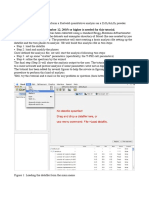
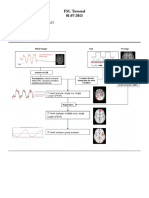
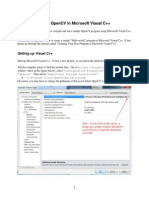
S-ar putea să vă placă și
- Registration PracticalDocument8 paginiRegistration Practicaljawad.melhemÎncă nu există evaluări
- CS 32 Project 4, Spring 2014Document5 paginiCS 32 Project 4, Spring 2014everyotherwhereÎncă nu există evaluări
- Assignment 2Document1 paginăAssignment 2DeviPrasadTripathyÎncă nu există evaluări
- Use Design AssistantDocument8 paginiUse Design AssistantGraham MooreÎncă nu există evaluări
- 2 Segmentation PracticalDocument8 pagini2 Segmentation PracticaldanxalreadyÎncă nu există evaluări
- ADS Tutorial: A Beginners Tutorial: Modes of OperationDocument22 paginiADS Tutorial: A Beginners Tutorial: Modes of OperationFredCamoneÎncă nu există evaluări
- Project: Data Modeling With Postgres: "ARJIE2Y1187B994AB7" "" "Line Renaud" "SOUPIRU12A6D4FA1E1" "Der Kleine Dompfaff"Document4 paginiProject: Data Modeling With Postgres: "ARJIE2Y1187B994AB7" "" "Line Renaud" "SOUPIRU12A6D4FA1E1" "Der Kleine Dompfaff"Bright SelbyÎncă nu există evaluări
- ADS Tutorial: A Beginners Tutorial: Modes of OperationDocument13 paginiADS Tutorial: A Beginners Tutorial: Modes of OperationYounes Ait El MaatiÎncă nu există evaluări
- Fanntoolusersguide 161106045408Document21 paginiFanntoolusersguide 161106045408palmer okunaÎncă nu există evaluări
- QPA TrainingDocument13 paginiQPA TrainingsenthilkumarÎncă nu există evaluări
- ReadmeDocument8 paginiReadmeprashantgajjarÎncă nu există evaluări
- Protein Structure ExplorationDocument22 paginiProtein Structure Explorationsuveer698Încă nu există evaluări
- Extracted From Onechannelgui Vignettes.: Figure 1: Microarray Analysis Pipe-LineDocument35 paginiExtracted From Onechannelgui Vignettes.: Figure 1: Microarray Analysis Pipe-LinehouktoÎncă nu există evaluări
- Ansys Basic Analysis GuideDocument237 paginiAnsys Basic Analysis GuideUmesh Vishwakarma100% (1)
- Vlffilter PDFDocument6 paginiVlffilter PDFproÎncă nu există evaluări
- Khffilt ManuDocument6 paginiKhffilt ManuAlao EmmanuelÎncă nu există evaluări
- Applied Econometrics Using StataDocument100 paginiApplied Econometrics Using Statahvproano100% (1)
- Plot XYDocument8 paginiPlot XYumairnaeem_90Încă nu există evaluări
- FYSMENA4111 Computer Lab 4 DOSDocument5 paginiFYSMENA4111 Computer Lab 4 DOSwer809Încă nu există evaluări
- Tutorial PyROOTDocument18 paginiTutorial PyROOTtesterÎncă nu există evaluări
- Centurion Data ManagmentDocument5 paginiCenturion Data ManagmentDIEGO MARTIN MAESOÎncă nu există evaluări
- User Guide For PLS ApplicationsDocument81 paginiUser Guide For PLS ApplicationsMuhammad AbubakarÎncă nu există evaluări
- Manual FullProf Studio PDFDocument9 paginiManual FullProf Studio PDFAhmad AwadallahÎncă nu există evaluări
- Abinitio QuestionsDocument2 paginiAbinitio Questionstirupatirao pasupulatiÎncă nu există evaluări
- Command Window: Stata Results Window: Variables Window: Review WindowDocument3 paginiCommand Window: Stata Results Window: Variables Window: Review WindowAkolgo PaulinaÎncă nu există evaluări
