S-ar putea să vă placă și
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (894)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Sec VoipDocument2 paginiSec VoipMadhan SureshÎncă nu există evaluări
- Fortinet - NSE4 Written Exam (400) Version: 7.0Document5 paginiFortinet - NSE4 Written Exam (400) Version: 7.0mcabrejosfe25% (4)
- Security+ Notes v.2Document69 paginiSecurity+ Notes v.2Avo Andrinantenaina100% (1)
- MPLS LDP (Label Distribution Protocol)Document5 paginiMPLS LDP (Label Distribution Protocol)Emad MohamedÎncă nu există evaluări
- Movie HD FavDocument2 paginiMovie HD Favcardo dalisayÎncă nu există evaluări
- Chapter 4 v8.0Document102 paginiChapter 4 v8.0montaha dohanÎncă nu există evaluări
- Milesight Product Catalogue (V4.1)Document34 paginiMilesight Product Catalogue (V4.1)caldana5Încă nu există evaluări
- Principet e Projektimit Te ShtresaveDocument27 paginiPrincipet e Projektimit Te ShtresaveXhesilda VogliÎncă nu există evaluări
- 06 - VXLAN Part VI VXLAN BGP EVPN - Basic ConfigurationsDocument22 pagini06 - VXLAN Part VI VXLAN BGP EVPN - Basic ConfigurationsNguyen LeÎncă nu există evaluări
- Subnetting An Ipv4 NetworkDocument3 paginiSubnetting An Ipv4 NetworkHu-Jean RussellÎncă nu există evaluări
- Introduction To Transmission Media: Huawei Technologies Co., LTDDocument13 paginiIntroduction To Transmission Media: Huawei Technologies Co., LTDmangla\Încă nu există evaluări
- Aloha PDFDocument4 paginiAloha PDFAshok Kumar YadavÎncă nu există evaluări
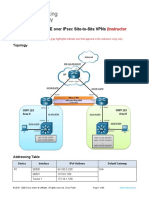
- 16.1.4 Lab - Implement GRE Over IPsec Site-To-Site VPNs - ILMDocument33 pagini16.1.4 Lab - Implement GRE Over IPsec Site-To-Site VPNs - ILMAndrei Petru PârvÎncă nu există evaluări
- Lectuer 4 ChannelizationDocument19 paginiLectuer 4 ChannelizationSaidulu IÎncă nu există evaluări
- Packet Tracer - VLAN Configuration: Addressing TableDocument3 paginiPacket Tracer - VLAN Configuration: Addressing TableMeliton RojasÎncă nu există evaluări
- Ipv6 HSRP Configuration Example: Document Id: 113216Document7 paginiIpv6 HSRP Configuration Example: Document Id: 113216nilber_morianoÎncă nu există evaluări
- Web Technology (2 & 11 Marks)Document196 paginiWeb Technology (2 & 11 Marks)jasdianaÎncă nu există evaluări
- LogDocument156 paginiLogNguyên VũÎncă nu există evaluări
- Chapter 7 QuizDocument3 paginiChapter 7 QuizAstron Smart TVÎncă nu există evaluări
- Networking Essentials 1206 Bac 2005230 Joy Ntinyari KimathiDocument5 paginiNetworking Essentials 1206 Bac 2005230 Joy Ntinyari KimathijoyÎncă nu există evaluări
- Juniper StudiesDocument7 paginiJuniper StudiesJohnÎncă nu există evaluări
- 5 6163216183576232155Document20 pagini5 6163216183576232155vivekw2001100% (1)
- PBX to PBX VoIP Network (H.323Document42 paginiPBX to PBX VoIP Network (H.323WaldirÎncă nu există evaluări
- 642 785Document56 pagini642 785Cristina JuravleÎncă nu există evaluări
- OWD090901 (Slide) UGW9811 V900R009C01 System Overview-20120319-B-V1.1Document51 paginiOWD090901 (Slide) UGW9811 V900R009C01 System Overview-20120319-B-V1.1WalterLooKungVizurragaÎncă nu există evaluări
- IPSEC VPN & Sangfor VPN ComparisonDocument29 paginiIPSEC VPN & Sangfor VPN Comparisonwendy yohanesÎncă nu există evaluări
- Nmap Network Discovery III Reduced Size PDFDocument937 paginiNmap Network Discovery III Reduced Size PDFfree5050Încă nu există evaluări
- Scaling Networks (Version 6.00) - ScaN OSPF Practice Skills Assessment - PT AnswersDocument8 paginiScaling Networks (Version 6.00) - ScaN OSPF Practice Skills Assessment - PT AnswersCCNAv750% (4)
- MPLS Seven Pillars of CarrierGrade SecurityDocument14 paginiMPLS Seven Pillars of CarrierGrade SecurityBruno Filipe TeixeiraÎncă nu există evaluări