S-ar putea să vă placă și
- Tennis Cif Rules BylawsDocument8 paginiTennis Cif Rules Bylawsapi-542771387Încă nu există evaluări
- Brief History of BasketballDocument39 paginiBrief History of BasketballApril Joy DatulaytaÎncă nu există evaluări
- Machine Learning and Data Mining For Sports Analytics: Ulf Brefeld Jesse Davis Jan Van Haaren Albrecht ZimmermannDocument135 paginiMachine Learning and Data Mining For Sports Analytics: Ulf Brefeld Jesse Davis Jan Van Haaren Albrecht ZimmermannAgalievÎncă nu există evaluări
- Lesson 3 4 SwimmingDocument6 paginiLesson 3 4 SwimmingFraveeseÎncă nu există evaluări
- Brand Protection Guideline For Advertising MarketDocument54 paginiBrand Protection Guideline For Advertising MarketLucas FelipeÎncă nu există evaluări
- Biomechanical Analysis of The Sprint and Hurd PDFDocument35 paginiBiomechanical Analysis of The Sprint and Hurd PDFc0% (2)
- Run with Power: The Complete Guide to Power Meters for RunningDe la EverandRun with Power: The Complete Guide to Power Meters for RunningEvaluare: 3 din 5 stele3/5 (1)
- Mobility Patterns, Big Data and Transport Analytics: Tools and Applications for ModelingDe la EverandMobility Patterns, Big Data and Transport Analytics: Tools and Applications for ModelingConstantinos AntoniouÎncă nu există evaluări
- Anomaly Detection On Time Series Data Challenge RulesDocument8 paginiAnomaly Detection On Time Series Data Challenge RulesIndir Jaganjac100% (1)
- Public Datasets: Starting PointsDocument6 paginiPublic Datasets: Starting PointsrajasekharÎncă nu există evaluări
- The JRC Medits R ScriptDocument62 paginiThe JRC Medits R ScriptDaiuk.DakÎncă nu există evaluări
- Chapter Iii: Research MethodologyDocument3 paginiChapter Iii: Research MethodologyChris AlcausinÎncă nu există evaluări
- Olympic Data Analysis Using Data ScienceDocument9 paginiOlympic Data Analysis Using Data ScienceIJRASETPublicationsÎncă nu există evaluări
- SSRN Id1618806Document22 paginiSSRN Id1618806nugraha dendiÎncă nu există evaluări
- Project SynopsisDocument4 paginiProject Synopsiskanika MittalÎncă nu există evaluări
- Sample Data Paper (From Elsevier)Document10 paginiSample Data Paper (From Elsevier)Nica CasillaÎncă nu există evaluări
- Date Use Guide - Revision R1 130720 KDr9mXQDocument134 paginiDate Use Guide - Revision R1 130720 KDr9mXQĐào Văn LậpÎncă nu există evaluări
- 2 - I-80 Metadata DocumentationDocument16 pagini2 - I-80 Metadata Documentationmmorad aamraouyÎncă nu există evaluări
- World Cup DissertationDocument8 paginiWorld Cup DissertationPaperWritingServiceSuperiorpapersCanada100% (1)
- Applying Data Mining Techniques To Football Data From European ChampionshipsDocument14 paginiApplying Data Mining Techniques To Football Data From European ChampionshipscmohanraÎncă nu există evaluări
- (2017) Anais - Leveraging Urban Regeneration and Social Legacy - Rio 2016 Olympics and The DeodoDocument3 pagini(2017) Anais - Leveraging Urban Regeneration and Social Legacy - Rio 2016 Olympics and The DeodossccnetoÎncă nu există evaluări
- The PROFOUND Database: Reyer@pik-Potsdam - deDocument32 paginiThe PROFOUND Database: Reyer@pik-Potsdam - deSophia RoseÎncă nu există evaluări
- Judo Match AnalysisDocument15 paginiJudo Match AnalysisAttilio Sacripanti67% (3)
- Bigo Eurostat HackathonDocument31 paginiBigo Eurostat HackathonOneDa Nak CbrÎncă nu există evaluări
- Data Backup Recovery TrainingDocument39 paginiData Backup Recovery Trainingirri_social_sciencesÎncă nu există evaluări
- 1 s2.0 S0765159720300629 MainDocument11 pagini1 s2.0 S0765159720300629 MainHln FrcntÎncă nu există evaluări
- Proposal On BBMSDocument8 paginiProposal On BBMSM.CedrickÎncă nu există evaluări
- Use of The Data Dictionary: PREMIS ExamplesDocument97 paginiUse of The Data Dictionary: PREMIS ExamplesLogiq PierreÎncă nu există evaluări