- Getting Started: Brief Step-By-Step Guide: (PDF File)Document5 paginiGetting Started: Brief Step-By-Step Guide: (PDF File)Hakkı SaraylıkÎncă nu există evaluări
- Step by Step TutorialDocument8 paginiStep by Step TutorialkPrasad8Încă nu există evaluări
- Practical 1Document9 paginiPractical 1yyshafÎncă nu există evaluări
- 9 The Plotting Program Plotxy: Short Description and Operating Instructions (Rel. March 2000)Document8 pagini9 The Plotting Program Plotxy: Short Description and Operating Instructions (Rel. March 2000)Ionutz AxuÎncă nu există evaluări
- Atp To MathcadDocument8 paginiAtp To MathcadalpcruzÎncă nu există evaluări
- CS440: HW3Document7 paginiCS440: HW3Jon MuellerÎncă nu există evaluări
- Screen BuilderDocument26 paginiScreen BuildersandyÎncă nu există evaluări
- A Differential Evolution Based Nonlinear Least Squares Fortran 77 ProgramDocument13 paginiA Differential Evolution Based Nonlinear Least Squares Fortran 77 ProgramSudhanshu K Mishra100% (5)
- CSE 5311: Design and Analysis of Algorithms Programming Project TopicsDocument3 paginiCSE 5311: Design and Analysis of Algorithms Programming Project TopicsFgvÎncă nu există evaluări
- Ab InitioFAQ2Document14 paginiAb InitioFAQ2Sravya ReddyÎncă nu există evaluări
- Lab Manual Tutorial Part1Document12 paginiLab Manual Tutorial Part1Ardser AvicoÎncă nu există evaluări
- HTK (v.3.1) : Basic Tutorial: ContentDocument18 paginiHTK (v.3.1) : Basic Tutorial: ContentJanković MilicaÎncă nu există evaluări
- TunerPro5 QuickGuide Rev1.2Document13 paginiTunerPro5 QuickGuide Rev1.2Danno NÎncă nu există evaluări
- Procmt GuiDocument34 paginiProcmt Guigeo.yetaoÎncă nu există evaluări
- Chem Kin Student ManualDocument44 paginiChem Kin Student ManualNitin KumbhareÎncă nu există evaluări
- Most Repeated Questions With AnswersDocument8 paginiMost Repeated Questions With AnswersDeepak Simhadri100% (1)
- Seanmaro 04 Alignment-WorkshopDocument26 paginiSeanmaro 04 Alignment-Workshopfda.narvaezÎncă nu există evaluări
- Informatica Geek Interview QuestionsDocument69 paginiInformatica Geek Interview QuestionsacechinmayÎncă nu există evaluări
- HDL Survival GuideDocument8 paginiHDL Survival GuideGabriele CongiuÎncă nu există evaluări
- Tunning Dss QueriesDocument16 paginiTunning Dss QueriesAirc SmtpÎncă nu există evaluări
- How-To Use Off-The-Shelf Software Packages To Perform Power Systems AnalysisDocument316 paginiHow-To Use Off-The-Shelf Software Packages To Perform Power Systems Analysisهانى خيرÎncă nu există evaluări
- Plot XYDocument10 paginiPlot XYbubo28Încă nu există evaluări
- MSU Latent AFIS User GuideDocument7 paginiMSU Latent AFIS User Guidehai NguyenÎncă nu există evaluări
- SDMPSI TutorialDocument18 paginiSDMPSI TutorialStachen SharpenerÎncă nu există evaluări
- MaudbatchDocument7 paginiMaudbatchbalrog9007Încă nu există evaluări
- Hints To Dyna Prepost PDFDocument2 paginiHints To Dyna Prepost PDFLongÎncă nu există evaluări
- Siemens Power System Simulation For Engineers® (Pss/E)Document15 paginiSiemens Power System Simulation For Engineers® (Pss/E)Dms8sa8IÎncă nu există evaluări
- FLUENT ClusterDocument11 paginiFLUENT Clustergat11Încă nu există evaluări
