S-ar putea să vă placă și
- Attacking Problems in Logarithms and Exponential FunctionsDe la EverandAttacking Problems in Logarithms and Exponential FunctionsEvaluare: 5 din 5 stele5/5 (1)
- Measure Theory Notes Anwar KhanDocument171 paginiMeasure Theory Notes Anwar KhanAhsan HafeezÎncă nu există evaluări
- Solutions HatcherDocument33 paginiSolutions HatcherAnonymous AtcM8k5J100% (1)
- Lec 1Document21 paginiLec 1Arshad AliÎncă nu există evaluări
- KL TransformDocument22 paginiKL TransformPrasanna Kumar Kottakota100% (1)
- Dynamic Response For Continuous SystemsDocument18 paginiDynamic Response For Continuous SystemsDarsHan MoHan0% (1)
- Lec 15Document15 paginiLec 15daynongÎncă nu există evaluări
- Lec 3Document28 paginiLec 3abimanaÎncă nu există evaluări
- Dynamics of Machines Prof. Amitabha Ghosh Indian Institute of Technology, KanpurDocument12 paginiDynamics of Machines Prof. Amitabha Ghosh Indian Institute of Technology, KanpurIshu GoelÎncă nu există evaluări
- Lec 5Document24 paginiLec 5PRAKASH K MÎncă nu există evaluări
- Finite Element Method Mod-1 Lec-3Document28 paginiFinite Element Method Mod-1 Lec-3PSINGH02Încă nu există evaluări
- Lec 5Document33 paginiLec 5shipraÎncă nu există evaluări
- Advanced Mathematical Techniques in Chemical Engineering Prof. S. de Department of Chemical Engineering Indian Institute of Technology, KharagpurDocument23 paginiAdvanced Mathematical Techniques in Chemical Engineering Prof. S. de Department of Chemical Engineering Indian Institute of Technology, KharagpurGaurav KumarÎncă nu există evaluări
- NPTEL FEM Lec3Document42 paginiNPTEL FEM Lec3EliÎncă nu există evaluări
- Lec6 PDFDocument23 paginiLec6 PDFKoteswaraRaoBÎncă nu există evaluări
- Finite Element Method Prof C. S. Upadhyay Department of Mechanical EngineeringDocument27 paginiFinite Element Method Prof C. S. Upadhyay Department of Mechanical EngineeringabimanaÎncă nu există evaluări
- Introduction To Finite Element Method Dr. R. Krishnakumar Department of Mechanical Engineering Indian Institute of Technology, Madras Lecture - 29Document30 paginiIntroduction To Finite Element Method Dr. R. Krishnakumar Department of Mechanical Engineering Indian Institute of Technology, Madras Lecture - 29mahendranÎncă nu există evaluări
- Lec13 PDFDocument15 paginiLec13 PDFJithinÎncă nu există evaluări
- Lec 21Document19 paginiLec 21Soumyadeep BoseÎncă nu există evaluări
- Lec 22Document15 paginiLec 22shailiayushÎncă nu există evaluări
- Lec 1Document48 paginiLec 1aravinda reddyÎncă nu există evaluări
- Lec 10Document36 paginiLec 10vidhya dsÎncă nu există evaluări
- Lec20 PDFDocument24 paginiLec20 PDFmahendranÎncă nu există evaluări
- Lec 31Document23 paginiLec 31rajÎncă nu există evaluări
- Kenirose A. (NUMBER THEORY)Document4 paginiKenirose A. (NUMBER THEORY)Dock AceÎncă nu există evaluări
- Lec 15Document17 paginiLec 15shashankÎncă nu există evaluări
- Advanced Problem Solving Lecture Notes and Problem Sets: Peter Hästö Torbjörn Helvik Eugenia MalinnikovaDocument35 paginiAdvanced Problem Solving Lecture Notes and Problem Sets: Peter Hästö Torbjörn Helvik Eugenia Malinnikovaసతీష్ కుమార్Încă nu există evaluări
- Dynamics of Machines Prof - Amitabha Ghosh Department of Mechanical Engineering Indian Institute of Technology, KanpurDocument16 paginiDynamics of Machines Prof - Amitabha Ghosh Department of Mechanical Engineering Indian Institute of Technology, KanpurIshu GoelÎncă nu există evaluări
