S-ar putea să vă placă și
- Mastering Linux Kernel DevelopmentDocument346 paginiMastering Linux Kernel Developmentatom tux100% (2)
- Ms Word McqsDocument12 paginiMs Word McqsUraiBa AnsaRi0% (1)
- OHS Policies and Guidelines (TESDA CSS NC2 COC1)Document1 paginăOHS Policies and Guidelines (TESDA CSS NC2 COC1)Anonymous fvY2BzPQVx100% (2)
- Probability For PhysicistsDocument415 paginiProbability For Physicistsatom tux100% (1)
- Cognitive Dynamic Systems - Simon HaykinDocument320 paginiCognitive Dynamic Systems - Simon Haykinatom tuxÎncă nu există evaluări
- Wulfram Gerstner, Werner M. Kistler, Richard Naud, Liam Paninski-Neuronal Dynamics - From Single Neurons To Networks and Models of Cognition-Cambridge University Press (2014)Document590 paginiWulfram Gerstner, Werner M. Kistler, Richard Naud, Liam Paninski-Neuronal Dynamics - From Single Neurons To Networks and Models of Cognition-Cambridge University Press (2014)Mariano Uria100% (1)
- Augmented Reality in Logistics: Changing How We See OperationsDocument28 paginiAugmented Reality in Logistics: Changing How We See OperationsApoorv GuptaÎncă nu există evaluări
- Electrical Engineering and Computer Science Department: Chip Multiprocessor Cooperative Cache Compression and MigrationDocument23 paginiElectrical Engineering and Computer Science Department: Chip Multiprocessor Cooperative Cache Compression and Migrationeecs.northwestern.eduÎncă nu există evaluări
- Approximate NoC and Memory Controller Architectures for GPGPU AcceleratorsDocument15 paginiApproximate NoC and Memory Controller Architectures for GPGPU AcceleratorsMiguel Ramírez CarrilloÎncă nu există evaluări
- Large Graph Algorithms on Massively Multithreaded GPU ArchitecturesDocument26 paginiLarge Graph Algorithms on Massively Multithreaded GPU Architecturesgorot1Încă nu există evaluări
- Research Article: Memory Map: A Multiprocessor Cache SimulatorDocument13 paginiResearch Article: Memory Map: A Multiprocessor Cache SimulatorMuhammad Tehseen KhanÎncă nu există evaluări
- Cpu Gpu SystemDocument26 paginiCpu Gpu SystemsadikÎncă nu există evaluări
- The Curious Case of Container Orchestration and Scheduling in GPU-based DatacentersDocument1 paginăThe Curious Case of Container Orchestration and Scheduling in GPU-based DatacentersIshak HariÎncă nu există evaluări
- Unit I: Cloud Architecture and ModelDocument14 paginiUnit I: Cloud Architecture and ModelVarunÎncă nu există evaluări
- Datacenter Storage Architecture For Mapreduce Applications: Jeffrey Shafer, Scott Rixner, Alan L. Cox Rice UniversityDocument3 paginiDatacenter Storage Architecture For Mapreduce Applications: Jeffrey Shafer, Scott Rixner, Alan L. Cox Rice Universityhamidsa81Încă nu există evaluări
- Technologies For NetworkDocument3 paginiTechnologies For NetworkChristopher DiazÎncă nu există evaluări
- MRPB: Memory Request Prioritization For Massively Parallel ProcessorsDocument12 paginiMRPB: Memory Request Prioritization For Massively Parallel ProcessorsNishant PanigrahiÎncă nu există evaluări
- Tesseract Pim Architecture For Graph Processing - Isca15Document13 paginiTesseract Pim Architecture For Graph Processing - Isca15Megha JoshiÎncă nu există evaluări
- CA Assignment #2Document3 paginiCA Assignment #2Chachu-420Încă nu există evaluări
- Week 5 - The Impact of Multi-Core Computing On Computational OptimizationDocument11 paginiWeek 5 - The Impact of Multi-Core Computing On Computational OptimizationGame AccountÎncă nu există evaluări