- Lab and Homework 1: Computer Science ClassDocument16 paginiLab and Homework 1: Computer Science ClassPrasad MahajanÎncă nu există evaluări
- Assignment 1Document5 paginiAssignment 1Changwook JungÎncă nu există evaluări
- User's Guide For JSPELLDocument36 paginiUser's Guide For JSPELLnegrau72Încă nu există evaluări
- A Guide To The Use of Nextnano PDFDocument16 paginiA Guide To The Use of Nextnano PDFSubhashish Dolai100% (1)
- The Open Service Node (OSN) A Practical Approach To Getting StartedDocument11 paginiThe Open Service Node (OSN) A Practical Approach To Getting StartedJuly MinÎncă nu există evaluări
- LAB 3: Introduction To Signal Flow Graphs (10 Points)Document5 paginiLAB 3: Introduction To Signal Flow Graphs (10 Points)mrithyunjaysivÎncă nu există evaluări
- MVS JCL Utilities Quick Reference, Third EditionDe la EverandMVS JCL Utilities Quick Reference, Third EditionEvaluare: 5 din 5 stele5/5 (1)
- The Mac Terminal Reference and Scripting PrimerDe la EverandThe Mac Terminal Reference and Scripting PrimerEvaluare: 4.5 din 5 stele4.5/5 (3)
- Foa, 2010. CBT of OCD PDFDocument9 paginiFoa, 2010. CBT of OCD PDFmariobar17636Încă nu există evaluări
- A Default Mode of Brain Function A Brief History of An Evolving IdeaDocument8 paginiA Default Mode of Brain Function A Brief History of An Evolving IdeadarketaÎncă nu există evaluări
- Development of Learning and Memory in Aplysia IDocument13 paginiDevelopment of Learning and Memory in Aplysia Imariobar17636Încă nu există evaluări
- Ain Stimulation in The Study and Treatment of AddictionDocument16 paginiAin Stimulation in The Study and Treatment of Addictionmariobar17636Încă nu există evaluări
- CONN FMRI Functional Connectivity Toolbox Manual v17Document38 paginiCONN FMRI Functional Connectivity Toolbox Manual v17mariobar17636Încă nu există evaluări
- Baxter, 1987. Local Cerebral Glucose Metabolic Rates in OCDDocument8 paginiBaxter, 1987. Local Cerebral Glucose Metabolic Rates in OCDmariobar17636Încă nu există evaluări
- Corticostriatal Functional Connectivity in Non-Medicated Patients With OCDDocument7 paginiCorticostriatal Functional Connectivity in Non-Medicated Patients With OCDmariobar17636Încă nu există evaluări
- Alexander, 1986. Parallel Organization of Functionally Segregated Circuits Linking Basal Ganglia and CortexDocument25 paginiAlexander, 1986. Parallel Organization of Functionally Segregated Circuits Linking Basal Ganglia and Cortexmariobar17636Încă nu există evaluări
- Default Network Connectivity As A Vulnerability Marker For OCD (Peng, 2014)Document10 paginiDefault Network Connectivity As A Vulnerability Marker For OCD (Peng, 2014)mariobar17636Încă nu există evaluări
- Jhung, 2014. Distinct Functinal Connectivity of Limbic Network in The Washing Type OCDDocument7 paginiJhung, 2014. Distinct Functinal Connectivity of Limbic Network in The Washing Type OCDmariobar17636Încă nu există evaluări
- Moreira, 2017. The Neural Correlates of OCD, A Multimodal Perspective PDFDocument8 paginiMoreira, 2017. The Neural Correlates of OCD, A Multimodal Perspective PDFmariobar17636Încă nu există evaluări
- Tutorial FSLDocument23 paginiTutorial FSLmariobar17636Încă nu există evaluări
