S-ar putea să vă placă și
- Hiding Unwanted Rows in Webi ReportDocument6 paginiHiding Unwanted Rows in Webi Reporthnoor6Încă nu există evaluări
- Info Session: From Trax To COMPASS-360: October 20, 2020Document14 paginiInfo Session: From Trax To COMPASS-360: October 20, 2020hnoor6Încă nu există evaluări
- How Decision Tree Algorithm WorksDocument16 paginiHow Decision Tree Algorithm Workshnoor6Încă nu există evaluări
- Creating New Opportunities With Open-Minded LeadershipDocument2 paginiCreating New Opportunities With Open-Minded Leadershiphnoor6Încă nu există evaluări
- The Mystery of Matter Episode 2 Unruly ElementsDocument37 paginiThe Mystery of Matter Episode 2 Unruly Elementshnoor6Încă nu există evaluări
- DMP3036SSS: V R I T +25°cDocument6 paginiDMP3036SSS: V R I T +25°chnoor6Încă nu există evaluări
- Firefox Settings ResetDocument4 paginiFirefox Settings Resethnoor6Încă nu există evaluări
- Section 7: Laws of Thermodynamics: Too Hot, Too Cold, Just RightDocument14 paginiSection 7: Laws of Thermodynamics: Too Hot, Too Cold, Just Righthnoor6Încă nu există evaluări
- Color Coding The Periodic TableDocument8 paginiColor Coding The Periodic Tablehnoor6Încă nu există evaluări
- A New Efficient Matrix Based Frequent Itemset Mining Algorithm With TagsDocument4 paginiA New Efficient Matrix Based Frequent Itemset Mining Algorithm With Tagshnoor6Încă nu există evaluări
- Chapter 14Document13 paginiChapter 14hnoor6Încă nu există evaluări
- Murach SQL Server 2012 Chapter 3 Flashcards - QuizletDocument4 paginiMurach SQL Server 2012 Chapter 3 Flashcards - Quizlethnoor6Încă nu există evaluări
- The Minkowski Distance Is Computed Using Equation 218 Therefore With H 3 WeDocument5 paginiThe Minkowski Distance Is Computed Using Equation 218 Therefore With H 3 Wehnoor6Încă nu există evaluări
- Murach SQL Server 2012 Chapter 3 Flashcards - QuizletDocument4 paginiMurach SQL Server 2012 Chapter 3 Flashcards - Quizlethnoor6Încă nu există evaluări
- Murach SQL Server 2012 Chapter 6 Flashcards - QuizletDocument4 paginiMurach SQL Server 2012 Chapter 6 Flashcards - Quizlethnoor6Încă nu există evaluări
- Handout On SQL Server Analysis Services TutorialsDocument10 paginiHandout On SQL Server Analysis Services Tutorialshnoor6Încă nu există evaluări
- Set The Example (Chapter 3) Flashcards - QuizletDocument5 paginiSet The Example (Chapter 3) Flashcards - Quizlethnoor6Încă nu există evaluări
- Murach SQL Server 2012 Chapter 2 Flashcards - QuizletDocument3 paginiMurach SQL Server 2012 Chapter 2 Flashcards - Quizlethnoor6Încă nu există evaluări
- Murach SQL Server 2012 Chapter 4 Flashcards - QuizletDocument3 paginiMurach SQL Server 2012 Chapter 4 Flashcards - Quizlethnoor6Încă nu există evaluări
- CSS Shorthand Cheat Sheet by ExampleDocument11 paginiCSS Shorthand Cheat Sheet by Examplehnoor6Încă nu există evaluări
- Chapter 8 Exercises - Lyman Ott Michael Longnecker An IntroducDocument13 paginiChapter 8 Exercises - Lyman Ott Michael Longnecker An Introduchnoor60% (1)
- Murach SQL Server 2012 Chapter 1 Flashcards - QuizletDocument7 paginiMurach SQL Server 2012 Chapter 1 Flashcards - Quizlethnoor6Încă nu există evaluări
- An Android Cheat Sheet (My Notes, Main Concepts)Document18 paginiAn Android Cheat Sheet (My Notes, Main Concepts)hnoor6Încă nu există evaluări
- ReadDocument1 paginăReadhnoor6Încă nu există evaluări
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- FSR500 ManualDocument144 paginiFSR500 Manualmiroy14964Încă nu există evaluări
- Virtual RealityDocument32 paginiVirtual RealityayushaggarwalÎncă nu există evaluări
- Systems Analysis For Library ManagementDocument241 paginiSystems Analysis For Library ManagementMahfoz Kazol100% (1)