- Acs2017 Pums ReadmeDocument13 paginiAcs2017 Pums ReadmeDinakar KaspaÎncă nu există evaluări
- 16:01:2023Document6 pagini16:01:2023Karim El GazzarÎncă nu există evaluări
- Product Development Report MingieDocument13 paginiProduct Development Report MingieWamorena Bruno LucasÎncă nu există evaluări
- 2019 IEEE Signal Processing Cup:: Search and Rescue With Drone-Embedded Sound Source LocalizationDocument8 pagini2019 IEEE Signal Processing Cup:: Search and Rescue With Drone-Embedded Sound Source LocalizationLokesh Reddy VakaÎncă nu există evaluări
- Design of A Traffic Fines Management System: The International Journal of Multi-Disciplinary ResearchDocument56 paginiDesign of A Traffic Fines Management System: The International Journal of Multi-Disciplinary Researchwise oneÎncă nu există evaluări
- Multimedia Library PresentationDocument26 paginiMultimedia Library PresentationNikki AngcaoÎncă nu există evaluări
- The Implementrate Sensor and MotionDocument15 paginiThe Implementrate Sensor and Motionahmad rehmanÎncă nu există evaluări
- 3 Case StudiesDocument3 pagini3 Case Studies8110 Kamila0% (1)
- Final Year Bo12Document3 paginiFinal Year Bo12abrar akbarÎncă nu există evaluări
- LBA-ECO CD-32 Flux Tower Network Data Compilation, Brazilian Amazon - 1999-2006Document9 paginiLBA-ECO CD-32 Flux Tower Network Data Compilation, Brazilian Amazon - 1999-2006Lucas BauerÎncă nu există evaluări
- Aagah: Software Design (SD)Document15 paginiAagah: Software Design (SD)Maaz SiddiquiÎncă nu există evaluări
- COOPDaily Announcement 042011Document3 paginiCOOPDaily Announcement 042011jose hurtadoÎncă nu există evaluări
- Predictive Analysis and Effects of COVID-19 On India: M.SC Data ScienceDocument34 paginiPredictive Analysis and Effects of COVID-19 On India: M.SC Data Scienceshital shermaleÎncă nu există evaluări
- NC Cedars USDDC Collection ProcessDocument1 paginăNC Cedars USDDC Collection ProcessA.P. DillonÎncă nu există evaluări
- IIASA-Reporte FinalDocument32 paginiIIASA-Reporte FinalAnonymous cr6UblshyÎncă nu există evaluări
- Open Family Policy Program: Methodology ReportDocument19 paginiOpen Family Policy Program: Methodology ReportAya AmirÎncă nu există evaluări
- Gis ReportDocument51 paginiGis ReportElizabeth Tamar PdltÎncă nu există evaluări
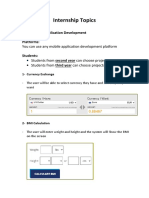
- Internship Topics: I. Mobile Application Development PlatformsDocument9 paginiInternship Topics: I. Mobile Application Development PlatformsAhmed MadaniÎncă nu există evaluări
- C CCCCCCCCCCCCCCCCCCCCCCCCCC: CCCCCCC CCCCCCCCCCCC C CDocument49 paginiC CCCCCCCCCCCCCCCCCCCCCCCCCC: CCCCCCC CCCCCCCCCCCC C Cpriya_makhija24Încă nu există evaluări
- Development and Application of Pyeongchang 2018 Winter Olympic and Paralympic Games Accessibility ManualDocument9 paginiDevelopment and Application of Pyeongchang 2018 Winter Olympic and Paralympic Games Accessibility Manualvivien bajoÎncă nu există evaluări
- GSLC Week 3 Tour de France PDFDocument5 paginiGSLC Week 3 Tour de France PDFDerian WijayaÎncă nu există evaluări
- 2016 IOC Evaluation Report (Read in "Fullscreen")Document90 pagini2016 IOC Evaluation Report (Read in "Fullscreen")Chicago Tribune100% (1)
- RTM March 2020 Magazine PDFDocument174 paginiRTM March 2020 Magazine PDFPadhaku SinghÎncă nu există evaluări
- Machine Learning Internship ProjectsDocument8 paginiMachine Learning Internship ProjectsPrince JaiswalÎncă nu există evaluări
- What Is DataDocument24 paginiWhat Is DataPRIYAM XEROXÎncă nu există evaluări
- CHAPTER 3 ArhamDocument5 paginiCHAPTER 3 ArhamArham MuhammadRamdhanÎncă nu există evaluări
- 0000039038Document19 pagini0000039038Venkata ManojÎncă nu există evaluări
- 66ship Emissions StudyDocument44 pagini66ship Emissions StudyalgeriacandaÎncă nu există evaluări
- Ehdf QB Iat 2Document17 paginiEhdf QB Iat 2Prashik GamreÎncă nu există evaluări