- Etkin, 2015. The Neural Bases of Emotion RegulationDocument8 paginiEtkin, 2015. The Neural Bases of Emotion Regulationmariobar17636Încă nu există evaluări
- Altered Corticostriatal Funcional Connectivity in OCD (Harrison, 2009)Document12 paginiAltered Corticostriatal Funcional Connectivity in OCD (Harrison, 2009)mariobar17636Încă nu există evaluări
- The Brains Default Mode Network (2015, Raichle)Document19 paginiThe Brains Default Mode Network (2015, Raichle)mariobar17636Încă nu există evaluări
- 2005, Massimini. Breakdown of Cortical Effective Connectivity During SleepDocument6 pagini2005, Massimini. Breakdown of Cortical Effective Connectivity During Sleepmariobar17636Încă nu există evaluări
- Huyser, 2011. Developmental Aspects of Error and High-Conflict-Related Brin Activity in Pediatric OCD, A FMRI Study With A Flanker Task Before and After CBTDocument10 paginiHuyser, 2011. Developmental Aspects of Error and High-Conflict-Related Brin Activity in Pediatric OCD, A FMRI Study With A Flanker Task Before and After CBTmariobar17636Încă nu există evaluări
- Rubinov 2010Document11 paginiRubinov 2010mariobar17636Încă nu există evaluări
- PLAN NEGOCIO Marketing y Publicidad PDFDocument77 paginiPLAN NEGOCIO Marketing y Publicidad PDFjorgeÎncă nu există evaluări
- FSL PreProcessing Pipeline OHBM15 JenkinsonDocument63 paginiFSL PreProcessing Pipeline OHBM15 JenkinsonElham AtlassiÎncă nu există evaluări
- Fornito 2015Document16 paginiFornito 2015mariobar17636Încă nu există evaluări
- Gotlib. Neuroimaging and DepressionDocument5 paginiGotlib. Neuroimaging and Depressionmariobar17636Încă nu există evaluări
- Altered Corticostriatal Funcional Connectivity in OCD (Harrison, 2009)Document12 paginiAltered Corticostriatal Funcional Connectivity in OCD (Harrison, 2009)mariobar17636Încă nu există evaluări
- Prefrontal Subcortical Dissociations Underlying Inhibitory Control Revealed by Event Related FMRI (Kelly, 2004)Document8 paginiPrefrontal Subcortical Dissociations Underlying Inhibitory Control Revealed by Event Related FMRI (Kelly, 2004)mariobar17636Încă nu există evaluări
- Grey Matter Abnormalities in Obsessive-Compulsive Disorder (Kim, 2001)Document6 paginiGrey Matter Abnormalities in Obsessive-Compulsive Disorder (Kim, 2001)mariobar17636Încă nu există evaluări
- Manual SPM12Document508 paginiManual SPM12mariobar17636Încă nu există evaluări
- MRI y DisociaciónDocument12 paginiMRI y Disociaciónmariobar17636Încă nu există evaluări
- A Biosocial Developmental Model of Borderline PersonalityDocument28 paginiA Biosocial Developmental Model of Borderline Personalitymariobar17636Încă nu există evaluări
- A Functional Magnetic Resonance Imaging Study of Inhibitory Control in OCD (Page, 2009)Document8 paginiA Functional Magnetic Resonance Imaging Study of Inhibitory Control in OCD (Page, 2009)mariobar17636Încă nu există evaluări
- OpenCV in Visua LC++Document5 paginiOpenCV in Visua LC++BryanGumelarÎncă nu există evaluări
- LinuxDocument206 paginiLinuxDinesh BhawnaniÎncă nu există evaluări
- 5.1 - Text FilesDocument27 pagini5.1 - Text Files23520053 I Putu Eka Surya AdityaÎncă nu există evaluări
