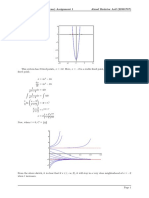
S-ar putea să vă placă și
- Solutions Manual For Mechanics and ThermodynamicsDocument112 paginiSolutions Manual For Mechanics and ThermodynamicsPaduraru Giani83% (24)
- Instructor's Manual to Accompany CALCULUS WITH ANALYTIC GEOMETRYDe la EverandInstructor's Manual to Accompany CALCULUS WITH ANALYTIC GEOMETRYÎncă nu există evaluări
- Answers to Selected Problems in Multivariable Calculus with Linear Algebra and SeriesDe la EverandAnswers to Selected Problems in Multivariable Calculus with Linear Algebra and SeriesEvaluare: 1.5 din 5 stele1.5/5 (2)
- Lesson Plan: Instructor: Date Topic: Grade Level: Subject ObjectivesDocument5 paginiLesson Plan: Instructor: Date Topic: Grade Level: Subject Objectivesapi-340265930Încă nu există evaluări
- Trefethen BauDocument29 paginiTrefethen BauHari Haran100% (1)
- Dynamic Postioning SystemDocument50 paginiDynamic Postioning Systempraveen_meo1Încă nu există evaluări
- Lp-7 2019-Ratio and ProportionDocument5 paginiLp-7 2019-Ratio and Proportionroy c. diocampoÎncă nu există evaluări
- Mixed Methods Research PDFDocument14 paginiMixed Methods Research PDFChin Ing KhangÎncă nu există evaluări
- MATH 6 Q4 Module 8Document17 paginiMATH 6 Q4 Module 8Amor DionisioÎncă nu există evaluări
- Gd&t-Multi MetricsDocument356 paginiGd&t-Multi MetricsdramiltÎncă nu există evaluări
- Developing An OutlineDocument18 paginiDeveloping An OutlineEnrico Dela CruzÎncă nu există evaluări
- Clustering Case Study: Forest Cover TypesDocument10 paginiClustering Case Study: Forest Cover TypesAlee LópezÎncă nu există evaluări
- Simpson's 1/3 Rule For Integration-More Examples Electrical EngineeringDocument4 paginiSimpson's 1/3 Rule For Integration-More Examples Electrical EngineeringMario Cesgo SolizÎncă nu există evaluări
- Second Mid-Term Examination (23%) Vii Sem, 2018 - 19Document2 paginiSecond Mid-Term Examination (23%) Vii Sem, 2018 - 19Kartik ModiÎncă nu există evaluări
- Mid Sem Exam 2021-22Document2 paginiMid Sem Exam 2021-22N Rabindra PatraÎncă nu există evaluări
- Full Download Fundamentals of Communication Systems 2nd Edition Proakis Solutions ManualDocument36 paginiFull Download Fundamentals of Communication Systems 2nd Edition Proakis Solutions Manualgiaourgaolbi23a100% (38)
- Signals and System: Lab Sheet - 4Document5 paginiSignals and System: Lab Sheet - 4Shravan Kumar LuitelÎncă nu există evaluări
- A3 - Earthquake - Ce4-3 - Aningga, John LinardDocument5 paginiA3 - Earthquake - Ce4-3 - Aningga, John LinardJohn Linard AninggaÎncă nu există evaluări
- Sistem Digital ADocument28 paginiSistem Digital AmengkaanÎncă nu există evaluări
- Desain Rangkain KombinasionalDocument28 paginiDesain Rangkain KombinasionalIntanSarahitaNÎncă nu există evaluări
- Generating and Processing Random SignalsDocument56 paginiGenerating and Processing Random SignalssamfgÎncă nu există evaluări
- Sss - Termodinamica IIDocument78 paginiSss - Termodinamica IIBrankÎncă nu există evaluări
- Lec08 2015Document42 paginiLec08 2015Abdelmajid AbouloifaÎncă nu există evaluări
- Machine Learning Foundations and Applications Assignment 1 Due Date: 10 October, 2021Document3 paginiMachine Learning Foundations and Applications Assignment 1 Due Date: 10 October, 2021AYAN KUMARÎncă nu există evaluări
- Y (S) U (S)Document5 paginiY (S) U (S)Luis CarvalhoÎncă nu există evaluări
- Assignment 1 MAT323 (22301787)Document5 paginiAssignment 1 MAT323 (22301787)Ahnaf ShahriarÎncă nu există evaluări
- Root Locus MethodDocument25 paginiRoot Locus MethodHAMID SULIAMANÎncă nu există evaluări