- Computer cluster computing explainedDocument5 paginiComputer cluster computing explainedshaheen sayyad 463Încă nu există evaluări
- Hierarchical Cache / Bus Architecture For Shared Memory MultiprocessorsDocument9 paginiHierarchical Cache / Bus Architecture For Shared Memory MultiprocessorsPralhadrao sÎncă nu există evaluări
- Research and Realization of Reflective Memory Network: 1. AbstractDocument56 paginiResearch and Realization of Reflective Memory Network: 1. AbstractAtul KumbharÎncă nu există evaluări
- Rapid Memory-Aware Selection of Hardware Accelerators in Programmable Soc DesignDocument12 paginiRapid Memory-Aware Selection of Hardware Accelerators in Programmable Soc DesignBanusha chandranÎncă nu există evaluări
- On-Chip vs. Off-Chip Memory - PandaDocument23 paginiOn-Chip vs. Off-Chip Memory - Pandasarathkumar3389Încă nu există evaluări
- C R A M: Ompression For EAL Time Pplications EdiaDocument4 paginiC R A M: Ompression For EAL Time Pplications EdiaJair Vasquez RiosÎncă nu există evaluări
- Dynamic, Multi-Core Cache Coherence Architecture For Power-Sensitive Mobile ProcessorsDocument9 paginiDynamic, Multi-Core Cache Coherence Architecture For Power-Sensitive Mobile ProcessorsJoshua David SerraoÎncă nu există evaluări
- Design and implementation of the memory management unit (MMU) of a 32-bit micro-controller; split cache of 32/32kByte; 4-way set-associative, LFU, Write-Through / Write-Allocate. With an ARM926EJ-S with 1GHz clock speed of unlimited main memory with a clock of 10MHz.Document19 paginiDesign and implementation of the memory management unit (MMU) of a 32-bit micro-controller; split cache of 32/32kByte; 4-way set-associative, LFU, Write-Through / Write-Allocate. With an ARM926EJ-S with 1GHz clock speed of unlimited main memory with a clock of 10MHz.Muhammad Umair SaleemÎncă nu există evaluări
- Large-Scale Graph Processing On Commodity Systems: Understanding and Mitigating The Impact of SwappingDocument11 paginiLarge-Scale Graph Processing On Commodity Systems: Understanding and Mitigating The Impact of SwappingSudip DasÎncă nu există evaluări
- Research Project Mayormente - MarvinDocument11 paginiResearch Project Mayormente - MarvinMarvin MayormenteÎncă nu există evaluări
- Week - 01 - Lec1 03 03 2021Document19 paginiWeek - 01 - Lec1 03 03 2021Zainab ShahzadÎncă nu există evaluări
- Cache CoherencyDocument19 paginiCache Coherencysruthi.attineniÎncă nu există evaluări
- Dagatan Nino PRDocument12 paginiDagatan Nino PRdagatan.ninoÎncă nu există evaluări
- Lec2 ParallelProgrammingPlatformsDocument26 paginiLec2 ParallelProgrammingPlatformsSAIÎncă nu există evaluări
- Scheduling Threads For Constructive Cache Sharing On CmpsDocument11 paginiScheduling Threads For Constructive Cache Sharing On CmpsAnonymous RrGVQjÎncă nu există evaluări
- From Reconfigurable Architectures To Self-Adaptive Autonomic SystemsDocument7 paginiFrom Reconfigurable Architectures To Self-Adaptive Autonomic SystemsLucas Gabriel CasagrandeÎncă nu există evaluări
- Data Placement and Duplication For Embedded Multicore Systems With Scratch Pad MemoryDocument9 paginiData Placement and Duplication For Embedded Multicore Systems With Scratch Pad MemoryAjay TaradeÎncă nu există evaluări
- Computer96 PsDocument26 paginiComputer96 PsDom DeSiciliaÎncă nu există evaluări
- Evaluating Stream Buffers As A Secondary Cache ReplacementDocument10 paginiEvaluating Stream Buffers As A Secondary Cache ReplacementVicent Selfa OliverÎncă nu există evaluări