- MITOCW - MITRES2 - 002s10linear - Lec11 - 300k-mp4: ProfessorDocument18 paginiMITOCW - MITRES2 - 002s10linear - Lec11 - 300k-mp4: ProfessorDanielÎncă nu există evaluări
- Lec 6Document20 paginiLec 6ዘረአዳም ዘመንቆረርÎncă nu există evaluări
- Lec 11Document18 paginiLec 11susovon mondalÎncă nu există evaluări
- Basic Quantum Mechanics Prof. Ajoy Ghatak Department of Physics Indian Institute of Technology, DelhiDocument22 paginiBasic Quantum Mechanics Prof. Ajoy Ghatak Department of Physics Indian Institute of Technology, DelhiUnknown 123Încă nu există evaluări
- Lec 1Document20 paginiLec 1shankyforuÎncă nu există evaluări
- Radioactive DecayDocument16 paginiRadioactive DecaySagar AliÎncă nu există evaluări
- Lec 43Document10 paginiLec 43sixfacerajÎncă nu există evaluări
- Advanced Operations Research Prof. G. Srinivasan Department of Management Studies Indian Institute of Technology, MadrasDocument20 paginiAdvanced Operations Research Prof. G. Srinivasan Department of Management Studies Indian Institute of Technology, Madrasammar sangeÎncă nu există evaluări
- Water Resources Systems Modeling Techniques and Analysis Prof. P.P. Mujumdar Department of Civil EngineeringDocument24 paginiWater Resources Systems Modeling Techniques and Analysis Prof. P.P. Mujumdar Department of Civil EngineeringAakash KamthaneÎncă nu există evaluări
- Dynamics of MachinesDocument14 paginiDynamics of MachinesIshu GoelÎncă nu există evaluări
- Finite Element Analysis Prof. Dr.B.N.Rao Department of Civil Engineering Indian Institute of Technology, MadrasDocument35 paginiFinite Element Analysis Prof. Dr.B.N.Rao Department of Civil Engineering Indian Institute of Technology, Madrasshrikant belsareÎncă nu există evaluări
- Lec 35Document18 paginiLec 35Win Alfalah NasutionÎncă nu există evaluări
- Lec18 3 PDFDocument8 paginiLec18 3 PDFDharmendra JainÎncă nu există evaluări
- Finite Element Analysis Prof. Dr. B. N. Rao Department of Civil Engineering Indian Institute of Technology, MadrasDocument40 paginiFinite Element Analysis Prof. Dr. B. N. Rao Department of Civil Engineering Indian Institute of Technology, MadrasMarijaÎncă nu există evaluări
- Functional Analysis Prof. P. D. Srivastava Department of Mathematics Indian Institute of Technology, KharagpurDocument15 paginiFunctional Analysis Prof. P. D. Srivastava Department of Mathematics Indian Institute of Technology, KharagpurKofi Appiah-DanquahÎncă nu există evaluări
- QdbkvD4N UsDocument17 paginiQdbkvD4N UsTheoÎncă nu există evaluări
- Lec 5Document23 paginiLec 5abimanaÎncă nu există evaluări
- Lec14 PDFDocument21 paginiLec14 PDFAbhishek AroraÎncă nu există evaluări
- Lecture 10 - Basic TransformDocument27 paginiLecture 10 - Basic TransformvespubekÎncă nu există evaluări
- MITOCW - MITRES2 - 002s10linear - Lec12 - 300k-mp4: ProfessorDocument21 paginiMITOCW - MITRES2 - 002s10linear - Lec12 - 300k-mp4: ProfessorDanielÎncă nu există evaluări
- Computational Fluid Dynamics Prof. Dr. Suman Chakraborty Department of Mechanical Engineering Indian Institute of Technology, KharagpurDocument18 paginiComputational Fluid Dynamics Prof. Dr. Suman Chakraborty Department of Mechanical Engineering Indian Institute of Technology, Kharagpurk krishna chaitanyaÎncă nu există evaluări
- OijadinDocument29 paginiOijadinbbot909Încă nu există evaluări
- Lec 38Document31 paginiLec 38Hiroshimay HimsimÎncă nu există evaluări