- Sample Data Into Splunk EnterpriseDocument58 paginiSample Data Into Splunk EnterpriseOkta Jilid IIÎncă nu există evaluări
- Long PathsDocument13 paginiLong PathsReinhard VzÎncă nu există evaluări
- Os Lab 2Document18 paginiOs Lab 2Syed SybtainÎncă nu există evaluări
- Advanced Programmers Reference ManualDocument200 paginiAdvanced Programmers Reference ManualK_Be64Încă nu există evaluări
- Aphelion Imaging Suite-Quick Installation GuideDocument2 paginiAphelion Imaging Suite-Quick Installation Guidekarina19851Încă nu există evaluări
- Microsoft Windows 98Document56 paginiMicrosoft Windows 98bernardÎncă nu există evaluări
- CP R75.45 ReleaseNotesDocument16 paginiCP R75.45 ReleaseNotesAlvaro Auza BarriosÎncă nu există evaluări
- webERP Manual PDFDocument270 paginiwebERP Manual PDFLeonard MaramisÎncă nu există evaluări
- Fail2Ban Fail2Ban: Setup SetupDocument6 paginiFail2Ban Fail2Ban: Setup SetupiFellixeÎncă nu există evaluări
- Turbo C GraphicsDocument9 paginiTurbo C GraphicsTristan Bancoro EstudilloÎncă nu există evaluări
- Talend ESB Container AG 6.2.1 enDocument104 paginiTalend ESB Container AG 6.2.1 eninfiniti786Încă nu există evaluări
- Computer Networks Application Layer NotesDocument23 paginiComputer Networks Application Layer Notess indraneelÎncă nu există evaluări
- EpicorUserExpCust UserGuide 905700 Part1of3Document124 paginiEpicorUserExpCust UserGuide 905700 Part1of3ஜெயப்பிரகாஷ் பிரபாகரன்Încă nu există evaluări
- Wily 9.5Document34 paginiWily 9.5FirefighterÎncă nu există evaluări
- Installation ManualDocument51 paginiInstallation Manualoscarzocon5105Încă nu există evaluări
- AutoCAD 2006 Installing Network License Manager0Document12 paginiAutoCAD 2006 Installing Network License Manager0gurugovindanÎncă nu există evaluări
- Parameters of The Command Prompt in Kaspersky Internet Security 2010Document9 paginiParameters of The Command Prompt in Kaspersky Internet Security 2010sameditzoÎncă nu există evaluări
- Installing MySQL On Unix Linux Using Generic BinariesDocument6 paginiInstalling MySQL On Unix Linux Using Generic BinariesStephen EfangeÎncă nu există evaluări
- Taylor R. Brown - An Introduction To R and Python For Data Analysis - A Side-By-Side Approach-CRC Press - Chapman & Hall (2023)Document267 paginiTaylor R. Brown - An Introduction To R and Python For Data Analysis - A Side-By-Side Approach-CRC Press - Chapman & Hall (2023)Himal ThapaÎncă nu există evaluări
- Linux - Linux For Beginners Guide To Learn Linux Command LineDocument99 paginiLinux - Linux For Beginners Guide To Learn Linux Command Linehov kah100% (2)
- IBM Security Guardium Key Lifecycle Manager: BooksDocument128 paginiIBM Security Guardium Key Lifecycle Manager: Booksgborja8881331Încă nu există evaluări
- Siemens Documen2tation PDFDocument1 paginăSiemens Documen2tation PDFrafaelsbispoÎncă nu există evaluări
- Manual Hudson v1!0!12 July 2013Document29 paginiManual Hudson v1!0!12 July 2013Chakravarthy DoppalapudiÎncă nu există evaluări
- PDMS User BulletinDocument21 paginiPDMS User BulletinAnastasiyaÎncă nu există evaluări
- LND iQSuite12 Installation enDocument81 paginiLND iQSuite12 Installation enRommel ReformaÎncă nu există evaluări