- Asplos 2000Document12 paginiAsplos 2000Alexandru BOSS ROÎncă nu există evaluări
- A Taxonomy of Distributed SystemsDocument11 paginiA Taxonomy of Distributed SystemssdfjsdsdvÎncă nu există evaluări
- Rubio Campillo2018Document3 paginiRubio Campillo2018AimanÎncă nu există evaluări
- GPU QuicksortDocument22 paginiGPU QuicksortKriti JhaÎncă nu există evaluări
- Data Similarity-Aware Computation Infrastructure For The CloudDocument14 paginiData Similarity-Aware Computation Infrastructure For The CloudAjay TaradeÎncă nu există evaluări
- Nvidia Magnum Io Gpudirect Storage Overview Guide: 1.1. Related DocumentsDocument22 paginiNvidia Magnum Io Gpudirect Storage Overview Guide: 1.1. Related DocumentsNan_KingyjÎncă nu există evaluări
- 2019 - Scalable - Hardware-Based - On-Board - Processing - For - Run-Time - Adaptive - Lossless - Hyperspectral - CompressionDocument9 pagini2019 - Scalable - Hardware-Based - On-Board - Processing - For - Run-Time - Adaptive - Lossless - Hyperspectral - CompressionSaru 2002Încă nu există evaluări
- Reuse and Refactoring of GPU Kernels To Design Complex ApplicationsDocument8 paginiReuse and Refactoring of GPU Kernels To Design Complex Applicationsshubh9190Încă nu există evaluări
- Optimized Memory Allocation and Power Minimization For FPGA-Based Image ProcessingDocument23 paginiOptimized Memory Allocation and Power Minimization For FPGA-Based Image ProcessingAl-Ami SarkerÎncă nu există evaluări
- Hardware Memory Management For Future Mobile Hybrid Memory SystemsDocument11 paginiHardware Memory Management For Future Mobile Hybrid Memory SystemsMansoor GoharÎncă nu există evaluări
- DMR3D: Dynamic Memory Relocation in 3D Multicore Systems: Dean Michael Ancajas Koushik Chakraborty Sanghamitra RoyDocument9 paginiDMR3D: Dynamic Memory Relocation in 3D Multicore Systems: Dean Michael Ancajas Koushik Chakraborty Sanghamitra RoyDean Michael B AncajasÎncă nu există evaluări
- Multicore FpgaDocument1 paginăMulticore Fpgateja_p96Încă nu există evaluări
- Sparse Matrix-Matrix Multiplication On Multilevel Memory Architectures: Algorithms and ExperimentsDocument24 paginiSparse Matrix-Matrix Multiplication On Multilevel Memory Architectures: Algorithms and ExperimentsСтас МережкоÎncă nu există evaluări
- Lectures on distributed systems introductionDocument8 paginiLectures on distributed systems introductionaj54321Încă nu există evaluări
- MESI protocol for multicore processors based on FPGADocument10 paginiMESI protocol for multicore processors based on FPGAunÎncă nu există evaluări
- Efficient Datapath Merging For Partially Reconfigurable ArchitecturesDocument12 paginiEfficient Datapath Merging For Partially Reconfigurable ArchitecturesHacı AxundzadəÎncă nu există evaluări
- A Hardware/Software Framework For Supporting Transactional Memory in A Mpsoc EnvironmentDocument8 paginiA Hardware/Software Framework For Supporting Transactional Memory in A Mpsoc Environmentvijaypraveen1986Încă nu există evaluări
- MEMMU: Memory Expansion For MMU-Less Embedded Systems: Lan S. Bai, Lei Yang, and Robert P. Dick Northwestern UniversityDocument33 paginiMEMMU: Memory Expansion For MMU-Less Embedded Systems: Lan S. Bai, Lei Yang, and Robert P. Dick Northwestern Universitykenny ChouÎncă nu există evaluări
- A Programming Model For Massive Data Parallelism With Data DependenciesDocument8 paginiA Programming Model For Massive Data Parallelism With Data Dependenciesweb1_webteamÎncă nu există evaluări