- Classical Physics Prof. V. Balakrishnan Department of Physics Indian Institute of Technology, Madras Lecture No. # 12Document25 paginiClassical Physics Prof. V. Balakrishnan Department of Physics Indian Institute of Technology, Madras Lecture No. # 12Souvik NaskarÎncă nu există evaluări
- Finite Element Method Prof. C. S. Upadhyay Department of Mechanical Engineering Indian Institute of Technology, KanpurDocument24 paginiFinite Element Method Prof. C. S. Upadhyay Department of Mechanical Engineering Indian Institute of Technology, KanpurabimanaÎncă nu există evaluări
- Lec 9Document10 paginiLec 9Rajendra singhÎncă nu există evaluări
- Classical Mechanics: From Newtonian To Lagrangian FormulationDocument9 paginiClassical Mechanics: From Newtonian To Lagrangian Formulationchirag jainÎncă nu există evaluări
- IntegrationDocument10 paginiIntegrationProsper DibakoaneÎncă nu există evaluări
- Statics and Dynamics Dr. Mahesh V. Panchagnula Department of Applied Mechanics Indian Institute of Technology, Madras Lecture - 33Document9 paginiStatics and Dynamics Dr. Mahesh V. Panchagnula Department of Applied Mechanics Indian Institute of Technology, Madras Lecture - 33Dharmendra JainÎncă nu există evaluări
- Computational Techniques Prof. Dr. Niket Kaisare Department of Chemical Engineering Indian Institute of Technology, MadrasDocument30 paginiComputational Techniques Prof. Dr. Niket Kaisare Department of Chemical Engineering Indian Institute of Technology, MadrasjagaenatorÎncă nu există evaluări
- Advanced Engineering Mathematics Prof. Pratima Panigrahi Department of Mathematics Indian Institute of Technology, KharagpurDocument15 paginiAdvanced Engineering Mathematics Prof. Pratima Panigrahi Department of Mathematics Indian Institute of Technology, Kharagpurpatel gauravÎncă nu există evaluări
- Agm5 Qualification Editorial-1Document10 paginiAgm5 Qualification Editorial-1Matei HabaÎncă nu există evaluări
- Instructor (Brad Osgood) :hey. Jesus. Man, I Just Back and I'm Tired. and WelcomeDocument11 paginiInstructor (Brad Osgood) :hey. Jesus. Man, I Just Back and I'm Tired. and WelcomeElisée NdjabuÎncă nu există evaluări
- Lec 5Document29 paginiLec 5Win Alfalah NasutionÎncă nu există evaluări
- Lec 12Document34 paginiLec 12Arshad AliÎncă nu există evaluări
- Prof. Bart de Moor (KUL) Chapter 13: PID ControllersDocument36 paginiProf. Bart de Moor (KUL) Chapter 13: PID ControllersArshad AliÎncă nu există evaluări
- KPK SST PD PDFDocument1 paginăKPK SST PD PDFArshad AliÎncă nu există evaluări
- Lec 7Document26 paginiLec 7Arshad AliÎncă nu există evaluări
- Lec 9Document27 paginiLec 9Arshad AliÎncă nu există evaluări
- Letter Medical Examination MSDocument18 paginiLetter Medical Examination MSArshad AliÎncă nu există evaluări
- Sensorcomm 2014 1 50 10062kbDocument6 paginiSensorcomm 2014 1 50 10062kbArshad AliÎncă nu există evaluări
- S.No Speed (Volatge) V Brake Position: Experimentnt #04Document3 paginiS.No Speed (Volatge) V Brake Position: Experimentnt #04Arshad AliÎncă nu există evaluări
- S.No Speed (Volatge) V Attenuator Position: Experiment #2Document3 paginiS.No Speed (Volatge) V Attenuator Position: Experiment #2Arshad AliÎncă nu există evaluări
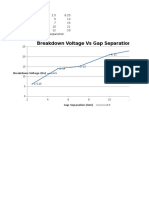
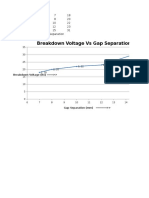
- Experiment #1 2.5 6.25 5 14 7 15 10 21 12 23 Breakdown Voltage Vs Gap SeparationDocument3 paginiExperiment #1 2.5 6.25 5 14 7 15 10 21 12 23 Breakdown Voltage Vs Gap SeparationArshad AliÎncă nu există evaluări
