S-ar putea să vă placă și
- Project ManagementDocument23 paginiProject ManagementHugo Daniel RamirezÎncă nu există evaluări
- Business Service Management: What It Is and Why You Should CareDocument8 paginiBusiness Service Management: What It Is and Why You Should CareshirleyÎncă nu există evaluări
- ITIL Best PracticesDocument12 paginiITIL Best PracticesTariq GurooÎncă nu există evaluări
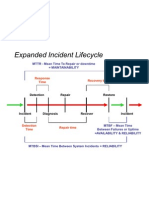
- Expanded Incident Lifecycle Slide - ITIL Incident ManagmentDocument1 paginăExpanded Incident Lifecycle Slide - ITIL Incident ManagmentTariq GurooÎncă nu există evaluări
- ICTIM Strategic Plan Slides With NotesDocument5 paginiICTIM Strategic Plan Slides With NotesTariq GurooÎncă nu există evaluări
- Whats New With Microsoft Data ProtectionDocument8 paginiWhats New With Microsoft Data ProtectionTariq GurooÎncă nu există evaluări
- SQL Server 2008 R2 Enterprise DatasheetDocument2 paginiSQL Server 2008 R2 Enterprise DatasheetTariq GurooÎncă nu există evaluări
- Ca Valueofprojectmanagementoffice 201174Document17 paginiCa Valueofprojectmanagementoffice 201174Aries Setya NugrahaÎncă nu există evaluări
- Oracle SOA Best Practices and Design PatternsDocument10 paginiOracle SOA Best Practices and Design PatternsalfonsjeÎncă nu există evaluări
- Khalil Gibran - The ProphetDocument35 paginiKhalil Gibran - The ProphetDreamyMoonÎncă nu există evaluări
- Summary of 29 Leadership SecretsDocument9 paginiSummary of 29 Leadership SecretsTariq GurooÎncă nu există evaluări
- The State of Requirements Management ReportDocument19 paginiThe State of Requirements Management ReportTariq GurooÎncă nu există evaluări
- The Interview BookDocument21 paginiThe Interview BookTariq Guroo67% (3)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5795)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Year 6 Week 1 Lesson 1 Main Focus Prior Knowledge Key Vocabulary Curriculum ObjectivesDocument19 paginiYear 6 Week 1 Lesson 1 Main Focus Prior Knowledge Key Vocabulary Curriculum Objectiveslenson kinyuaÎncă nu există evaluări
- Assignment 2Document33 paginiAssignment 2Yusra GulfamÎncă nu există evaluări
- ME100 Draft Report Evaluation, Group 2 Final ReportDocument2 paginiME100 Draft Report Evaluation, Group 2 Final ReportDavid WheatleÎncă nu există evaluări
- Setup Prometheus Monitoring On KubernetesDocument6 paginiSetup Prometheus Monitoring On KubernetesAymenÎncă nu există evaluări
- Epicor Price Checker FS A4 ENSDocument2 paginiEpicor Price Checker FS A4 ENSJuan Sebastián SánchezÎncă nu există evaluări
- Oopc++ Assignment G.Vaishnavi Btech Cse (2 Sem) ENR. NO:-A80105219022 Section:ADocument8 paginiOopc++ Assignment G.Vaishnavi Btech Cse (2 Sem) ENR. NO:-A80105219022 Section:ASanjana PulapaÎncă nu există evaluări
- Annexure XII Technical and Functional Specification PDFDocument11 paginiAnnexure XII Technical and Functional Specification PDFAndy_sumanÎncă nu există evaluări
- SX44Document4 paginiSX44Mk MakyÎncă nu există evaluări
- Cybersecurity and Physical Security ConvergenceDocument4 paginiCybersecurity and Physical Security ConvergenceDavid F MartinezÎncă nu există evaluări
- Intelligent Addressable Fire Alarm System: GeneralDocument10 paginiIntelligent Addressable Fire Alarm System: Generaleduardo gonzalezavÎncă nu există evaluări
- Capstone ProjectDocument29 paginiCapstone ProjectPrashant A UÎncă nu există evaluări
- Decision Analysis Using Microsoft Excel PDFDocument400 paginiDecision Analysis Using Microsoft Excel PDFimran_chaudhryÎncă nu există evaluări
- Internship Mechatronics EnglishDocument1 paginăInternship Mechatronics EnglishHassan KhalilÎncă nu există evaluări
- Aralin 1 - Dangal Sa PaggawaDocument27 paginiAralin 1 - Dangal Sa PaggawaPupung MartinezÎncă nu există evaluări
- Metron 05 C: Metal DetectorDocument10 paginiMetron 05 C: Metal DetectorPavelÎncă nu există evaluări
- Career Planning Resources - 2021-22Document1 paginăCareer Planning Resources - 2021-22Jessica NulphÎncă nu există evaluări
- DL7400 MaintenanceManualDocument157 paginiDL7400 MaintenanceManualIgor221987100% (1)
- Datasheet D7050 B6 Data Sheet enUS 2706872715Document2 paginiDatasheet D7050 B6 Data Sheet enUS 2706872715Waldemar Alvares RezendeÎncă nu există evaluări
- Remote Access PolicyDocument4 paginiRemote Access Policysolobreak05Încă nu există evaluări
- MIT 18.05 Exam 1 SolutionsDocument7 paginiMIT 18.05 Exam 1 SolutionsGoAwayScribdlolÎncă nu există evaluări
- WI - RRC CS Failure RateDocument3 paginiWI - RRC CS Failure Ratefidele50% (2)
- 027 Result Btech 7th Sem Jan 2023Document239 pagini027 Result Btech 7th Sem Jan 2023Vaibhav TiwariÎncă nu există evaluări
- G. Gevorgyan, M.markosyan+ C++Document229 paginiG. Gevorgyan, M.markosyan+ C++HaykÎncă nu există evaluări
- Ubd Application in WellfloDocument3 paginiUbd Application in WellfloAllan Troy SalazarÎncă nu există evaluări
- 1203 Weight Transmitter Reference Manual: For Use With Software Versions 1.0 and AboveDocument56 pagini1203 Weight Transmitter Reference Manual: For Use With Software Versions 1.0 and Abovesongs SomervilleÎncă nu există evaluări
- HB-2048-001 1099590 QIAgility Unpacking and Installation GuideDocument4 paginiHB-2048-001 1099590 QIAgility Unpacking and Installation GuideSHOBHAÎncă nu există evaluări
- Lec 5Document23 paginiLec 5Sama Atif Abdel-LatifÎncă nu există evaluări
- ANA Website Redesign FrameworkDocument1 paginăANA Website Redesign FrameworkDemand Metric100% (1)
- Terex Elrest SPSDocument20 paginiTerex Elrest SPSLuis jopi50% (2)
- OCL TutorialDocument3 paginiOCL Tutorialshahid_abdullahÎncă nu există evaluări