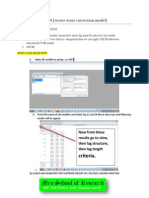
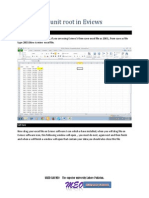
S-ar putea să vă placă și
- Statistics 578 Assignemnt 3Document12 paginiStatistics 578 Assignemnt 3Mia Dee100% (1)
- 2017 CFA Level 2 Mock Exam MorningDocument40 pagini2017 CFA Level 2 Mock Exam MorningElsiiieÎncă nu există evaluări
- Between Within Stata AnalysisDocument3 paginiBetween Within Stata AnalysisMaria PappaÎncă nu există evaluări
- VECMDocument9 paginiVECMsaeed meo100% (3)
- VECMDocument9 paginiVECMsaeed meo100% (3)
- PowerBI Handwritten NoteDocument2 paginiPowerBI Handwritten NoteririxayÎncă nu există evaluări
- 2015 Midterm SolutionsDocument7 pagini2015 Midterm SolutionsEdith Kua100% (1)
- Char LieDocument64 paginiChar LieppecÎncă nu există evaluări
- GMM Resume PDFDocument60 paginiGMM Resume PDFdamian camargoÎncă nu există evaluări
- Vector Autoregressions: How To Choose The Order of A VARDocument8 paginiVector Autoregressions: How To Choose The Order of A VARv4nhuy3nÎncă nu există evaluări
- Test Help StatDocument18 paginiTest Help Statthenderson22603Încă nu există evaluări
- Training in MSA PQ Systems Training Material PDFDocument109 paginiTraining in MSA PQ Systems Training Material PDFsaby aroraÎncă nu există evaluări
- Univariate Time Series Modelling and ForecastingDocument72 paginiUnivariate Time Series Modelling and Forecastingjamesburden100% (1)
- Time Series - Practical ExercisesDocument9 paginiTime Series - Practical ExercisesJobayer Islam TunanÎncă nu există evaluări
- Metrics Final Slides From Darmouth PDFDocument126 paginiMetrics Final Slides From Darmouth PDFNarutoLLNÎncă nu există evaluări
- Cointegration PDFDocument76 paginiCointegration PDFVaishali SharmaÎncă nu există evaluări
- TSExamples PDFDocument9 paginiTSExamples PDFKhalilÎncă nu există evaluări
- Introduction To Vars and Structural Vars:: Estimation & Tests Using StataDocument69 paginiIntroduction To Vars and Structural Vars:: Estimation & Tests Using StataMohammed Al-SubaieÎncă nu există evaluări
- Time Sereis Analysis Using StataDocument26 paginiTime Sereis Analysis Using Statasaeed meo100% (7)
- VAR Lecture2Document39 paginiVAR Lecture2Udita GopalkrishnaÎncă nu există evaluări
- Panel Data ModelsDocument112 paginiPanel Data ModelsAlemuÎncă nu există evaluări
- Time Series QuestionsDocument9 paginiTime Series Questionsakriti_08100% (1)
- Univariate Time Series Modelling and ForecastingDocument74 paginiUnivariate Time Series Modelling and ForecastingUploader_LLBBÎncă nu există evaluări
- Forecasting PPT NotesDocument69 paginiForecasting PPT Noteskunwar67% (3)
- An Introduction To Stata For Economists: Data AnalysisDocument48 paginiAn Introduction To Stata For Economists: Data AnalysisXiaoying XuÎncă nu există evaluări
- Time Series Models and Forecasting and ForecastingDocument49 paginiTime Series Models and Forecasting and ForecastingDominic AndohÎncă nu există evaluări
- Consumer Behaviour and Impulsive Buying BehaviourDocument38 paginiConsumer Behaviour and Impulsive Buying BehaviourNeeraj Purohit100% (3)
- Chapter 8 - ForecastingDocument42 paginiChapter 8 - ForecastingVernier MirandaÎncă nu există evaluări
- Structural Equation Modeling in StataDocument10 paginiStructural Equation Modeling in StatajamazalaleÎncă nu există evaluări
- Slides 2-04 - The ARMA Model and Model Selection PDFDocument14 paginiSlides 2-04 - The ARMA Model and Model Selection PDFEduardo SeminarioÎncă nu există evaluări
- Application of ARIMAX ModelDocument5 paginiApplication of ARIMAX ModelAgus Setiansyah Idris ShalehÎncă nu există evaluări
- Generalized Method of Moments (GMM) Estimation: OutlineDocument16 paginiGeneralized Method of Moments (GMM) Estimation: OutlineDione BhaskaraÎncă nu există evaluări