- Transformer Oil TestDocument3 paginiTransformer Oil TestArshad AliÎncă nu există evaluări
- Lec13 2Document25 paginiLec13 2Arshad AliÎncă nu există evaluări
- MatrixDocument26 paginiMatrixBattleBeex rabinoÎncă nu există evaluări
- Complex Analysis Four 2Document7 paginiComplex Analysis Four 2Manoj Kumar YennapureddyÎncă nu există evaluări
- Calculus 1 - Differentiation and Integration-Sanet - ST PDFDocument490 paginiCalculus 1 - Differentiation and Integration-Sanet - ST PDFAndrés Aldana AnzolaÎncă nu există evaluări
- Veer Surendra Sai University of Technology, BurlaDocument2 paginiVeer Surendra Sai University of Technology, Burlasanthi saranyaÎncă nu există evaluări
- MTH 121 Comp - Engr, Elect, W&F, Mech Engr CalculusDocument2 paginiMTH 121 Comp - Engr, Elect, W&F, Mech Engr CalculusPsalmuel Victor AloÎncă nu există evaluări
- Finite Element Programming With MATLAB: 12.1 Using MATLAB For FEMDocument33 paginiFinite Element Programming With MATLAB: 12.1 Using MATLAB For FEM436MD siribindooÎncă nu există evaluări
- University of Zimbabwe MT104 Question PaperDocument4 paginiUniversity of Zimbabwe MT104 Question PaperHuggins ChigidhaniÎncă nu există evaluări
- Convolutions of Complex Exponential FunctionsDocument6 paginiConvolutions of Complex Exponential FunctionschandanaÎncă nu există evaluări
- 01 TrabajoDocument18 pagini01 TrabajoYuliza Carolina Capuñay SiesquenÎncă nu există evaluări
- Formulario Calculo Dif - IntegralDocument4 paginiFormulario Calculo Dif - IntegralRocki R SebastiánÎncă nu există evaluări
- SPPHomotopietheorieDocument40 paginiSPPHomotopietheorieWalter Andrés Páez GaviriaÎncă nu există evaluări
- Analysis II MS Sol 2015-16Document3 paginiAnalysis II MS Sol 2015-16Mainak SamantaÎncă nu există evaluări
- Algebraic Equations PDFDocument56 paginiAlgebraic Equations PDFAnonymous LLsXddLvtmÎncă nu există evaluări
- Determinants - Ch. 2.1, 2.2, 2.3, 2.4, 2.5Document52 paginiDeterminants - Ch. 2.1, 2.2, 2.3, 2.4, 2.5Bryan PenfoundÎncă nu există evaluări
- M3 R08 NovDec 09Document3 paginiM3 R08 NovDec 09creativeÎncă nu există evaluări
- What Are Operator Spaces?Document77 paginiWhat Are Operator Spaces?Chowdaiah100% (2)
- Limits and ContinuityDocument9 paginiLimits and ContinuityClarenzÎncă nu există evaluări
- Ss Jntuk Dec 2015Document4 paginiSs Jntuk Dec 2015giribabukandeÎncă nu există evaluări
- 6.3.3 QR Matlab 25sep2021Document8 pagini6.3.3 QR Matlab 25sep2021mohor.banerjeeÎncă nu există evaluări
- Numerical & Statistical ComputationsDocument24 paginiNumerical & Statistical Computationsabhishek125Încă nu există evaluări
- +1 Chap All em PvmhssDocument113 pagini+1 Chap All em PvmhssSean SheltonÎncă nu există evaluări
- MA3151 Matrices and Calculus Question Bank 1Document5 paginiMA3151 Matrices and Calculus Question Bank 1VIGNESH VASUÎncă nu există evaluări
- (English) Basic Trigonometry - Sin Cos Tan (NancyPi) (DownSub - Com)Document6 pagini(English) Basic Trigonometry - Sin Cos Tan (NancyPi) (DownSub - Com)Jisoo KimÎncă nu există evaluări
- Matrix linearALGEBDocument49 paginiMatrix linearALGEBLeah lyn LeanilloÎncă nu există evaluări
- Yfx - TN: y FlatsDocument36 paginiYfx - TN: y FlatsbabaÎncă nu există evaluări
- 9 Two Variable OptimizationDocument10 pagini9 Two Variable OptimizationBella NovitasariÎncă nu există evaluări
- Mat127b HW 0129Document9 paginiMat127b HW 0129WALYS VERA HERRERAÎncă nu există evaluări