S-ar putea să vă placă și
- LDA KNN LogisticDocument29 paginiLDA KNN Logisticshruti gujar100% (1)
- Business Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means ClusteringDocument28 paginiBusiness Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means Clusteringcrispin anthonyÎncă nu există evaluări
- Advanced Statistics ProjectDocument12 paginiAdvanced Statistics ProjectEric NormanÎncă nu există evaluări
- PM P L Lohitha 12-12-22 Business ReportDocument31 paginiPM P L Lohitha 12-12-22 Business ReportLohitha PakalapatiÎncă nu există evaluări
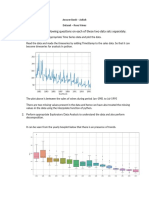
- Project QuestionsDocument3 paginiProject QuestionsravikgovinduÎncă nu există evaluări
- Pradeep Chauhan Business Report 09july'23Document32 paginiPradeep Chauhan Business Report 09july'23Pradeep ChauhanÎncă nu există evaluări
- SMDM Project - Business Report - RDocument21 paginiSMDM Project - Business Report - Rhepzi selvam100% (2)
- ML Quiz 2Document1 paginăML Quiz 2Ruwayda IbraheemÎncă nu există evaluări
- Predictive Modelling Project Report: Sreekrishnan Sirukarumbur MuralikrishnanDocument16 paginiPredictive Modelling Project Report: Sreekrishnan Sirukarumbur Muralikrishnansaarang KÎncă nu există evaluări
- Akshaya SMDM Project ReportDocument18 paginiAkshaya SMDM Project ReportAkshaya Kennedy100% (1)
- Advanced Applied Statistics ProjectDocument16 paginiAdvanced Applied Statistics ProjectIshtiaq IshaqÎncă nu există evaluări
- Week 1 QuizDocument28 paginiWeek 1 QuizMark100% (1)
- Time Series and ForecastingDocument3 paginiTime Series and ForecastingkaviyapriyaÎncă nu există evaluări
- Quiz 3 Name: Kainat Iftikhar Reg# 2021630007 1. List Three Examples of Time Series Data. Time Series DataDocument2 paginiQuiz 3 Name: Kainat Iftikhar Reg# 2021630007 1. List Three Examples of Time Series Data. Time Series Dataraja ahmedÎncă nu există evaluări
- Advanced Statistics-ProjectDocument16 paginiAdvanced Statistics-Projectvivek rÎncă nu există evaluări
- Asphalt Shingles Data Analysis PDFDocument4 paginiAsphalt Shingles Data Analysis PDFsonali PradhanÎncă nu există evaluări
- Problem 2 Businessreport MLDocument9 paginiProblem 2 Businessreport MLRajeshÎncă nu există evaluări
- Project: Advanced Statistics: Anova, Eda and PcaDocument35 paginiProject: Advanced Statistics: Anova, Eda and PcaBhagyaSree JÎncă nu există evaluări
- Assignment ClusteringDocument22 paginiAssignment ClusteringNetra RainaÎncă nu există evaluări
- AS Project ReportDocument22 paginiAS Project ReportLohitha PakalapatiÎncă nu există evaluări
- DATA MINING PROJECT PAVITHRAA GOVINDARAJAN 24 OCT 2021 Jupyter Notebook PDFDocument49 paginiDATA MINING PROJECT PAVITHRAA GOVINDARAJAN 24 OCT 2021 Jupyter Notebook PDFGURUPADA PATI100% (1)
- Suresh-Rose Time Series Forecasting Project ReportDocument75 paginiSuresh-Rose Time Series Forecasting Project ReportARCHANA R100% (1)
- Advanced Statistics Project Sudharsan SDocument34 paginiAdvanced Statistics Project Sudharsan SBadazz doodÎncă nu există evaluări
- Program Delivery Schedule PGP-DSBA (Data Science and Business Analytics)Document3 paginiProgram Delivery Schedule PGP-DSBA (Data Science and Business Analytics)Parthesh Roy TewaryÎncă nu există evaluări
- Predictive Modelling Alternative Firm Level PDFDocument26 paginiPredictive Modelling Alternative Firm Level PDFAnkita Mishra100% (3)
- Vidhya - SMDM ProjectDocument21 paginiVidhya - SMDM Projectvidyaramesh50% (2)
- Best PDFDocument16 paginiBest PDFSankarÎncă nu există evaluări
- Data Mining QuizDocument4 paginiData Mining QuizJohn EdÎncă nu există evaluări
- Machine Learning Project: Raghul HarishDocument46 paginiMachine Learning Project: Raghul HarishARUNKUMAR S100% (1)
- Machine Learning Business Report - Compress (AutoRecovered)Document69 paginiMachine Learning Business Report - Compress (AutoRecovered)Deepanshu Parashar100% (2)
