S-ar putea să vă placă și
- Algorithmic Complexity Analysis GuideDocument13 paginiAlgorithmic Complexity Analysis Guidesarala devi100% (1)
- Lecture Notes On Sorting: 15-122: Principles of Imperative Computation Frank Pfenning September 18, 2012Document12 paginiLecture Notes On Sorting: 15-122: Principles of Imperative Computation Frank Pfenning September 18, 2012Pradipta PaulÎncă nu există evaluări
- 775 PDFsam PythonNotesForProfessionalsDocument1 pagină775 PDFsam PythonNotesForProfessionalsFabricioÎncă nu există evaluări
- Asymptotic Time ComplexityDocument2 paginiAsymptotic Time ComplexityDeepraj BaidyaÎncă nu există evaluări
- Dsa 1Document9 paginiDsa 1Abraham GebeyehuÎncă nu există evaluări
- Analyzing Code with Θ, O and Ω: 1 DefinitionsDocument18 paginiAnalyzing Code with Θ, O and Ω: 1 DefinitionsPeter Okidi Agara OyoÎncă nu există evaluări
- DAA Sem ANSDocument70 paginiDAA Sem ANSdannic1405100% (1)
- DS Unit 4Document21 paginiDS Unit 4DevadharshiniÎncă nu există evaluări
- Order of Complexity AnalysisDocument9 paginiOrder of Complexity AnalysisMusic LifeÎncă nu există evaluări
- 01 DS Quiz SetDocument109 pagini01 DS Quiz Setvinay harshaÎncă nu există evaluări
- Chapter 5 Algorithmic ComplexityDocument4 paginiChapter 5 Algorithmic ComplexityKhalifaÎncă nu există evaluări
- Daa QbaDocument48 paginiDaa QbaDurga KÎncă nu există evaluări
- Asymptotic NotationsDocument11 paginiAsymptotic NotationsKavitha Kottuppally RajappanÎncă nu există evaluări
- Algos Cs Cmu EduDocument15 paginiAlgos Cs Cmu EduRavi Chandra Reddy MuliÎncă nu există evaluări
- Module 1 AADDocument9 paginiModule 1 AADcahebevÎncă nu există evaluări
- Data Structures and Algorithms (DSA) - CroppedDocument380 paginiData Structures and Algorithms (DSA) - CroppedSwayam GosaviÎncă nu există evaluări
- Advanced Algorithms & Data Structures: Lecturer: Karimzhan Nurlan BerlibekulyDocument31 paginiAdvanced Algorithms & Data Structures: Lecturer: Karimzhan Nurlan BerlibekulyNaski KuafniÎncă nu există evaluări
- What Is Asymptotic NotationDocument51 paginiWhat Is Asymptotic NotationHemalatha SivakumarÎncă nu există evaluări
- notes on aymptotic notationDocument11 pagininotes on aymptotic notationshift2cs22Încă nu există evaluări
- Datastructuers and Algorithms in C++Document5 paginiDatastructuers and Algorithms in C++sachin kumar shawÎncă nu există evaluări
- Algorithmic ComplexityDocument5 paginiAlgorithmic ComplexityJulius ColminasÎncă nu există evaluări
- 01 Introduction To Asymptotic Analysis and Big O - Data Structures For Coding Interviews in C#Document7 pagini01 Introduction To Asymptotic Analysis and Big O - Data Structures For Coding Interviews in C#Farmer MÎncă nu există evaluări
- Unit 1: Daa Two Mark Question and Answer 1Document22 paginiUnit 1: Daa Two Mark Question and Answer 1Raja RajanÎncă nu există evaluări
- Big O Notation PDFDocument9 paginiBig O Notation PDFravigobiÎncă nu există evaluări
- Module 3 - Complexity of An AlgorithmDocument7 paginiModule 3 - Complexity of An AlgorithmarturogallardoedÎncă nu există evaluări
- Week2 - Growth of FunctionsDocument64 paginiWeek2 - Growth of FunctionsFahama Bin EkramÎncă nu există evaluări
- Algorithm AnalysisDocument82 paginiAlgorithm AnalysisbeenagodbinÎncă nu există evaluări
- Analysis of Algorithms - Set 3 (Asymptotic Notations)Document14 paginiAnalysis of Algorithms - Set 3 (Asymptotic Notations)Shahzael MughalÎncă nu există evaluări
- 20MCA023 Algorithm AssighnmentDocument13 pagini20MCA023 Algorithm AssighnmentPratik KakaniÎncă nu există evaluări
- Asymptotic Notations: 1) Θ Notation: The theta notation bounds a functions from above and below, so itDocument9 paginiAsymptotic Notations: 1) Θ Notation: The theta notation bounds a functions from above and below, so itDeepak ChaudharyÎncă nu există evaluări