- EE Comp MATLAB Activity 3Document8 paginiEE Comp MATLAB Activity 3Reneboy LambarteÎncă nu există evaluări
- Additional Exercises For Vectors, Matrices, and Least SquaresDocument41 paginiAdditional Exercises For Vectors, Matrices, and Least SquaresAlejandro Patiño RiveraÎncă nu există evaluări
- ProblemsDocument46 paginiProblemsgaur1234Încă nu există evaluări
- Sample Midterm #2Document7 paginiSample Midterm #2sharadpjadhavÎncă nu există evaluări
- Checking, Selecting & Predicting With Gams: Mathematical Sciences, University of Bath, U.KDocument21 paginiChecking, Selecting & Predicting With Gams: Mathematical Sciences, University of Bath, U.KKiril IvanovÎncă nu există evaluări
- Y X1 X2 X1rata X2rata x1 x2 Y1: RegressionDocument4 paginiY X1 X2 X1rata X2rata x1 x2 Y1: RegressionZaira AdiliaÎncă nu există evaluări
- Dwnload Full Fundamentals of Communication Systems 2nd Edition Proakis Solutions Manual PDFDocument36 paginiDwnload Full Fundamentals of Communication Systems 2nd Edition Proakis Solutions Manual PDFbecurl.poitrel56ls100% (9)
- Pages by Bose-DigitalDocument15 paginiPages by Bose-DigitalJenny VarelaÎncă nu există evaluări
- Example:1: A.Circular Shift: All AllDocument28 paginiExample:1: A.Circular Shift: All AllJarin TasnimÎncă nu există evaluări
- Marking Guideline: Mathematics N4Document9 paginiMarking Guideline: Mathematics N4nathanielÎncă nu există evaluări
- Power System Analysis: Newton-Raphson Power FlowDocument44 paginiPower System Analysis: Newton-Raphson Power FlowPenny87Încă nu există evaluări
- NyquistDocument12 paginiNyquistOsel Novandi WitohendroÎncă nu există evaluări
- There Are 4 PacketsDocument3 paginiThere Are 4 Packetsrajneesh tetarwalÎncă nu există evaluări
- Example 1Document2 paginiExample 1MY LIFE MY WORDSÎncă nu există evaluări
- Problems Answers PDFDocument13 paginiProblems Answers PDFHussein ElattarÎncă nu există evaluări
- Method 1: IB Questionbank Mathematics Higher Level 3rd Edition 1Document12 paginiMethod 1: IB Questionbank Mathematics Higher Level 3rd Edition 1LeilaVoscoboynicovaÎncă nu există evaluări
- Expected Output For Lecture L3 Codes: 1 Consider The Systems and SignalsDocument10 paginiExpected Output For Lecture L3 Codes: 1 Consider The Systems and SignalsMiguel Angel Segura FigueroaÎncă nu există evaluări
- Deney 1: Yıldız Teknik Üniversitesi Yapı Stati I IIDocument5 paginiDeney 1: Yıldız Teknik Üniversitesi Yapı Stati I IIbekir aslanÎncă nu există evaluări
- Control System Design Course Work LLDocument9 paginiControl System Design Course Work LLSaqib NaseerÎncă nu există evaluări
- Control Systems I Exercise Set 9: Learning Objectives: The Student CanDocument6 paginiControl Systems I Exercise Set 9: Learning Objectives: The Student CanArmando MaloneÎncă nu există evaluări
- Notes 5 - Stability 1Document23 paginiNotes 5 - Stability 1lili aboudÎncă nu există evaluări
- Ejercicios Nyquist 2 PDFDocument10 paginiEjercicios Nyquist 2 PDFpepe gomezÎncă nu există evaluări
- Examen2 de Wilson y NRTLDocument78 paginiExamen2 de Wilson y NRTLafsasfÎncă nu există evaluări
- C4Document20 paginiC4Joseph LeeÎncă nu există evaluări
- Skee 2263 Final Exam 1718-2 SDocument17 paginiSkee 2263 Final Exam 1718-2 SNG JIAN RONG A20EE0177Încă nu există evaluări
- 06 LPPDocument21 pagini06 LPPyogesh jadhavÎncă nu există evaluări
- 2D Frame Analysis: Analysis of A 2D Frame Subject To Distributed Loads, Point Loads and MomentsDocument26 pagini2D Frame Analysis: Analysis of A 2D Frame Subject To Distributed Loads, Point Loads and MomentsJohnclaude ChamandiÎncă nu există evaluări