- Machine Learning SolutionDocument12 paginiMachine Learning Solutionprabu2125100% (1)
- ML Project Report: (Text Learning Case Study)Document9 paginiML Project Report: (Text Learning Case Study)ankitbhagatÎncă nu există evaluări
- Answer Book - Rose WinesDocument11 paginiAnswer Book - Rose WinesAshish Agrawal100% (1)
- Machine Learning Project - HTML PDFDocument72 paginiMachine Learning Project - HTML PDFRaveena100% (3)
- Machine Learning - Nabeel Khan - Final Project Report - Problem 2Document24 paginiMachine Learning - Nabeel Khan - Final Project Report - Problem 2KhursheedKhan100% (1)
- Simple Regression QuizDocument6 paginiSimple Regression QuizKiranmai GogireddyÎncă nu există evaluări
- SMDM Project ReportDocument19 paginiSMDM Project ReportSANJAY ANANDAN100% (1)
- Predictive Modelling - Linear Discriminant Analysis - Mentor Version - Jupyter NotebookDocument25 paginiPredictive Modelling - Linear Discriminant Analysis - Mentor Version - Jupyter Notebooksambitmishra_gec100% (1)
- Random Forest - US - Heart - Patients - ClassDocument24 paginiRandom Forest - US - Heart - Patients - ClassShripad H100% (1)
- Business Report: Advanced Statistics Module Project - IIDocument9 paginiBusiness Report: Advanced Statistics Module Project - IIPrasad MohanÎncă nu există evaluări
- Data Mining Project - 27.06.2021Document6 paginiData Mining Project - 27.06.2021vansh guptaÎncă nu există evaluări
- Clustering Analysis: Prepared by Muralidharan NDocument16 paginiClustering Analysis: Prepared by Muralidharan Nrakesh sandhyapoguÎncă nu există evaluări
- Project QuestionsDocument4 paginiProject Questionsvansh guptaÎncă nu există evaluări
- Anshul Dyundi Predictive Modelling Alternate Project July 2022Document11 paginiAnshul Dyundi Predictive Modelling Alternate Project July 2022Anshul DyundiÎncă nu există evaluări
- AS Practice Exercise 3 Model Solution PDFDocument2 paginiAS Practice Exercise 3 Model Solution PDFRohan KanungoÎncă nu există evaluări
- Data Mining Clustering PDFDocument15 paginiData Mining Clustering PDFSwing TradeÎncă nu există evaluări
- SMDM Extended ProjectDocument1 paginăSMDM Extended Projectsrashti tripathiÎncă nu există evaluări
- Predictive ModelingDocument38 paginiPredictive ModelingHafsah Wita KusumaÎncă nu există evaluări
- Logistic Regression Quiz: Pandas Version: 1.0.5 Seaborn Version: 0.10.1 Matplotlib Version: 3.2.1 Sklearn Version: 0.23.1Document1 paginăLogistic Regression Quiz: Pandas Version: 1.0.5 Seaborn Version: 0.10.1 Matplotlib Version: 3.2.1 Sklearn Version: 0.23.1AbhijitSinha0% (1)
- Project 4 - Cars-Datasets PDFDocument44 paginiProject 4 - Cars-Datasets PDFTunde Asaaju100% (2)
- One Whose Properties Do Not Depend On The Time at Which The Series Is ObservedDocument12 paginiOne Whose Properties Do Not Depend On The Time at Which The Series Is ObservedbadaltelÎncă nu există evaluări
- ML Quiz 1: Course ContentDocument13 paginiML Quiz 1: Course ContentAbhijitSinhaÎncă nu există evaluări
- AS Notebook - PCA - Wine Data-4Document1 paginăAS Notebook - PCA - Wine Data-4Pranali Malode100% (1)
- Data Mining - ProjectDocument25 paginiData Mining - ProjectAbhishek Arya100% (1)
- Assignment MLDocument21 paginiAssignment MLManish Verma100% (2)
- AnswerDocument5 paginiAnswersonali Pradhan100% (2)
- Predictive Modelling Report - ReshmaDocument20 paginiPredictive Modelling Report - Reshmareshma ajithÎncă nu există evaluări
- SMDM Project 2021: September 9Document16 paginiSMDM Project 2021: September 9animehÎncă nu există evaluări
- Decision TreeDocument18 paginiDecision TreeRithvik DadapuramÎncă nu există evaluări
- ML Unit 3Document83 paginiML Unit 3sanju.25qtÎncă nu există evaluări
- Modified Lesson PlanDocument6 paginiModified Lesson Planapi-377051886Încă nu există evaluări