- Research Article: Hybrid MPI and CUDA Parallelization For CFD Applications On Multi-GPU HPC ClustersDocument15 paginiResearch Article: Hybrid MPI and CUDA Parallelization For CFD Applications On Multi-GPU HPC Clusterszhaojie qinÎncă nu există evaluări
- Mosc I BrodaDocument18 paginiMosc I BrodajackienessÎncă nu există evaluări
- Storegpu: Exploiting Graphics Processing Units To Accelerate Distributed Storage SystemsDocument10 paginiStoregpu: Exploiting Graphics Processing Units To Accelerate Distributed Storage SystemsMichael FairchildÎncă nu există evaluări
- Designing Efficient Sorting Algorithms For Manycore Gpus: NtroductionDocument10 paginiDesigning Efficient Sorting Algorithms For Manycore Gpus: NtroductionaruishawgÎncă nu există evaluări
- Compute Cores WhitepaperDocument6 paginiCompute Cores WhitepaperFarhanÎncă nu există evaluări
- Taxonomy of Parallel Computing ParadigmsDocument9 paginiTaxonomy of Parallel Computing ParadigmssushmaÎncă nu există evaluări
- Hyaline framework distributes CUDA tasksDocument8 paginiHyaline framework distributes CUDA tasksyogeshÎncă nu există evaluări
- Nvidia DGX-1Document2 paginiNvidia DGX-1atom tuxÎncă nu există evaluări
- TangoDocument12 paginiTangoatom tuxÎncă nu există evaluări
- Augmented RealityDocument9 paginiAugmented RealitySadhanaSinghÎncă nu există evaluări
- dgx1 PDFDocument2 paginidgx1 PDFatom tuxÎncă nu există evaluări
- TangoDocument4 paginiTangoatom tuxÎncă nu există evaluări
- Nvidia DGX-1Document24 paginiNvidia DGX-1atom tuxÎncă nu există evaluări
- Project Tango: Adding Quality Interoperability To The Metro Web Services StackDocument26 paginiProject Tango: Adding Quality Interoperability To The Metro Web Services StackmaratisÎncă nu există evaluări
- Tango PDFDocument9 paginiTango PDFatom tuxÎncă nu există evaluări
- Project Ara: Redefining Handset and Android ArchitectureDocument41 paginiProject Ara: Redefining Handset and Android ArchitecturejoelÎncă nu există evaluări
- Mixed RealityDocument8 paginiMixed Realityatom tuxÎncă nu există evaluări
- Ara PDFDocument33 paginiAra PDFatom tuxÎncă nu există evaluări
- Mixed RealityDocument12 paginiMixed Realityatom tuxÎncă nu există evaluări
- Mixed RealityDocument7 paginiMixed Realityatom tuxÎncă nu există evaluări
- Project Ara: Redefining Handset and Android ArchitectureDocument41 paginiProject Ara: Redefining Handset and Android ArchitecturejoelÎncă nu există evaluări
- Mixed Reality PDFDocument6 paginiMixed Reality PDFatom tuxÎncă nu există evaluări
- Mixed RealityDocument8 paginiMixed Realityatom tuxÎncă nu există evaluări
- Mixed Reality PDFDocument8 paginiMixed Reality PDFatom tuxÎncă nu există evaluări
- Mixed RealityDocument14 paginiMixed Realityatom tuxÎncă nu există evaluări
- Mixed RealityDocument21 paginiMixed Realityatom tuxÎncă nu există evaluări
- Reality TechDocument68 paginiReality Techakbar_birbal887Încă nu există evaluări
- Mixed Reality PDFDocument6 paginiMixed Reality PDFatom tuxÎncă nu există evaluări
- Mixed RealityDocument2 paginiMixed Realityatom tuxÎncă nu există evaluări
- Mixed RealityDocument15 paginiMixed Realityatom tuxÎncă nu există evaluări
- Mixed Reality PDFDocument5 paginiMixed Reality PDFatom tuxÎncă nu există evaluări
- Design and Evaluation of a Mixed Reality Racing Game PrototypeDocument7 paginiDesign and Evaluation of a Mixed Reality Racing Game Prototypeatom tuxÎncă nu există evaluări
- Katie Nelson PDFDocument3 paginiKatie Nelson PDFKatie NÎncă nu există evaluări
- Academic SummaryDocument4 paginiAcademic SummaryJacqui PendergastÎncă nu există evaluări
