S-ar putea să vă placă și
- Shakespeare Quotes - 55Document7 paginiShakespeare Quotes - 55topimasterÎncă nu există evaluări
- Why Lakshmi Goes To Wrong People - Webdunia EnglishDocument1 paginăWhy Lakshmi Goes To Wrong People - Webdunia EnglishtopimasterÎncă nu există evaluări
- Amazon Entices Indian Enterprises With AWS Region in MumbaiDocument7 paginiAmazon Entices Indian Enterprises With AWS Region in MumbaitopimasterÎncă nu există evaluări
- AWS EC2 Instance Types - Amazon Web Services (AWS)Document19 paginiAWS EC2 Instance Types - Amazon Web Services (AWS)topimasterÎncă nu există evaluări
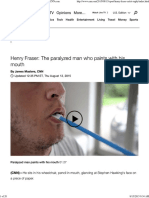
- Henry Fraser - Paralyzed, He Paints With His Mouth - CNN PDFDocument20 paginiHenry Fraser - Paralyzed, He Paints With His Mouth - CNN PDFtopimasterÎncă nu există evaluări
- AWS Total Cost of Ownership (TCO) Calculator: ServersDocument1 paginăAWS Total Cost of Ownership (TCO) Calculator: ServerstopimasterÎncă nu există evaluări
- Henry Fraser - Paralyzed, He Paints With His Mouth - CNN PDFDocument20 paginiHenry Fraser - Paralyzed, He Paints With His Mouth - CNN PDFtopimasterÎncă nu există evaluări
- PeterPan-BBC - Future - What Peter Pan Teaches Us About Memory and ConsciousnessDocument12 paginiPeterPan-BBC - Future - What Peter Pan Teaches Us About Memory and ConsciousnesstopimasterÎncă nu există evaluări
- Chanting (Japa) and Meditation - What Is The DifferenceDocument79 paginiChanting (Japa) and Meditation - What Is The DifferencetopimasterÎncă nu există evaluări
- The Biggest Impediment To Cloud Adoption Is Cultural - CapioIT CEO - Forbes IndiaDocument5 paginiThe Biggest Impediment To Cloud Adoption Is Cultural - CapioIT CEO - Forbes IndiatopimasterÎncă nu există evaluări
- AWS TCO Web Applications PDFDocument30 paginiAWS TCO Web Applications PDFUpendra KumarÎncă nu există evaluări
- AWS CloudFormation - AWS BlogDocument29 paginiAWS CloudFormation - AWS BlogtopimasterÎncă nu există evaluări
- HDFS - Hadoop and Solid State Drives PDFDocument8 paginiHDFS - Hadoop and Solid State Drives PDFtopimasterÎncă nu există evaluări
- 10 - Big Data Analytics PrimerDocument33 pagini10 - Big Data Analytics PrimertopimasterÎncă nu există evaluări
- Danish Companies Seek To Hire, But Everyone's Already Working - The New York TimesDocument5 paginiDanish Companies Seek To Hire, But Everyone's Already Working - The New York TimestopimasterÎncă nu există evaluări
- HDFS - Mapreduce - Hadoop Namenode Single Point of Failure - Stack OverflowDocument2 paginiHDFS - Mapreduce - Hadoop Namenode Single Point of Failure - Stack OverflowtopimasterÎncă nu există evaluări
- Hadoop Research Hortonworks Impact Report 10 JUL 2012Document4 paginiHadoop Research Hortonworks Impact Report 10 JUL 2012topimasterÎncă nu există evaluări
- MapReduce and MPP - Two Sides of The Big Data Coin - ZDNet PDFDocument5 paginiMapReduce and MPP - Two Sides of The Big Data Coin - ZDNet PDFtopimasterÎncă nu există evaluări
- Ten Years On, Jeff Bezos' Risky Bet' On Amazon Web Services Pays Off BigDocument11 paginiTen Years On, Jeff Bezos' Risky Bet' On Amazon Web Services Pays Off BigtopimasterÎncă nu există evaluări
- Chakra - WikiDocument16 paginiChakra - Wikitopimaster100% (1)
- BBC - Travel - The Stunning Home of A Ruthless KingDocument10 paginiBBC - Travel - The Stunning Home of A Ruthless KingtopimasterÎncă nu există evaluări
- BBC - Capital - How To Tell Someone They SCK - The British WayDocument15 paginiBBC - Capital - How To Tell Someone They SCK - The British WaytopimasterÎncă nu există evaluări
- 2014's Best Online Colleges For A Master's DegreeDocument6 pagini2014's Best Online Colleges For A Master's DegreetopimasterÎncă nu există evaluări
- Life - I Have No Choice But To Keep Looking' - The New York TimesDocument15 paginiLife - I Have No Choice But To Keep Looking' - The New York TimestopimasterÎncă nu există evaluări
- BBC - Travel - Living in - The World's Safest CitiesDocument24 paginiBBC - Travel - Living in - The World's Safest CitiestopimasterÎncă nu există evaluări
- Addicted To Caffeine, Love Drones, Scared of Ebola - There's A Motif For That! - Yahoo FinanceDocument5 paginiAddicted To Caffeine, Love Drones, Scared of Ebola - There's A Motif For That! - Yahoo FinancetopimasterÎncă nu există evaluări