- Experimental Report 2Document7 paginiExperimental Report 2Nghĩa MaiÎncă nu există evaluări
- 2D Frame Analysis: Analysis of A 2D Frame Subject To Distributed Loads, Point Loads and MomentsDocument26 pagini2D Frame Analysis: Analysis of A 2D Frame Subject To Distributed Loads, Point Loads and MomentsAdi SetiawanÎncă nu există evaluări
- 2D Frame Analysis: Analysis of A 2D Frame Subject To Distributed Loads, Point Loads and MomentsDocument26 pagini2D Frame Analysis: Analysis of A 2D Frame Subject To Distributed Loads, Point Loads and Momentstham leoÎncă nu există evaluări
- 2D Frame Analysis: Analysis of A 2D Frame Subject To Distributed Loads, Point Loads and MomentsDocument26 pagini2D Frame Analysis: Analysis of A 2D Frame Subject To Distributed Loads, Point Loads and Momentssmartz inspectionÎncă nu există evaluări
- 2D Frame Analysis: Analysis of A 2D Frame Subject To Distributed Loads, Point Loads and MomentsDocument26 pagini2D Frame Analysis: Analysis of A 2D Frame Subject To Distributed Loads, Point Loads and MomentsAtm Tjah Radix LoegoeÎncă nu există evaluări
- 2D Frame Analysis: Analysis of A 2D Frame Subject To Distributed Loads, Point Loads and MomentsDocument26 pagini2D Frame Analysis: Analysis of A 2D Frame Subject To Distributed Loads, Point Loads and MomentsGelbert SilotÎncă nu există evaluări
- Adaptive Control 2nd. Edt. by Karl.J.astrom - Solution ManuelDocument46 paginiAdaptive Control 2nd. Edt. by Karl.J.astrom - Solution Manuelvervesolar33% (3)
- Government Publications: Key PapersDe la EverandGovernment Publications: Key PapersBernard M. FryÎncă nu există evaluări
- Modular Forms and Special Cycles on Shimura Curves. (AM-161)De la EverandModular Forms and Special Cycles on Shimura Curves. (AM-161)Încă nu există evaluări
- Software VNA and Microwave Network Design and CharacterisationDe la EverandSoftware VNA and Microwave Network Design and CharacterisationÎncă nu există evaluări
- Tables of the Function w (z)- e-z2 ? ex2 dx: Mathematical Tables Series, Vol. 27De la EverandTables of the Function w (z)- e-z2 ? ex2 dx: Mathematical Tables Series, Vol. 27Încă nu există evaluări
- Y625U - PCB Board Diagram PDFDocument2 paginiY625U - PCB Board Diagram PDFAlee LópezÎncă nu există evaluări
- Supervised Hebbian LearningDocument14 paginiSupervised Hebbian LearningAlee LópezÎncă nu există evaluări
- Ch9 Presnedit PDFDocument22 paginiCh9 Presnedit PDFAlee LópezÎncă nu există evaluări
- Prediction Case Study: Magnetic LevitationDocument15 paginiPrediction Case Study: Magnetic LevitationAlee LópezÎncă nu există evaluări
- Ch8 Presn PDFDocument24 paginiCh8 Presn PDFAlee LópezÎncă nu există evaluări
- Ch9 Presn PDFDocument22 paginiCh9 Presn PDFAlee LópezÎncă nu există evaluări
- Widrow-Hoff Learning: (LMS Algorithm)Document26 paginiWidrow-Hoff Learning: (LMS Algorithm)Alee LópezÎncă nu există evaluări
- Ch6 Presn PDFDocument24 paginiCh6 Presn PDFAlee LópezÎncă nu există evaluări
- Pattern Recognition Case Study: EKG AnalysisDocument14 paginiPattern Recognition Case Study: EKG AnalysisAlee LópezÎncă nu există evaluări
- Widrow-Hoff Learning: (LMS Algorithm)Document26 paginiWidrow-Hoff Learning: (LMS Algorithm)Alee LópezÎncă nu există evaluări
- Ch17 Presn PDFDocument29 paginiCh17 Presn PDFAlee LópezÎncă nu există evaluări
- Ch14 Presn PDFDocument47 paginiCh14 Presn PDFAlee LópezÎncă nu există evaluări
- Ch19 Presn PDFDocument30 paginiCh19 Presn PDFAlee LópezÎncă nu există evaluări
- Probability Estimation Case Study: Molecular DynamicsDocument15 paginiProbability Estimation Case Study: Molecular DynamicsAlee LópezÎncă nu există evaluări
