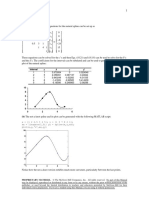
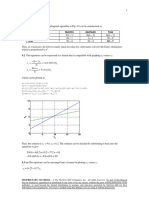
S-ar putea să vă placă și
- SM CH PDFDocument33 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument25 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument11 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument16 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument17 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument18 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument14 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument21 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument14 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument26 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument19 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument28 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument29 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument29 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument16 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument13 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument16 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument26 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument12 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument19 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument15 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument11 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument15 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- SM CH PDFDocument22 paginiSM CH PDFHector NaranjoÎncă nu există evaluări
- Westinghouse PWR ManualDocument245 paginiWestinghouse PWR ManualHector Naranjo100% (1)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (894)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Inflation and Economic Growth:: Threshold Effects and Transmission MechanismsDocument75 paginiInflation and Economic Growth:: Threshold Effects and Transmission MechanismsSya ZanaÎncă nu există evaluări
- Am (131-140) Analisis MultinivelDocument10 paginiAm (131-140) Analisis Multinivelmaximal25Încă nu există evaluări
- ES5 Estaistica 1Document4 paginiES5 Estaistica 1Leonardo NegreteÎncă nu există evaluări
- Introduction To Econometrics: Fourth Edition, Global EditionDocument43 paginiIntroduction To Econometrics: Fourth Edition, Global Edition김승희Încă nu există evaluări
- Effective Width Criteria For Composite BeamsDocument7 paginiEffective Width Criteria For Composite BeamsJoey JoejoeÎncă nu există evaluări
- Effects of Global Market Conditions On Brand Image Customization and Brand PerformanceDocument26 paginiEffects of Global Market Conditions On Brand Image Customization and Brand PerformancesweelaÎncă nu există evaluări
- International Journal of Africa Nursing Sciences: Bayisa Bereka Negussie, Gebisa Bayisa OliksaDocument6 paginiInternational Journal of Africa Nursing Sciences: Bayisa Bereka Negussie, Gebisa Bayisa OliksaRaissa NoorÎncă nu există evaluări
- Determinants of Work-Readiness: Siti Nurlaela Kurjono RastoDocument7 paginiDeterminants of Work-Readiness: Siti Nurlaela Kurjono RastojihanruhiatÎncă nu există evaluări
- Datamining Lecture6Document41 paginiDatamining Lecture6Vi LeÎncă nu există evaluări
- RM CiaDocument22 paginiRM CiaYATEE TRIVEDI 21111660Încă nu există evaluări
- Sbe9 TB16Document21 paginiSbe9 TB16Huong Tran50% (2)
- Overview of Methods For Voltage Sag Performance EstimationDocument5 paginiOverview of Methods For Voltage Sag Performance EstimationJay F. KuizonÎncă nu există evaluări
- T.Y.B.a. Economics SyllabusDocument9 paginiT.Y.B.a. Economics SyllabusTori Chakma DangkoÎncă nu există evaluări
- BBA Digital Marketing SchemeDocument100 paginiBBA Digital Marketing SchemeRAMESH KUMARÎncă nu există evaluări
- Data Driven Modelling Using MATLABDocument21 paginiData Driven Modelling Using MATLABhquynhÎncă nu există evaluări
- Jurnal Bakat MinatDocument5 paginiJurnal Bakat Minat072Awalina ridha nabilaÎncă nu există evaluări
- PLUM - Ordinal Regression: WarningsDocument3 paginiPLUM - Ordinal Regression: WarningsAnastasia WijayaÎncă nu există evaluări
- CS 229, Summer 2020 Problem Set #1Document14 paginiCS 229, Summer 2020 Problem Set #1nhungÎncă nu există evaluări
- Fortran Folheto V6Document83 paginiFortran Folheto V6Maurício Prado Martins0% (1)
- Pengaruh Budaya Organisasi Terhadap KineDocument14 paginiPengaruh Budaya Organisasi Terhadap KineDidik PrasetyaÎncă nu există evaluări
- Cfa Level 1 - Quantitative Review: Calculate Mean and Standard Deviation of Expected ReturnsDocument5 paginiCfa Level 1 - Quantitative Review: Calculate Mean and Standard Deviation of Expected ReturnsNoroÎncă nu există evaluări
- A Big Data Approach For Smart Transportation Management On Bus NetworkDocument6 paginiA Big Data Approach For Smart Transportation Management On Bus Networktra5cÎncă nu există evaluări
- Stats216 hw2Document21 paginiStats216 hw2Alex NutkiewiczÎncă nu există evaluări
- R D National College Mumbai University: On "House Price Prediction System"Document14 paginiR D National College Mumbai University: On "House Price Prediction System"Simran SolankiÎncă nu există evaluări
- BCA SEM-3 (Syallabus)Document17 paginiBCA SEM-3 (Syallabus)Depple TestÎncă nu există evaluări
- Production Planning and Inventory Control Final ReportDocument552 paginiProduction Planning and Inventory Control Final Reportsarmadi simbolonÎncă nu există evaluări
- The Impact of Macroeconomic Variables On PDFDocument16 paginiThe Impact of Macroeconomic Variables On PDFTouseefÎncă nu există evaluări
- Econometrics IIDocument101 paginiEconometrics IIDENEKEW LESEMI100% (1)
- Stephen Klosterman - Data Science Projects With Python - A Case Study Approach To Successful Data Science Projects Using Python, Pandas, and Scikit-Learn (2019)Document374 paginiStephen Klosterman - Data Science Projects With Python - A Case Study Approach To Successful Data Science Projects Using Python, Pandas, and Scikit-Learn (2019)NIKHIL WAKODE100% (1)
- Cost Accounting Ch03Document86 paginiCost Accounting Ch03michaelwainsteinÎncă nu există evaluări