S-ar putea să vă placă și
- Housing Prices SolutionDocument9 paginiHousing Prices SolutionAseem SwainÎncă nu există evaluări
- House Price - PredictionDocument4 paginiHouse Price - PredictionManjunathd DÎncă nu există evaluări
- Serv LetsDocument17 paginiServ LetsSaujanya AnanthaprasadÎncă nu există evaluări
- General Principles of Food Hygiene CXC 1-1969Document35 paginiGeneral Principles of Food Hygiene CXC 1-1969Duy NguyenÎncă nu există evaluări
- Adv Java1Document281 paginiAdv Java1Rajan KadamÎncă nu există evaluări
- 1.1 Scope: 3.1.1 Login ModuleDocument59 pagini1.1 Scope: 3.1.1 Login ModuleShivang SethiyaÎncă nu există evaluări
- 07 The NetBeans E-Commerce Tutorial - Adding Entity Classes and Session BeansDocument23 pagini07 The NetBeans E-Commerce Tutorial - Adding Entity Classes and Session BeansJavier CaniparoliÎncă nu există evaluări
- 022 Price and Location PDFDocument16 pagini022 Price and Location PDFTman LetswaloÎncă nu există evaluări
- Credit Management Trascation SystemDocument37 paginiCredit Management Trascation SystemNishaan NishaanÎncă nu există evaluări
- NetBeans Platform Login TutorialDocument27 paginiNetBeans Platform Login TutorialAftab Alam Afridi100% (2)
- Brick Game: Midterm Report ONDocument12 paginiBrick Game: Midterm Report ONManwinder Singh GillÎncă nu există evaluări
- Application of LSS To Improve Service in Healthcare Facilities ManagementDocument62 paginiApplication of LSS To Improve Service in Healthcare Facilities ManagementMiguelÎncă nu există evaluări
- OnlineDocument15 paginiOnlineAshish GautamÎncă nu există evaluări
- 1 IntroductionDocument47 pagini1 Introductionking moon504Încă nu există evaluări
- Example of Servlet Chaining?Document38 paginiExample of Servlet Chaining?Ajit Kumar GuptaÎncă nu există evaluări
- Software Testing ImpDocument52 paginiSoftware Testing ImpPinky ChandaÎncă nu există evaluări
- Abattoir Wastes Generation, Management and The Environment A Case of Minna, North Central NigeriaDocument10 paginiAbattoir Wastes Generation, Management and The Environment A Case of Minna, North Central NigeriaAnowar RazvyÎncă nu există evaluări
- 08 AgileLegacy Keynote SlidesDocument60 pagini08 AgileLegacy Keynote SlidesMeeaowwÎncă nu există evaluări
- How To Create Multiple User Login Form in Java Using MySQL Database and NetBeans IDEDocument8 paginiHow To Create Multiple User Login Form in Java Using MySQL Database and NetBeans IDEFranciz CastilloÎncă nu există evaluări
- Java Servlet Tutorial - The ULTIMATE Guide (PDF Download)Document18 paginiJava Servlet Tutorial - The ULTIMATE Guide (PDF Download)tolmousÎncă nu există evaluări
- Load Performance Test PlanDocument8 paginiLoad Performance Test Planapi-3736193Încă nu există evaluări
- Introduction To Developing Web Applications - NetBeans IDE Tutorial PDFDocument8 paginiIntroduction To Developing Web Applications - NetBeans IDE Tutorial PDFItzel RM100% (1)
- CHP191 - IET600-ITT600 For IEC 61850 Integration & Testing - System EngineeringDocument2 paginiCHP191 - IET600-ITT600 For IEC 61850 Integration & Testing - System EngineeringMichael Parohinog GregasÎncă nu există evaluări
- Data Science BluePrintDocument12 paginiData Science BluePrintmikeÎncă nu există evaluări
- 6 Tips System Integration Testing WhitepaperDocument4 pagini6 Tips System Integration Testing WhitepaperRemus CalinaÎncă nu există evaluări
- Visvesvaraya Technological University: K.S.Institute of TechnologyDocument38 paginiVisvesvaraya Technological University: K.S.Institute of TechnologyRekha VenkatpuraÎncă nu există evaluări
- How To Take RMAN Full Backup Using Shell Scrip1Document5 paginiHow To Take RMAN Full Backup Using Shell Scrip1Sopan sonarÎncă nu există evaluări
- Basics of Software Testing Part 1Document23 paginiBasics of Software Testing Part 1vidyaÎncă nu există evaluări
- WorldQuant TutorialDocument14 paginiWorldQuant TutorialParth GaglaniÎncă nu există evaluări
