment #3 (CLO#3)Document3 paginiEE223 - Signals & Systems Assignment #3 (CLO#3)haider aliÎncă nu există evaluări
- LN 10.5 Ttdomug En-UsDocument82 paginiLN 10.5 Ttdomug En-UstomactinÎncă nu există evaluări
- Chapter 4 - Production TheoryDocument10 paginiChapter 4 - Production TheorypkashyÎncă nu există evaluări
- MRM Assignment Written Analysis FormatDocument2 paginiMRM Assignment Written Analysis FormatMd AliÎncă nu există evaluări
- Book - Lattice Boltzmann Methods For Shallow Water FlowsDocument117 paginiBook - Lattice Boltzmann Methods For Shallow Water FlowsMauricio Fabian Duque DazaÎncă nu există evaluări
- Planar Edge Terminations For High Power SiC DiodesDocument234 paginiPlanar Edge Terminations For High Power SiC DiodesRaul PerezÎncă nu există evaluări
- Conte R Fort WallDocument30 paginiConte R Fort Wallmirko huaranccaÎncă nu există evaluări
- Linear Interpolation Equation Formula Calculator PDFDocument3 paginiLinear Interpolation Equation Formula Calculator PDFMatthew HaleÎncă nu există evaluări
- LG FlatRon RepairDocument55 paginiLG FlatRon Repairdany89roÎncă nu există evaluări
- EXPERIMENT 3 OHMS LAW (1) GUY DERVILLE Cc7b49ceDocument4 paginiEXPERIMENT 3 OHMS LAW (1) GUY DERVILLE Cc7b49ceDully CleverÎncă nu există evaluări
- Rapid Prototyping PPT SeminarDocument32 paginiRapid Prototyping PPT SeminarShantha Kumar G C0% (1)
- Laboratory Assignments On Experiment 1: Measurement of Self-Inductance by Maxwell's BridgeDocument2 paginiLaboratory Assignments On Experiment 1: Measurement of Self-Inductance by Maxwell's BridgesparshÎncă nu există evaluări
- Sidhu New Nozzles Broucher 20Document16 paginiSidhu New Nozzles Broucher 20Laboratorio PapelesRegionalesÎncă nu există evaluări
- ELTE 307 - DR Mohamed Sobh-Lec - 5-1-11-2022Document28 paginiELTE 307 - DR Mohamed Sobh-Lec - 5-1-11-2022Lina ElsayedÎncă nu există evaluări
- Holiday Homework Class 12 MathematicsDocument2 paginiHoliday Homework Class 12 MathematicsKartik SharmaÎncă nu există evaluări
- (Pakget - PK) Maths MCQS Book (Pakget - PK)Document42 pagini(Pakget - PK) Maths MCQS Book (Pakget - PK)Mohammad AshfaqÎncă nu există evaluări
- Lucifer's Mirror and The Emancipation of OnenessDocument23 paginiLucifer's Mirror and The Emancipation of OnenessTony BermansederÎncă nu există evaluări
- Polymers 14 03693 v2Document20 paginiPolymers 14 03693 v2Abd BAGHADÎncă nu există evaluări
- A Handheld Gun Detection Using Faster R-CNN Deep LearningDocument5 paginiA Handheld Gun Detection Using Faster R-CNN Deep LearningJanderson LiraÎncă nu există evaluări
- Discovery of A New Energy VortexDocument4 paginiDiscovery of A New Energy Vortexnblack3335140Încă nu există evaluări