- QMLR (Q) BankDocument27 paginiQMLR (Q) BankaymanÎncă nu există evaluări
- Measuring The Sustainabili Ty of Cities An Analysis of The Use of Local IndicatorsDocument12 paginiMeasuring The Sustainabili Ty of Cities An Analysis of The Use of Local IndicatorsVicky CeunfinÎncă nu există evaluări
- 578assignment2 F14 SolDocument15 pagini578assignment2 F14 Solaman_nsuÎncă nu există evaluări
- Stat443 Final2018 PDFDocument4 paginiStat443 Final2018 PDFTongtong ZhaiÎncă nu există evaluări
- ARIMAXDocument10 paginiARIMAXRyubi FarÎncă nu există evaluări
- STATA Data PanelDocument11 paginiSTATA Data PanelalbertolossÎncă nu există evaluări
- Linear Statistical Models The Less Than Full Rank Model: Yao-Ban ChanDocument140 paginiLinear Statistical Models The Less Than Full Rank Model: Yao-Ban ChanJack WangÎncă nu există evaluări
- Okun Law Pakisatn 1Document7 paginiOkun Law Pakisatn 1Ali ArsalanÎncă nu există evaluări
- Impact of Student Engagement On Academic Performance and Quality of Relationships of Traditional and Nontraditional StudentsDocument22 paginiImpact of Student Engagement On Academic Performance and Quality of Relationships of Traditional and Nontraditional StudentsGeorge GomezÎncă nu există evaluări
- Introduction To Regression Models For Panel Data Analysis Indiana University Workshop in Methods October 7, 2011 Professor Patricia A. McmanusDocument42 paginiIntroduction To Regression Models For Panel Data Analysis Indiana University Workshop in Methods October 7, 2011 Professor Patricia A. McmanusAnonymous 0sxQqwAIMBÎncă nu există evaluări
- Sections 2.1 - 2.3: Mind On StatisticsDocument22 paginiSections 2.1 - 2.3: Mind On StatisticsMahmoud Ayoub GodaÎncă nu există evaluări
- Empirical Analysis of The Relationship Between Economic Growth and Energy Consumption in Nigeria: A Multivariate Cointegration ApproachDocument12 paginiEmpirical Analysis of The Relationship Between Economic Growth and Energy Consumption in Nigeria: A Multivariate Cointegration ApproachTI Journals PublishingÎncă nu există evaluări
- Lecture 8 Application of VAR ModelDocument22 paginiLecture 8 Application of VAR ModelEason SaintÎncă nu există evaluări
- Lecture 7 VARDocument34 paginiLecture 7 VAREason SaintÎncă nu există evaluări
- Chapter Twenty - Time SeriesDocument21 paginiChapter Twenty - Time SeriesSDB_EconometricsÎncă nu există evaluări
- TS PartIIDocument50 paginiTS PartIIأبوسوار هندسةÎncă nu există evaluări
- 2.2. Univariate Time Series Analysis PDFDocument86 pagini2.2. Univariate Time Series Analysis PDFane9sdÎncă nu există evaluări
- STAT 497 - Old ExamsDocument71 paginiSTAT 497 - Old ExamsAnisa Anisa100% (1)
- ArimaDocument4 paginiArimaSofia LivelyÎncă nu există evaluări
- CH 10Document18 paginiCH 10Erjohn PapaÎncă nu există evaluări
- STATA Assignment 1 InstructionsDocument2 paginiSTATA Assignment 1 InstructionsRO BWNÎncă nu există evaluări
- MCQ 12765 KDocument21 paginiMCQ 12765 Kcool_spÎncă nu există evaluări
- Examples FTSA Questions2Document18 paginiExamples FTSA Questions2Anonymous 7CxwuBUJz3Încă nu există evaluări
- Econometrics Books: Books On-Line Books / NotesDocument8 paginiEconometrics Books: Books On-Line Books / Notesaftab20100% (1)
- Test Bank StatisticsDocument9 paginiTest Bank StatisticsGagandeep SinghÎncă nu există evaluări
- Sec D CH 12 Regression Part 2Document66 paginiSec D CH 12 Regression Part 2Ranga SriÎncă nu există evaluări
- BA 578 Assignment - 3Document13 paginiBA 578 Assignment - 3NaushilMaknojiaÎncă nu există evaluări
- BA 578 Live Fin Set2Document17 paginiBA 578 Live Fin Set2Sumana Salauddin100% (1)
- Study Guide For ECO 3411Document109 paginiStudy Guide For ECO 3411asd1084Încă nu există evaluări