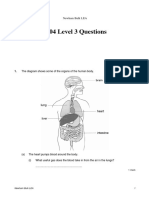
- 2004 Level 3 Questions: Newham Bulk LEADocument18 pagini2004 Level 3 Questions: Newham Bulk LEAPatience NgundeÎncă nu există evaluări
- AN-029Wired Locker Access Control ENDocument13 paginiAN-029Wired Locker Access Control ENpetar petrovicÎncă nu există evaluări
- English 9 - Q2 - M5Document16 paginiEnglish 9 - Q2 - M5myraÎncă nu există evaluări
- Anti Climbers FlyerDocument2 paginiAnti Climbers Flyeredark2009Încă nu există evaluări
- X English QPDocument29 paginiX English QPbadasserytechÎncă nu există evaluări
- Thrust Equation For A Turbofan Double Inlet/Outlet: Joshtheengineer April 8, 2017Document7 paginiThrust Equation For A Turbofan Double Inlet/Outlet: Joshtheengineer April 8, 2017Muhammad RidwanÎncă nu există evaluări
- Physics: PAPER 3 Practical Test InstructionsDocument8 paginiPhysics: PAPER 3 Practical Test Instructionsmstudy123456Încă nu există evaluări
- Despiece Des40330 Fagor Sr-23Document45 paginiDespiece Des40330 Fagor Sr-23Nữa Đi EmÎncă nu există evaluări
- Arrester Facts 004a - Externally Gapped ArresterDocument2 paginiArrester Facts 004a - Externally Gapped ArresterCbdtxd PcbtrÎncă nu există evaluări
- Systems ClassDocument53 paginiSystems ClassBhetariya PareshÎncă nu există evaluări
- ResearchDocument48 paginiResearchCai De JesusÎncă nu există evaluări
- 7 Robert Boyle and Experimental Methods: © 2004 Fiona KisbyDocument8 pagini7 Robert Boyle and Experimental Methods: © 2004 Fiona Kisbydaveseram1018Încă nu există evaluări
- Electrochemistry PD lab insightsDocument4 paginiElectrochemistry PD lab insightsEdilberto PerezÎncă nu există evaluări
- Advisory Note 11 ASFP Cell Beam RationaleDocument2 paginiAdvisory Note 11 ASFP Cell Beam RationalePavaloaie Marian ConstantinÎncă nu există evaluări
- Fuzzy Logic Tutorial: What Is, Application & ExampleDocument7 paginiFuzzy Logic Tutorial: What Is, Application & ExampleDe' LufiasÎncă nu există evaluări
- Daniel Kipkirong Tarus C.VDocument19 paginiDaniel Kipkirong Tarus C.VPeter Osundwa KitekiÎncă nu există evaluări
- Katalog - Bengkel Print Indonesia PDFDocument32 paginiKatalog - Bengkel Print Indonesia PDFJoko WaringinÎncă nu există evaluări
- Web 2.0, Web 3.0, and User Participation in The WebDocument13 paginiWeb 2.0, Web 3.0, and User Participation in The WebDina Navarro DiestroÎncă nu există evaluări
- Lind 18e Chap005Document35 paginiLind 18e Chap005MELLYANA JIEÎncă nu există evaluări
- Final AnswersDocument4 paginiFinal AnswersAnshul SinghÎncă nu există evaluări
- Chowringhee - (Iisco House) Concept Encapsulation Session: The Oldest FIITJEE Centre in KolkataDocument12 paginiChowringhee - (Iisco House) Concept Encapsulation Session: The Oldest FIITJEE Centre in KolkataHemendra PrasannaÎncă nu există evaluări
- Boyut AnaliziDocument65 paginiBoyut AnaliziHasan Kayhan KayadelenÎncă nu există evaluări
- MY LIFE VISION, MISSION AND CORE VALUES BMEC 2W 2122Document4 paginiMY LIFE VISION, MISSION AND CORE VALUES BMEC 2W 2122Nikolai Avery NorthÎncă nu există evaluări
- Mobil Dynagear Series Performance ProfileDocument2 paginiMobil Dynagear Series Performance ProfileXavier DiazÎncă nu există evaluări
- Particulate Contamination in Aviation Fuels by Laboratory FiltrationDocument11 paginiParticulate Contamination in Aviation Fuels by Laboratory FiltrationMuhammad KhairuddinÎncă nu există evaluări
- To Signals and SystemsDocument57 paginiTo Signals and SystemsMUHAMMAD HAFIZUDDINÎncă nu există evaluări