- MAHE Prospectus 2020Document353 paginiMAHE Prospectus 2020Kirthinath BallalÎncă nu există evaluări
- Software Process ModelsDocument9 paginiSoftware Process Modelsmounit121Încă nu există evaluări
- What Are The Significant Changes in Upgrades in Various Selenium Versions?Document6 paginiWhat Are The Significant Changes in Upgrades in Various Selenium Versions?Rajeshree KaluskarÎncă nu există evaluări
- Software Testing Project 7Document33 paginiSoftware Testing Project 7Taha KajolÎncă nu există evaluări
- Restful Web Services Tutorial: What Is Rest Architecture?Document17 paginiRestful Web Services Tutorial: What Is Rest Architecture?Krish GÎncă nu există evaluări
- Pine Script v5 User ManualDocument509 paginiPine Script v5 User Manualtavo2014Încă nu există evaluări
- 1.1. Overview of System X: Development ProjectDocument17 pagini1.1. Overview of System X: Development Projectmathewk000Încă nu există evaluări
- Here Are Your ResultsDocument72 paginiHere Are Your ResultsfransyunetÎncă nu există evaluări
- What Is Tidal Enterprise SchedulerDocument9 paginiWhat Is Tidal Enterprise SchedulerYamunaÎncă nu există evaluări
- Course 6232B Microsoft SQL ServerDocument3 paginiCourse 6232B Microsoft SQL ServercmoscuÎncă nu există evaluări
- Database Testing: Gourav Mehta (Associate QA Engineer)Document12 paginiDatabase Testing: Gourav Mehta (Associate QA Engineer)pattabirmnÎncă nu există evaluări
- Testing 1Document12 paginiTesting 1so28081986Încă nu există evaluări
- Selenium Recipes in JavaDocument58 paginiSelenium Recipes in JavaSuruBabuThalupuruÎncă nu există evaluări
- Software Development Life CycleDocument8 paginiSoftware Development Life Cycleapi-320326008Încă nu există evaluări
- Chapter 2 - Business Problem FramingDocument6 paginiChapter 2 - Business Problem FramingLuis Carlos PeñaÎncă nu există evaluări
- Testing & SDLC BasicsDocument23 paginiTesting & SDLC BasicsSandeep BennyÎncă nu există evaluări
- Design and Implementation of Course RegiDocument54 paginiDesign and Implementation of Course RegiAdym AymdÎncă nu există evaluări
- Type ScriptDocument1 paginăType Scriptkasim100% (1)
- IntegrationDocument12 paginiIntegrationYogendra RajavatÎncă nu există evaluări
- Business Process Modeling: IBM Sterling B2B IntegratorDocument108 paginiBusiness Process Modeling: IBM Sterling B2B IntegratorJContreras CTÎncă nu există evaluări
- QuizDocument38 paginiQuizSabha NaveenÎncă nu există evaluări
- Railway Ticket Reservation System - FinalDocument58 paginiRailway Ticket Reservation System - FinalArumugamÎncă nu există evaluări
- Volatility Surface InterpolationDocument24 paginiVolatility Surface InterpolationMickehugoÎncă nu există evaluări
- QTP MaterialDocument93 paginiQTP MaterialNadikattu RavikishoreÎncă nu există evaluări
- SPPM Notes 1Document12 paginiSPPM Notes 1kokiladevirajaveluÎncă nu există evaluări
- OATS - Oracle Application TestingDocument4 paginiOATS - Oracle Application TestingAbhinavÎncă nu există evaluări
- AQM Regression Day 3 Class WorkDocument4 paginiAQM Regression Day 3 Class Workaneeqa.shahzadÎncă nu există evaluări
- Regression Analysis: Study Hours GPA 5 2.8 8 3.1 6 3.4 7 3.5 1 2.2 4 3.67 3 3 8 2.5 5 3.33 2 3Document9 paginiRegression Analysis: Study Hours GPA 5 2.8 8 3.1 6 3.4 7 3.5 1 2.2 4 3.67 3 3 8 2.5 5 3.33 2 3Shoaib HyderÎncă nu există evaluări
- Ridge RegressionDocument4 paginiRidge Regressionbonek28Încă nu există evaluări
- Statistik Deskriptif N: Minimum Maximum Mean Std. DeviationDocument7 paginiStatistik Deskriptif N: Minimum Maximum Mean Std. DeviationLKP KHAFAÎncă nu există evaluări
- Scale $ All Variable RegDocument21 paginiScale $ All Variable Regrao saadÎncă nu există evaluări
- Human Resource Planning in Health CareDocument3 paginiHuman Resource Planning in Health CarevishalbdsÎncă nu există evaluări
- Journal of Cleaner Production: Kamalakanta Muduli, Kannan Govindan, Akhilesh Barve, Yong GengDocument10 paginiJournal of Cleaner Production: Kamalakanta Muduli, Kannan Govindan, Akhilesh Barve, Yong GengAnass CHERRAFIÎncă nu există evaluări