- English HL Gr. 4Document9 paginiEnglish HL Gr. 4nadinevanwykrÎncă nu există evaluări
- Conditional Clauses - Type IDocument2 paginiConditional Clauses - Type Icarol0801Încă nu există evaluări
- Treiman Et Al Knowledge of Letter SoundsDocument24 paginiTreiman Et Al Knowledge of Letter SoundsEaint Hmu TharÎncă nu există evaluări
- Mobile Marketing: A Synthesis and Prognosis: Venkatesh Shankar & Sridhar BalasubramanianDocument12 paginiMobile Marketing: A Synthesis and Prognosis: Venkatesh Shankar & Sridhar BalasubramanianSaujanya PaswanÎncă nu există evaluări
- 7564 L3 Qualification Handbook v2Document143 pagini7564 L3 Qualification Handbook v2Achmad Deddy FatoniÎncă nu există evaluări
- Solicitation For Mis AlumniDocument2 paginiSolicitation For Mis AlumniARJAY BANIQUEDÎncă nu există evaluări
- Basics in Clo3D BrochureDocument2 paginiBasics in Clo3D BrochureKarthik Clo100% (1)
- Can Threatened Languages Be Saved PDFDocument520 paginiCan Threatened Languages Be Saved PDFAdina Miruna100% (4)
- Reading and Writing Lesson 4 3Document31 paginiReading and Writing Lesson 4 3Paopao Macalalad100% (1)
- First Term Final Exam: 2. Complete The Conditional Sentences (Type I) by Putting The Verbs Into The Correct FormDocument2 paginiFirst Term Final Exam: 2. Complete The Conditional Sentences (Type I) by Putting The Verbs Into The Correct FormRonaldEscorciaÎncă nu există evaluări
- Wesleyan University - Philippines: Surgical Scrub Cases (Major)Document5 paginiWesleyan University - Philippines: Surgical Scrub Cases (Major)Kristine CastilloÎncă nu există evaluări
- PRN Life Skill and Financial Literacy ProposalDocument7 paginiPRN Life Skill and Financial Literacy Proposalnyawargakkoang2019Încă nu există evaluări
- Trabajo Individual Ingles A1: Unidad 1 - Task 2 - Writing ¡Tarea 2 Writing Task!!!Document5 paginiTrabajo Individual Ingles A1: Unidad 1 - Task 2 - Writing ¡Tarea 2 Writing Task!!!Brenda Natalia PeñarandaÎncă nu există evaluări
- Community Development As A Process and OutputDocument34 paginiCommunity Development As A Process and OutputAngelica NavalesÎncă nu există evaluări
- Neha Ajay UpshyamDocument2 paginiNeha Ajay UpshyamSantoshKumarÎncă nu există evaluări
- CE Section - Docx 1.docx EDIT - Docx ReqDocument7 paginiCE Section - Docx 1.docx EDIT - Docx ReqEdzel RenomeronÎncă nu există evaluări
- Manufacturing Resource PlanningDocument5 paginiManufacturing Resource PlanningNicholas WilliamsÎncă nu există evaluări
- Parent Consent To SPGDocument2 paginiParent Consent To SPGJaycel EljayÎncă nu există evaluări
- Topic 9 Remedial and EnrichmentDocument13 paginiTopic 9 Remedial and Enrichmentkorankiran50% (2)
- Scope of Guidance - NotesDocument2 paginiScope of Guidance - NotesDr. Nisanth.P.MÎncă nu există evaluări
- Ielts Writing Task 2Document3 paginiIelts Writing Task 2Nhu NguyenÎncă nu există evaluări
- DF2 My Course Syllabus EthicsDocument2 paginiDF2 My Course Syllabus EthicsRushid Jay Samortin SanconÎncă nu există evaluări
- My Favourite Restaurant: Exam TaskDocument1 paginăMy Favourite Restaurant: Exam Tasksamuel pickwoodÎncă nu există evaluări
- Research Process: Presented By:-Aditi GargDocument12 paginiResearch Process: Presented By:-Aditi Gargpllau33Încă nu există evaluări
- SLE201v15 SLES15 Admin Course DescriptionDocument2 paginiSLE201v15 SLES15 Admin Course DescriptionIkram50% (2)
- Mc101 Nur Micropara OrientationDocument22 paginiMc101 Nur Micropara OrientationAskYahGirl ChannelÎncă nu există evaluări
- English 6 DLL Q2 Week 3 11 21 25 2022Document9 paginiEnglish 6 DLL Q2 Week 3 11 21 25 2022Mary Grace Contreras100% (1)
- Cep 800-Benson-Lesson Plan ReflectionDocument4 paginiCep 800-Benson-Lesson Plan Reflectionapi-240037779Încă nu există evaluări
- Statement of PurposeDocument8 paginiStatement of PurposeRikhil NairÎncă nu există evaluări