- Algorithmic Designing: Unit 1-1. Time and Space ComplexityDocument5 paginiAlgorithmic Designing: Unit 1-1. Time and Space ComplexityPratik KakaniÎncă nu există evaluări
- Algorithm Analysis NewDocument8 paginiAlgorithm Analysis NewMelatÎncă nu există evaluări
- Lecture 3 1Document34 paginiLecture 3 1hallertjohnÎncă nu există evaluări
- Big ODocument9 paginiBig OJerome DeiparineÎncă nu există evaluări
- CMSC 451: Lecture 1 Introduction To Algorithm Design: Tuesday, Aug 29, 2017Document4 paginiCMSC 451: Lecture 1 Introduction To Algorithm Design: Tuesday, Aug 29, 2017Anthony-Dimitri AÎncă nu există evaluări
- Mount 451 2017Document202 paginiMount 451 2017Anthony-Dimitri AÎncă nu există evaluări
- DAA Unit 1,2,3-1 (1)Document46 paginiDAA Unit 1,2,3-1 (1)abdulshahed231Încă nu există evaluări
- DAA Sheet04Document3 paginiDAA Sheet04omar magdyÎncă nu există evaluări
- AlgorithmDocument12 paginiAlgorithmSahista MachchharÎncă nu există evaluări
- 05 Algorithm AnalysisDocument29 pagini05 Algorithm AnalysisDavid TangÎncă nu există evaluări
- CS 211 Discrete Math Assignment GuideDocument4 paginiCS 211 Discrete Math Assignment GuideMalik Ghulam HurÎncă nu există evaluări
- Asymptotic Notation ExplainedDocument112 paginiAsymptotic Notation Explained36rajnee kantÎncă nu există evaluări
- Upload Test123Document4 paginiUpload Test123Nabin ThapaÎncă nu există evaluări
- Analysis of Algorithms: Θ, O, Ω NotationsDocument4 paginiAnalysis of Algorithms: Θ, O, Ω NotationsNabin ThapaÎncă nu există evaluări
- Performance Comparison of Sorting Algorithms Based on ComplexityDocument5 paginiPerformance Comparison of Sorting Algorithms Based on ComplexityanvinderÎncă nu există evaluări
- Estimating time complexity with Big O, Θ, and Ω notationsDocument9 paginiEstimating time complexity with Big O, Θ, and Ω notationsLovely ChinnaÎncă nu există evaluări
- Ada 1Document11 paginiAda 1kavithaangappanÎncă nu există evaluări
- Computer Science Notes: Algorithms and Data StructuresDocument21 paginiComputer Science Notes: Algorithms and Data StructuresMuhammedÎncă nu există evaluări
- Brief ComplexityDocument3 paginiBrief ComplexitySridhar ChandrasekarÎncă nu există evaluări
- cs330 10 Notes PDFDocument204 paginics330 10 Notes PDFasifmechengrÎncă nu există evaluări
- 2 MarksDocument16 pagini2 MarkssiswariyaÎncă nu există evaluări
- (DCTR. (AWAIS) Assignent No 02 (3rd Semester) (DSC) (Bsse) (Morning B) (GCUF)Document11 pagini(DCTR. (AWAIS) Assignent No 02 (3rd Semester) (DSC) (Bsse) (Morning B) (GCUF)Umran JabbarÎncă nu există evaluări
- Daa Notes FullDocument55 paginiDaa Notes FullAarif MuhammedÎncă nu există evaluări
- Algo AnalysisDocument24 paginiAlgo AnalysisAman QureshiÎncă nu există evaluări
- Algorithms Performance AnalysisDocument11 paginiAlgorithms Performance Analysisprerna kanawadeÎncă nu există evaluări
- 3 - Algorithmic ComplexityDocument28 pagini3 - Algorithmic ComplexityShakir khanÎncă nu există evaluări
- Algorithm and Method AssignmentDocument8 paginiAlgorithm and Method AssignmentOm SharmaÎncă nu există evaluări
- CSE2003 Data Structures and AlgorithmsDocument37 paginiCSE2003 Data Structures and AlgorithmsShalni PandeyÎncă nu există evaluări
- Electric ConductionDocument24 paginiElectric ConductionXenonÎncă nu există evaluări
- Sms Transaction PracticesDocument16 paginiSms Transaction PracticesAnkiTwilightedÎncă nu există evaluări
- The Analysis of The Sms TransactionDocument2 paginiThe Analysis of The Sms TransactionAnkiTwilightedÎncă nu există evaluări
- PollutionDocument2 paginiPollutionAnkiTwilightedÎncă nu există evaluări
- Leap Motion PDFDocument18 paginiLeap Motion PDFAnkiTwilightedÎncă nu există evaluări
- E Payment SystemDocument56 paginiE Payment SystemAnkiTwilightedÎncă nu există evaluări