- The Christian Life ProgramDocument28 paginiThe Christian Life ProgramRalph Christer MaderazoÎncă nu există evaluări
- Classics and The Atlantic Triangle - Caribbean Readings of Greece and Rome Via AfricaDocument12 paginiClassics and The Atlantic Triangle - Caribbean Readings of Greece and Rome Via AfricaAleja KballeroÎncă nu există evaluări
- Art of Data ScienceDocument159 paginiArt of Data Sciencepratikshr192% (12)
- Canine HyperlipidaemiaDocument11 paginiCanine Hyperlipidaemiaheidy acostaÎncă nu există evaluări
- NHÓM ĐỘNG TỪ BẤT QUY TẮCDocument4 paginiNHÓM ĐỘNG TỪ BẤT QUY TẮCNhựt HàoÎncă nu există evaluări
- Travel Smart: Assignment 1: Project ProposalDocument14 paginiTravel Smart: Assignment 1: Project ProposalcattytomeÎncă nu există evaluări
- CH 13 ArqDocument6 paginiCH 13 Arqneha.senthilaÎncă nu există evaluări
- Observation: Student: Liliia Dziuda Date: 17/03/21 Topic: Movie Review Focus: Writing SkillsDocument2 paginiObservation: Student: Liliia Dziuda Date: 17/03/21 Topic: Movie Review Focus: Writing SkillsLiliaÎncă nu există evaluări
- Carcinoma of PenisDocument13 paginiCarcinoma of Penisalejandro fernandezÎncă nu există evaluări
- 1574 PDFDocument1 pagină1574 PDFAnonymous APW3d6gfd100% (1)
- Chris Baeza: ObjectiveDocument2 paginiChris Baeza: Objectiveapi-283893712Încă nu există evaluări
- Decision Making and Problem Solving & Managing - Gashaw PDFDocument69 paginiDecision Making and Problem Solving & Managing - Gashaw PDFKokebu MekonnenÎncă nu există evaluări
- Invoice Ce 2019 12 IVDocument8 paginiInvoice Ce 2019 12 IVMoussa NdourÎncă nu există evaluări
- FSR 2017-2018 KNL CircleDocument136 paginiFSR 2017-2018 KNL CircleparthaÎncă nu există evaluări
- A Complete List of Greek Underworld GodsDocument3 paginiA Complete List of Greek Underworld GodsTimothy James M. Madrid100% (1)
- Reaction On The 83RD Post Graduate Course On Occupational Health and SafetyDocument1 paginăReaction On The 83RD Post Graduate Course On Occupational Health and SafetyEdcelle SabanalÎncă nu există evaluări
- Grenade FINAL (Esl Song Activities)Document4 paginiGrenade FINAL (Esl Song Activities)Ti LeeÎncă nu există evaluări
- Appendix I Leadership Questionnaire: Ior Description Questionnaire (LBDQ - Form XII 1962) - The Division IntoDocument24 paginiAppendix I Leadership Questionnaire: Ior Description Questionnaire (LBDQ - Form XII 1962) - The Division IntoJoan GonzalesÎncă nu există evaluări
- BS Assignment Brief - Strategic Planning AssignmentDocument8 paginiBS Assignment Brief - Strategic Planning AssignmentParker Writing ServicesÎncă nu există evaluări
- Mark Scheme (Results) Summer 2019: Pearson Edexcel International GCSE in English Language (4EB1) Paper 01RDocument19 paginiMark Scheme (Results) Summer 2019: Pearson Edexcel International GCSE in English Language (4EB1) Paper 01RNairit100% (1)
- Heart Rate Variability - Wikipedia PDFDocument30 paginiHeart Rate Variability - Wikipedia PDFLevon HovhannisyanÎncă nu există evaluări
- Adjective Clauses: Relative Pronouns & Relative ClausesDocument4 paginiAdjective Clauses: Relative Pronouns & Relative ClausesJaypee MelendezÎncă nu există evaluări
- Fsi GreekBasicCourse Volume1 StudentTextDocument344 paginiFsi GreekBasicCourse Volume1 StudentTextbudapest1Încă nu există evaluări
- scn615 Classroomgroupactionplan SarahltDocument3 paginiscn615 Classroomgroupactionplan Sarahltapi-644817377Încă nu există evaluări
- Hoaxes Involving Military IncidentsDocument5 paginiHoaxes Involving Military IncidentsjtcarlÎncă nu există evaluări
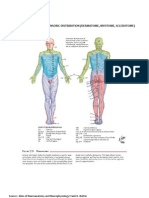
- Dermatome, Myotome, SclerotomeDocument4 paginiDermatome, Myotome, SclerotomeElka Rifqah100% (3)
- Modern Prometheus Editing The HumanDocument399 paginiModern Prometheus Editing The HumanHARTK 70Încă nu există evaluări
- δ (n) = u (n) - u (n-3) = 1 ,n=0Document37 paginiδ (n) = u (n) - u (n-3) = 1 ,n=0roberttheivadasÎncă nu există evaluări