- The Potato Farmer Who Swapped Bankruptcy For Making Millions - BBC NewsDocument15 paginiThe Potato Farmer Who Swapped Bankruptcy For Making Millions - BBC NewstopimasterÎncă nu există evaluări
- R-Cheat SheetDocument4 paginiR-Cheat SheetPrasad Marathe100% (1)
- How Motif Helped Two 11-Year-Olds Beat Ivy League MBAs in An Investing Contest - PandoDailyDocument13 paginiHow Motif Helped Two 11-Year-Olds Beat Ivy League MBAs in An Investing Contest - PandoDailytopimasterÎncă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Mini-Split Service GuideDocument49 paginiMini-Split Service Guideady_gligor7987Încă nu există evaluări
- Ee-316 - Circuit Theory LabDocument47 paginiEe-316 - Circuit Theory LabsureshhasiniÎncă nu există evaluări
- Acp 400020180910102625Document2 paginiAcp 400020180910102625Sofyan Andika YusufÎncă nu există evaluări
- Circle Generation AlgorithmDocument3 paginiCircle Generation AlgorithmAhmed AjmalÎncă nu există evaluări
- Block Out TimeDocument3 paginiBlock Out TimeschumangelÎncă nu există evaluări
- Civil & Environmental Engineering Lab Consolidation TestDocument14 paginiCivil & Environmental Engineering Lab Consolidation TestSapria AdiÎncă nu există evaluări
- Smart Bell Notification System Using IoTDocument3 paginiSmart Bell Notification System Using IoTTony StankÎncă nu există evaluări
- Declarative KnowledgeDocument2 paginiDeclarative KnowledgeEliiAfrÎncă nu există evaluări
- Huffman & ShannonDocument30 paginiHuffman & ShannonDhamodharan SrinivasanÎncă nu există evaluări
- VisQ Queue Manager System Guide Version 10.3Document27 paginiVisQ Queue Manager System Guide Version 10.3MSC Nastran Beginner100% (1)
- Modern Soil Stabilization TechniquesDocument25 paginiModern Soil Stabilization TechniquesSagar Jha100% (3)
- J) Method Statement For Discharge of Stormwater and Rain WaterDocument4 paginiJ) Method Statement For Discharge of Stormwater and Rain WaterLee Tin YanÎncă nu există evaluări
- How To Read Architect DrawingDocument32 paginiHow To Read Architect DrawingKutty Mansoor50% (2)
- Ticketreissue PDFDocument61 paginiTicketreissue PDFnicoNicoletaÎncă nu există evaluări
- KANSAS CITY Hyatt Regency Hotel Walkways CollapseDocument8 paginiKANSAS CITY Hyatt Regency Hotel Walkways CollapseRafran RoslyÎncă nu există evaluări
- Guide to Rubber Expansion JointsDocument7 paginiGuide to Rubber Expansion JointsHu HenryÎncă nu există evaluări
- Project Management Book PDFDocument55 paginiProject Management Book PDFSerigne Mbaye Diop94% (16)
- Manual em Portugues DGX230Document120 paginiManual em Portugues DGX230Agosthis0% (1)
- DBX DriveRack PA 2 BrochureDocument2 paginiDBX DriveRack PA 2 BrochureSound Technology LtdÎncă nu există evaluări
- TARPfinal PDFDocument28 paginiTARPfinal PDFRakesh ReddyÎncă nu există evaluări
- Philippines - Media LandscapesDocument38 paginiPhilippines - Media LandscapesGuillian Mae PalconeÎncă nu există evaluări
- Gas LiftDocument35 paginiGas LiftHìnhxămNơigóckhuấtTimAnh100% (1)
- WWW - Unitoperation Heat1Document12 paginiWWW - Unitoperation Heat1mahendra shakyaÎncă nu există evaluări
- Service Accessories: CatalogDocument32 paginiService Accessories: CatalogdummaÎncă nu există evaluări
- 29 KprogDocument582 pagini29 KprogMike MorrowÎncă nu există evaluări
- Julian Assange Why The World Needs Wikileaks: General InstructionsDocument1 paginăJulian Assange Why The World Needs Wikileaks: General InstructionsChris CiervoÎncă nu există evaluări
- Master Plumber Exam Coverage (Philippines)Document4 paginiMaster Plumber Exam Coverage (Philippines)Eugene Micarandayo100% (3)
- SAP-Press - Abap Development For Sap HanaDocument30 paginiSAP-Press - Abap Development For Sap HananicocastanioÎncă nu există evaluări
- (Airplane Design) Jan Roskam - Airplane Design Part V - Component Weight Estimation. 5-DARcorporation (2018)Document227 pagini(Airplane Design) Jan Roskam - Airplane Design Part V - Component Weight Estimation. 5-DARcorporation (2018)Daniel Lobato Bernardes100% (1)
- Shallow Foundation Assignment 1 (Finals)Document2 paginiShallow Foundation Assignment 1 (Finals)Lensearfwyn NamocatcatÎncă nu există evaluări