S-ar putea să vă placă și
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5795)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- National University of Science and Technology: Digital System Design (EE-421) Assignment #1Document23 paginiNational University of Science and Technology: Digital System Design (EE-421) Assignment #1Tariq UmarÎncă nu există evaluări
- FIFO Depth Calculation .: FRIDAY, MAY 30, 2008Document6 paginiFIFO Depth Calculation .: FRIDAY, MAY 30, 2008Lee SubiramaniyamÎncă nu există evaluări
- 5722 PG101 RDocument593 pagini5722 PG101 RSuperhaiÎncă nu există evaluări
- Community CloudDocument3 paginiCommunity Cloudshaheenashahbas476Încă nu există evaluări
- CS7103 - MultiCore Architecture Ppts Unit-IIDocument43 paginiCS7103 - MultiCore Architecture Ppts Unit-IISuryaÎncă nu există evaluări
- PC Check Classic ManualDocument120 paginiPC Check Classic Manualheliosjunior219126Încă nu există evaluări
- DSView 3 Management SoftwareDocument2 paginiDSView 3 Management SoftwarekamelfarajeÎncă nu există evaluări
- Computer Networks LabDocument52 paginiComputer Networks LabAV VÎncă nu există evaluări
- Unit 2 - Number System NotesDocument25 paginiUnit 2 - Number System NotesUtpal KantÎncă nu există evaluări
- Failed To Connect - Org - Bluez.error - Failed - Raspberry Pi Forums PDFDocument13 paginiFailed To Connect - Org - Bluez.error - Failed - Raspberry Pi Forums PDFagusuripÎncă nu există evaluări
- MobaXterm LUR-172.30.130.60 20221219 094102Document12 paginiMobaXterm LUR-172.30.130.60 20221219 094102Juan HurtadoÎncă nu există evaluări
- EE371-Microprocessor Systems Fall2014 PDFDocument2 paginiEE371-Microprocessor Systems Fall2014 PDFShahid ButtÎncă nu există evaluări
- Brochure Vlsi DesignDocument2 paginiBrochure Vlsi DesignAshlin AarthiÎncă nu există evaluări
- EE221 Lecture 39 42Document41 paginiEE221 Lecture 39 42sayed Tamir janÎncă nu există evaluări
- Overview of Weblogic ServerDocument4 paginiOverview of Weblogic ServerresiddiquiÎncă nu există evaluări
- EM277 Hardware PDFDocument12 paginiEM277 Hardware PDFNguyễn Bình TrọngÎncă nu există evaluări
- HP Compaq Consumer Desktop & Laptop Price List - 5th Mar'11Document2 paginiHP Compaq Consumer Desktop & Laptop Price List - 5th Mar'11Siva KanthanÎncă nu există evaluări
- AlarmmDocument53 paginiAlarmmZul Andri MuqodamÎncă nu există evaluări
- Products & Services: MPLS ServiceDocument7 paginiProducts & Services: MPLS ServiceAju JamesÎncă nu există evaluări
- CBM209X Flash Support List (2011!04!28)Document9 paginiCBM209X Flash Support List (2011!04!28)ayendesÎncă nu există evaluări
- KES Application ManagementDocument16 paginiKES Application ManagementSol GÎncă nu există evaluări
- Infosys Interview AZURE QuestionsDocument3 paginiInfosys Interview AZURE Questionsrajuravi10Încă nu există evaluări
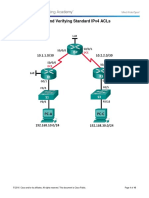
- TP6-7.2.2.6 Lab - Configuring and Modifying Standard IPv4 ACLsDocument10 paginiTP6-7.2.2.6 Lab - Configuring and Modifying Standard IPv4 ACLsDarine Dadou0% (1)
- SSM SecurityDocument218 paginiSSM SecurityMarco H DelgadilloÎncă nu există evaluări
- Manual - POS - Printer SDK For Android API Reference Guide - English - Rev - 1 - 07 PDFDocument172 paginiManual - POS - Printer SDK For Android API Reference Guide - English - Rev - 1 - 07 PDFTwinsnet HospotÎncă nu există evaluări
- Class 8 Chapter 2Document4 paginiClass 8 Chapter 2a38478873Încă nu există evaluări
- Unable To Boot and Install Windows 10 From USB Pen Drive (Rufus) - Solved - Free Computer TricksDocument5 paginiUnable To Boot and Install Windows 10 From USB Pen Drive (Rufus) - Solved - Free Computer Tricksmorgoth_bassÎncă nu există evaluări
- Embedded Systems Essentials With Arm: Getting StartedDocument2 paginiEmbedded Systems Essentials With Arm: Getting StartedWajahat Riaz MirzaÎncă nu există evaluări
- Ts 7400 DatasheetDocument1 paginăTs 7400 DatasheetmanteshbÎncă nu există evaluări
- Flir M-Series and Maxsea Time ZeroDocument4 paginiFlir M-Series and Maxsea Time ZeromuzzaukÎncă nu există evaluări