- Stochastic Frontier Analysis StataDocument48 paginiStochastic Frontier Analysis StataAnonymous vI4dpAhc100% (2)
- Confidence Interval For Median Based On Sign TestDocument32 paginiConfidence Interval For Median Based On Sign TestRohaila Rohani100% (1)
- Microeconometrics Lecture NotesDocument407 paginiMicroeconometrics Lecture NotesburgguÎncă nu există evaluări
- Binary Dependent VarDocument5 paginiBinary Dependent VarManali PawarÎncă nu există evaluări
- IV Estimation PDFDocument59 paginiIV Estimation PDFduytueÎncă nu există evaluări
- Oracle LearningsDocument8 paginiOracle LearningsG RajakannuÎncă nu există evaluări
- An Empirical Investigation of Foreign Direct Investment and Economic Growth in SAARC NationsDocument17 paginiAn Empirical Investigation of Foreign Direct Investment and Economic Growth in SAARC NationsSayed Farrukh AhmedÎncă nu există evaluări
- Analysis of Credit Management System of Jamuna Bank Limited (JBL)Document38 paginiAnalysis of Credit Management System of Jamuna Bank Limited (JBL)Sayed Farrukh AhmedÎncă nu există evaluări
- Data Co2Document15 paginiData Co2Sayed Farrukh AhmedÎncă nu există evaluări
- Summer 2020 Updated Class Schedule MCDocument10 paginiSummer 2020 Updated Class Schedule MCSayed Farrukh AhmedÎncă nu există evaluări
- Accepted Manuscript: Research in International Business and FinanceDocument24 paginiAccepted Manuscript: Research in International Business and FinanceSayed Farrukh AhmedÎncă nu există evaluări
- Data Co2Document15 paginiData Co2Sayed Farrukh AhmedÎncă nu există evaluări
- Accounting Principles: The Recording ProcessDocument55 paginiAccounting Principles: The Recording ProcessSayed Farrukh AhmedÎncă nu există evaluări
- Cross-Sectional Dependence-Good PDFDocument16 paginiCross-Sectional Dependence-Good PDFSayed Farrukh AhmedÎncă nu există evaluări
- Macroeconomic Forces and Stock Prices:Evidence From The Bangladesh Stock MarketDocument55 paginiMacroeconomic Forces and Stock Prices:Evidence From The Bangladesh Stock MarketSayed Farrukh AhmedÎncă nu există evaluări
- Chapter 21: Accounting For LeasesDocument28 paginiChapter 21: Accounting For LeasesSayed Farrukh Ahmed100% (1)
- Intercorporate Acquisitions and Investments in Other EntitiesDocument31 paginiIntercorporate Acquisitions and Investments in Other EntitiesSayed Farrukh AhmedÎncă nu există evaluări
- Lankabangla Securities LTD.: Trade Confirmation Note (SumDocument1 paginăLankabangla Securities LTD.: Trade Confirmation Note (SumSayed Farrukh AhmedÎncă nu există evaluări
- Cross-Sectional Dependence-Good PDFDocument16 paginiCross-Sectional Dependence-Good PDFSayed Farrukh AhmedÎncă nu există evaluări
- CH 03Document91 paginiCH 03Sayed Farrukh AhmedÎncă nu există evaluări
- New Microsoft Office Excel WorksheetDocument1 paginăNew Microsoft Office Excel WorksheetSayed Farrukh AhmedÎncă nu există evaluări
- Chapter 21: Accounting For LeasesDocument28 paginiChapter 21: Accounting For LeasesSayed Farrukh Ahmed100% (1)
- Completion of The Accounting CycleDocument54 paginiCompletion of The Accounting CycleSayed Farrukh AhmedÎncă nu există evaluări
- Panel Data RepresentationDocument2 paginiPanel Data RepresentationSayed Farrukh AhmedÎncă nu există evaluări
- My WonrkDocument1 paginăMy WonrkSayed Farrukh AhmedÎncă nu există evaluări
- Good WDocument1 paginăGood WSayed Farrukh AhmedÎncă nu există evaluări
- Lcpi Lgdps Lgi Lint Lcpi (-3) Lgdps (-3) Lgi (-3) Lint (-3)Document2 paginiLcpi Lgdps Lgi Lint Lcpi (-3) Lgdps (-3) Lgi (-3) Lint (-3)Sayed Farrukh AhmedÎncă nu există evaluări
- Today 2017Document1 paginăToday 2017Sayed Farrukh AhmedÎncă nu există evaluări