- Strategic Procurement Cloud Integration Options R13Document20 paginiStrategic Procurement Cloud Integration Options R13Sanjeev ThakurÎncă nu există evaluări
- The Transistor Tester User Manual (Newly)Document7 paginiThe Transistor Tester User Manual (Newly)Tanel Laanemägi100% (1)
- <%TRUSTED SSD CHEMICAL SOLUTION FOR CLEANING BLACK NOTES+27780171131 Activation Powder to clean all type of black color currency, defaced bank notes durban North West Northern Cape Western Cape Call +27780171131 to purchaseDocument184 pagini<%TRUSTED SSD CHEMICAL SOLUTION FOR CLEANING BLACK NOTES+27780171131 Activation Powder to clean all type of black color currency, defaced bank notes durban North West Northern Cape Western Cape Call +27780171131 to purchasejona tumukundeÎncă nu există evaluări
- Compiler Techniques For Exposing ILPDocument4 paginiCompiler Techniques For Exposing ILPGan EshÎncă nu există evaluări
- Quotation of SAI NewDocument4 paginiQuotation of SAI NewAnujoy MaitiÎncă nu există evaluări
- Cyberoam Release Notes V 10 CR15wi, CR15i & CR25iDocument17 paginiCyberoam Release Notes V 10 CR15wi, CR15i & CR25ijyothivzgÎncă nu există evaluări
- XRD Machine For Clinker Quality AssessmentDocument4 paginiXRD Machine For Clinker Quality AssessmentApurba SarmaÎncă nu există evaluări
- KIIT University PPL (IT 401) PaperDocument5 paginiKIIT University PPL (IT 401) PaperHaritha GorijavoluÎncă nu există evaluări
- Geoview GuideDocument43 paginiGeoview GuidejyothsnasarikaÎncă nu există evaluări
- Learn How To Sequences Applications With App-V 5.1 Best Practices v2.0FDocument44 paginiLearn How To Sequences Applications With App-V 5.1 Best Practices v2.0FAjitabh279Încă nu există evaluări
- SQL AssignmentDocument2 paginiSQL AssignmentNiti Arora67% (3)
- Interview With Greg LynnDocument8 paginiInterview With Greg LynnbblqÎncă nu există evaluări
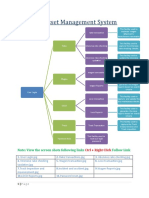
- Rail Asset Management System: Follow LinkDocument4 paginiRail Asset Management System: Follow LinkAbhiroop AwasthiÎncă nu există evaluări
- Compiler LabDocument23 paginiCompiler LabOlga RajeeÎncă nu există evaluări
- AVEVA ERM-Design Integration User Guide For AVEVA MarineDocument213 paginiAVEVA ERM-Design Integration User Guide For AVEVA Marinexxx100% (3)
- MN 123b 6100 099 VPad 623 Operators ManualDocument118 paginiMN 123b 6100 099 VPad 623 Operators ManualAbdalazeez AlsayedÎncă nu există evaluări
- NIM CommandsDocument4 paginiNIM CommandsSrinivas KumarÎncă nu există evaluări
- Office 365 Admin Center-L1Document12 paginiOffice 365 Admin Center-L1kushagra100% (1)
- Populating Time DimensionDocument39 paginiPopulating Time DimensionAmit SharmaÎncă nu există evaluări
- NOXON Iradio Technical Data GBDocument2 paginiNOXON Iradio Technical Data GBn3fwrÎncă nu există evaluări
- Website Vulnerability Scanner Sample Report OptimizedDocument11 paginiWebsite Vulnerability Scanner Sample Report OptimizedPauloÎncă nu există evaluări
- SafariDocument3 paginiSafariAntony MervinÎncă nu există evaluări
- Drawings and Reports Reference Data GuideDocument1.145 paginiDrawings and Reports Reference Data Guidelionstar0007Încă nu există evaluări
- CC Lab Manual - PART IDocument92 paginiCC Lab Manual - PART Ijagadeesh210802Încă nu există evaluări
- Dheeraj ThesisDocument73 paginiDheeraj ThesisAshish BharadeÎncă nu există evaluări
- Universityof Hertfordshire School of Physics, Engineering and Computer ScienceDocument4 paginiUniversityof Hertfordshire School of Physics, Engineering and Computer ScienceMuhammad AsadÎncă nu există evaluări
- SMC UserguideDocument132 paginiSMC Userguideatalasa-1Încă nu există evaluări