- Ch12 Presn PDFDocument31 paginiCh12 Presn PDFAlee LópezÎncă nu există evaluări
- Ch22 Presn PDFDocument34 paginiCh22 Presn PDFAlee LópezÎncă nu există evaluări
- Kaizen Idea - Sheet: Suitable Chairs To Write Their Notes Faster & Easy Method While TrainingDocument1 paginăKaizen Idea - Sheet: Suitable Chairs To Write Their Notes Faster & Easy Method While TrainingWahid AkramÎncă nu există evaluări
- Types of Dance Steps and Positions PDFDocument11 paginiTypes of Dance Steps and Positions PDFRather NotÎncă nu există evaluări
- Collaborative Planning Template W CaptionDocument5 paginiCollaborative Planning Template W Captionapi-297728751Încă nu există evaluări
- What Are The Subjects Which Come in UPSC Engineering Services - Electronics - Communication - ExamDocument2 paginiWhat Are The Subjects Which Come in UPSC Engineering Services - Electronics - Communication - ExamVikas ChandraÎncă nu există evaluări
- The Seven Perceptual Learning StylesDocument3 paginiThe Seven Perceptual Learning StylesRamona FloreaÎncă nu există evaluări
- Unliquidated Cash Advances 3rd Quarter 2020Document10 paginiUnliquidated Cash Advances 3rd Quarter 2020kQy267BdTKÎncă nu există evaluări
- Matte Sanjeev Kumar: Professional SummaryDocument3 paginiMatte Sanjeev Kumar: Professional SummaryAlla VijayÎncă nu există evaluări
- Lesson Plan ComsumerismDocument6 paginiLesson Plan ComsumerismMan Eugenia50% (4)
- L53 & L54 Environmental Impact Assessment (Eng) - WebDocument31 paginiL53 & L54 Environmental Impact Assessment (Eng) - WebplyanaÎncă nu există evaluări
- Normality in The Residual - Hossain Academy NoteDocument2 paginiNormality in The Residual - Hossain Academy NoteAbdullah KhatibÎncă nu există evaluări
- For Purposeful and Meaningful Technology Integration in The ClassroomDocument19 paginiFor Purposeful and Meaningful Technology Integration in The ClassroomVincent Chris Ellis TumaleÎncă nu există evaluări
- Comparision BRC IFS QMS 22K From BV PDFDocument44 paginiComparision BRC IFS QMS 22K From BV PDFAhmedElSayedÎncă nu există evaluări
- Momi BhattacharyaDocument59 paginiMomi BhattacharyamohchinbokhtiyarÎncă nu există evaluări
- How To Group Currency PDFDocument3 paginiHow To Group Currency PDFanon_909438945Încă nu există evaluări
- Agents SocializationDocument4 paginiAgents Socializationinstinct920% (1)
- Shape The Future Listening Practice - Unit 3 - Without AnswersDocument1 paginăShape The Future Listening Practice - Unit 3 - Without Answersleireleire20070701Încă nu există evaluări
- SugaNate 160NCDocument5 paginiSugaNate 160NCmndmattÎncă nu există evaluări
- Oliver vs. Philippine Savings BankDocument14 paginiOliver vs. Philippine Savings BankAmeir MuksanÎncă nu există evaluări
- B.tech - Non Credit Courses For 2nd Year StudentsDocument4 paginiB.tech - Non Credit Courses For 2nd Year StudentsNishant MishraÎncă nu există evaluări
- People in Organization: Group - 6Document8 paginiPeople in Organization: Group - 6rennys amaliaÎncă nu există evaluări
- Rehabilitation Programs On The Behavior of Juveniles in Manga Children's Remand Home, Nyamira County - KenyaDocument7 paginiRehabilitation Programs On The Behavior of Juveniles in Manga Children's Remand Home, Nyamira County - KenyaInternational Journal of Innovative Science and Research TechnologyÎncă nu există evaluări
- Semi-Conductor Laboratory - MohaliDocument4 paginiSemi-Conductor Laboratory - MohalimanjnderÎncă nu există evaluări
- Sample Test Paper 2012 NucleusDocument14 paginiSample Test Paper 2012 NucleusVikramÎncă nu există evaluări