- Research Proposal To Antibody Inc. For: Instrumentation of The Sisyphean ChamberDocument9 paginiResearch Proposal To Antibody Inc. For: Instrumentation of The Sisyphean Chamberapi-155813311Încă nu există evaluări
- Assignment 2Document4 paginiAssignment 2Ganu BatuleÎncă nu există evaluări
- Blood Bank Management SystemDocument8 paginiBlood Bank Management SystemDr MisbahÎncă nu există evaluări
- Baseline NCSDocument396 paginiBaseline NCSКонстантин КрахмалевÎncă nu există evaluări
- Heart Rate Measurement CNadrag VPoenaru GSuciuDocument5 paginiHeart Rate Measurement CNadrag VPoenaru GSuciuKiran GawandeÎncă nu există evaluări
- 3 Data Collection GB2009Document29 pagini3 Data Collection GB2009javierlg1986Încă nu există evaluări
- Swimming HandoutDocument4 paginiSwimming HandoutAman Gupta100% (2)
- Unit 5 Swimming Rules & Regulations, and Basic Live-Saving Skill & SwimmingDocument14 paginiUnit 5 Swimming Rules & Regulations, and Basic Live-Saving Skill & SwimmingThrecia RotaÎncă nu există evaluări
- Ped 107 OfficiatingDocument76 paginiPed 107 OfficiatingShaira Jean BlancaflorÎncă nu există evaluări
- 57th Cnlcsca Swim SeriesDocument5 pagini57th Cnlcsca Swim Seriesmarting69Încă nu există evaluări
- G-PHED003 Swimming ReviewerDocument2 paginiG-PHED003 Swimming ReviewerKean BognotÎncă nu există evaluări
- Swimming LessonDocument38 paginiSwimming LessonGeguirra, Michiko SarahÎncă nu există evaluări
- Uurprogramme - Sheryl-Anne GroblerDocument28 paginiUurprogramme - Sheryl-Anne GroblerSheryl-anne GroblerÎncă nu există evaluări
- Module 8 - Basic Skills in SwimmingDocument13 paginiModule 8 - Basic Skills in Swimmingcherybe santiagoÎncă nu există evaluări
- Swimming ProjectDocument6 paginiSwimming Projectrazelfaith tois bautistaÎncă nu există evaluări
- Swimming Project FinalDocument20 paginiSwimming Project Finalsakshi83% (6)
- Introduction To Swimming: Who Is Swimming For?Document6 paginiIntroduction To Swimming: Who Is Swimming For?Harry RoyÎncă nu există evaluări
- FINIS BEST Short Course Championships 2019Document22 paginiFINIS BEST Short Course Championships 2019Philbert PapaÎncă nu există evaluări
- 2018 CFYN CoachesDocument6 pagini2018 CFYN CoachesCFYN TigersharksÎncă nu există evaluări
- Junior09 10 14Document6 paginiJunior09 10 14api-52280387Încă nu există evaluări
- 48th Junior State Aquatic Championships - 2Document8 pagini48th Junior State Aquatic Championships - 2victor_venki9955Încă nu există evaluări
- NotesDocument6 paginiNotesNiksÎncă nu există evaluări
- 07 Swimming SpeechDocument3 pagini07 Swimming SpeechBrittany AlbinÎncă nu există evaluări
- Taft "A" Swim Meet Fact SheetDocument3 paginiTaft "A" Swim Meet Fact SheetPatty Self TurpinÎncă nu există evaluări
- Basic Skills in Swimming: BackstrokeDocument18 paginiBasic Skills in Swimming: BackstrokeMourphie ReyesÎncă nu există evaluări
- Swimming: Event OverviewDocument19 paginiSwimming: Event Overviewمحمد آيسÎncă nu există evaluări
- 35.2. Ketentuan Master IOAC 2023Document6 pagini35.2. Ketentuan Master IOAC 2023misdar72Încă nu există evaluări
- Dominant Army Win National Swimming Titles - SportsDocument5 paginiDominant Army Win National Swimming Titles - SportsSaad Ul HaqÎncă nu există evaluări
- Bài Tập Trắc Nghiệm Anh 12- Chương Trình Thí ĐiểmDocument100 paginiBài Tập Trắc Nghiệm Anh 12- Chương Trình Thí ĐiểmNhư KhuêÎncă nu există evaluări
- Carifta Summons 2023 FINAL 28122022Document23 paginiCarifta Summons 2023 FINAL 28122022Charles McIntoshÎncă nu există evaluări
- IASAS Swimming Championship 2023 Full Result - CompressedDocument34 paginiIASAS Swimming Championship 2023 Full Result - Compressed71305Încă nu există evaluări
- 8230-Vivacity Swim School Brochure-AWDocument11 pagini8230-Vivacity Swim School Brochure-AWRohan RepaleÎncă nu există evaluări