- Maths SET THEORYDocument3 paginiMaths SET THEORYAnkiTwilightedÎncă nu există evaluări
- Scenario Class Discussion ProgramsDocument1 paginăScenario Class Discussion ProgramsAnkiTwilightedÎncă nu există evaluări
- Lecture Notes Data Structures CSC-214Document90 paginiLecture Notes Data Structures CSC-214vikasÎncă nu există evaluări
- CDocument20 paginiCAnkiTwilightedÎncă nu există evaluări
- Bubble Sort in CDocument1 paginăBubble Sort in CNishant SawantÎncă nu există evaluări
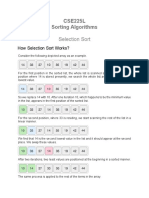
- CSE225L Sorting Algorithms: Selection SortDocument8 paginiCSE225L Sorting Algorithms: Selection SortNilima Ayoub DiptyÎncă nu există evaluări
- In Place Sorting Vs Out Place SortingDocument2 paginiIn Place Sorting Vs Out Place SortingSmart Life ShÎncă nu există evaluări
- Sorting Algorithms ExplainedDocument27 paginiSorting Algorithms ExplainedMeer MusahibÎncă nu există evaluări
- Parallel Sorting AlgorithmsDocument7 paginiParallel Sorting Algorithmsttww1254100% (1)
- 07 SortingC QuickSortDocument197 pagini07 SortingC QuickSortlukilukiÎncă nu există evaluări
- Bubble SortDocument108 paginiBubble SortDivyaPatelÎncă nu există evaluări
- Merge Sort Algorithm ExplainedDocument7 paginiMerge Sort Algorithm ExplainedLn Amitav BiswasÎncă nu există evaluări
- Sort em PythonDocument5 paginiSort em PythonadrianoucamÎncă nu există evaluări
- Merge SortDocument13 paginiMerge SortShubham KumarÎncă nu există evaluări
- Advanced Topics in SortingDocument36 paginiAdvanced Topics in SortingSergeÎncă nu există evaluări
- SortingDocument22 paginiSortingayush Baiswar WIqFuKAHXxÎncă nu există evaluări
- Insertion Sort Analysis: Analysis of Algorithm Lecture # 6 Mariha AsadDocument8 paginiInsertion Sort Analysis: Analysis of Algorithm Lecture # 6 Mariha AsadaatiqasaleemÎncă nu există evaluări
- Selection Sort Algorithm in ProgrammingDocument6 paginiSelection Sort Algorithm in ProgrammingJeffer MwangiÎncă nu există evaluări
- Selection SortDocument16 paginiSelection SortMAXIÎncă nu există evaluări
- Quicksort OptimizacijaDocument2 paginiQuicksort OptimizacijaFilip MeštrovićÎncă nu există evaluări
- Java Heap Sort Algorithm ImplementationDocument3 paginiJava Heap Sort Algorithm ImplementationByronPérezÎncă nu există evaluări
- M Labexer5 Sacasas ElizaldeDocument13 paginiM Labexer5 Sacasas Elizaldeapi-565917483Încă nu există evaluări
- BigoposterDocument1 paginăBigoposterKim MonzonÎncă nu există evaluări
- Factorial Program: For Particular NumberDocument17 paginiFactorial Program: For Particular NumberKaushik Karthikeyan KÎncă nu există evaluări
- 5 - Sorting and Searching AlgorithmDocument35 pagini5 - Sorting and Searching AlgorithmHard FuckerÎncă nu există evaluări
- Comb SortingDocument10 paginiComb SortingAliRahmanÎncă nu există evaluări
- Java Source CodeDocument11 paginiJava Source CodeDarko JakovleskiÎncă nu există evaluări
- Unit-2: Searching, Sorting, Linked Lists: 2M QuestionsDocument34 paginiUnit-2: Searching, Sorting, Linked Lists: 2M QuestionssirishaÎncă nu există evaluări
- Lec9a SpaceComplexDocument19 paginiLec9a SpaceComplexSIMRAN SEHGALÎncă nu există evaluări
- Bubble Sort (With Code in Python-C++-Java-C)Document12 paginiBubble Sort (With Code in Python-C++-Java-C)Thee KullateeÎncă nu există evaluări
- Merge Sort Quick SortDocument43 paginiMerge Sort Quick SortTudor TilinschiÎncă nu există evaluări
- Week 11 & 12: Sorting: Data Structures & Algorithm AnalysisDocument88 paginiWeek 11 & 12: Sorting: Data Structures & Algorithm AnalysisAmimul IhsanÎncă nu există evaluări
- Big-O Algorithm Complexity Cheat Sheet PDFDocument1 paginăBig-O Algorithm Complexity Cheat Sheet PDFbhavana manglikÎncă nu există evaluări
- CSN-212 Algorithms Sorting Techniques TutorialDocument3 paginiCSN-212 Algorithms Sorting Techniques TutorialROHIT RAJÎncă nu există evaluări