- New Microsoft Office Word DocumentDocument2 paginiNew Microsoft Office Word DocumentSayed Farrukh AhmedÎncă nu există evaluări
- Bye ByeDocument1 paginăBye ByeSayed Farrukh AhmedÎncă nu există evaluări
- Lankabangla Securities LTD.: Trade Confirmation Note (SumDocument1 paginăLankabangla Securities LTD.: Trade Confirmation Note (SumSayed Farrukh AhmedÎncă nu există evaluări
- Time Sereis Analysis Using StataDocument26 paginiTime Sereis Analysis Using StataSayed Farrukh AhmedÎncă nu există evaluări
- Granger CusalityDocument4 paginiGranger CusalitySayed Farrukh AhmedÎncă nu există evaluări
- Unit Root Using EviewDocument9 paginiUnit Root Using Eviewsaeed meo75% (4)
- Cps 330 CDocument110 paginiCps 330 CIrwandi IrwandiÎncă nu există evaluări
- Simulation and Forecasting Solutions: (From Table) (No. of Cars)Document18 paginiSimulation and Forecasting Solutions: (From Table) (No. of Cars)Debbie DebzÎncă nu există evaluări
- Pone 0153487 s012Document4 paginiPone 0153487 s012radha satiÎncă nu există evaluări
- Chapter2Document70 paginiChapter2Duyên Nguyễn Huỳnh KhánhÎncă nu există evaluări
- Causes of Non Performing LoanDocument11 paginiCauses of Non Performing LoanMahiUddinÎncă nu există evaluări
- Degree of FreedomDocument16 paginiDegree of FreedomMuhammad SaeedÎncă nu există evaluări
- Komputasi Geologi: Muhammad Rizqy Septyandy, M.TDocument40 paginiKomputasi Geologi: Muhammad Rizqy Septyandy, M.TBagastio ラマダーンÎncă nu există evaluări
- Module A StatisticsDocument36 paginiModule A Statisticsnageswara kuchipudiÎncă nu există evaluări
- Dyedx: 1.1 Error TypesDocument44 paginiDyedx: 1.1 Error TypesmoonthinkerÎncă nu există evaluări
- Theory of Errors (AKS)Document32 paginiTheory of Errors (AKS)jeet174tÎncă nu există evaluări
- Chapter 6: Dividend Policy Analysis: BATBC: Behavior of EPS, DPS and PayoutDocument4 paginiChapter 6: Dividend Policy Analysis: BATBC: Behavior of EPS, DPS and PayoutShaikh Saifullah KhalidÎncă nu există evaluări
- Principles of Curve Fitting For Multiplex Sandwich Immunoassays PDFDocument4 paginiPrinciples of Curve Fitting For Multiplex Sandwich Immunoassays PDFParminder SinghÎncă nu există evaluări
- Ashoka University Stata Results Log Filenaresh SehdevDocument11 paginiAshoka University Stata Results Log Filenaresh Sehdevrs photocopyÎncă nu există evaluări
- Dissertation Logistic RegressionDocument4 paginiDissertation Logistic RegressionIWillPayYouToWriteMyPaperSingapore100% (1)
- NCFM TestDocument10 paginiNCFM TestPrahlad SonyÎncă nu există evaluări
- The Effect of Training Development, Motivation, and Compensation On The Employee's Work Productivity at Pt. Indojapan Steel CenterDocument8 paginiThe Effect of Training Development, Motivation, and Compensation On The Employee's Work Productivity at Pt. Indojapan Steel CenterAnonymous izrFWiQÎncă nu există evaluări
- Real Statistics Examples Regression 2Document377 paginiReal Statistics Examples Regression 2Dwicahyo WÎncă nu există evaluări
- Experimental Designs and ANOVADocument78 paginiExperimental Designs and ANOVAgianinaedrea.lim.educÎncă nu există evaluări
- Chi SquareDocument7 paginiChi SquareLori JeffriesÎncă nu există evaluări
- 2 SLS (Direct and Indirect) For Meroz Data SetDocument4 pagini2 SLS (Direct and Indirect) For Meroz Data SetAadil ZamanÎncă nu există evaluări
- Taller Regresion MultipleDocument11 paginiTaller Regresion MultipleANDRESÎncă nu există evaluări
- Lampiran 4-8 - Hasil Olah DataDocument11 paginiLampiran 4-8 - Hasil Olah DataIstriPratiwiÎncă nu există evaluări
- Research Team Dupax Del Norte Draft 1Document73 paginiResearch Team Dupax Del Norte Draft 1Ricamel PatawegÎncă nu există evaluări
- IGD Project Group 4 - EditedDocument16 paginiIGD Project Group 4 - EditedAkash GuptaÎncă nu există evaluări