S-ar putea să vă placă și
- LES MACROS AVEC GOOGLE SHEETS: Programmer en JavascriptDe la EverandLES MACROS AVEC GOOGLE SHEETS: Programmer en JavascriptÎncă nu există evaluări
- 2objets RDocument14 pagini2objets RThiaré ModouÎncă nu există evaluări
- TP 01 (R)Document5 paginiTP 01 (R)Ilham Timadjer0% (1)
- Manuel EviewsDocument32 paginiManuel Eviewslifeblue2100% (1)
- PolyDocument25 paginiPolyDavid Cirimwami MufungiziÎncă nu există evaluări
- Tp2: Deep Learning: TensorflowDocument9 paginiTp2: Deep Learning: Tensorflowkais.chammakhiÎncă nu există evaluări
- PDF 9 JAVAscriptDocument13 paginiPDF 9 JAVAscriptibouÎncă nu există evaluări
- Compte Rendu 2Document9 paginiCompte Rendu 2Amal RebeiÎncă nu există evaluări
- TP1-t-signal2020-21.pdf L3 S1Document4 paginiTP1-t-signal2020-21.pdf L3 S1Abir AbirÎncă nu există evaluări
- Mecanisme Des Classes Sous RDocument30 paginiMecanisme Des Classes Sous REric DassieÎncă nu există evaluări
- 2 OOP INTRODUCTIONDocument47 pagini2 OOP INTRODUCTIONkedegaston.maximeÎncă nu există evaluări
- TD R ApplyDocument28 paginiTD R Applycheick atjiÎncă nu există evaluări
- Style de ProgrammationDocument3 paginiStyle de Programmationbasraoui moadÎncă nu există evaluări
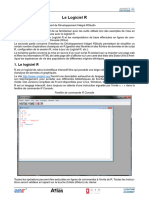
- Atelier Sur Le Logiciel RDocument13 paginiAtelier Sur Le Logiciel RZayneb MessaoudiÎncă nu există evaluări
- Guide Langage RDocument30 paginiGuide Langage RBarnicha HafsaÎncă nu există evaluări
- TP STDDocument7 paginiTP STDazertÎncă nu există evaluări
- Course V1projet Theme187075session01 Module1 Partie2 Use Case Le Logiciel RDocument7 paginiCourse V1projet Theme187075session01 Module1 Partie2 Use Case Le Logiciel RMoufida HajjajÎncă nu există evaluări
- Operateurs FonctionsDocument18 paginiOperateurs FonctionsAngelo mahafeÎncă nu există evaluări
- CH 2 - Les Listes ChaînéesDocument30 paginiCH 2 - Les Listes Chaînéeskenza fertasÎncă nu există evaluări
- Cours Javascript - Partie III - IDMANSOURDocument11 paginiCours Javascript - Partie III - IDMANSOURramzi esprimsÎncă nu există evaluări
- Python Inter B3 - 3Document13 paginiPython Inter B3 - 3elkemar le saoÎncă nu există evaluări
- Chapitre 1 POO C++Document50 paginiChapitre 1 POO C++BECHIR BAAZIZÎncă nu există evaluări
- R Cours1Document23 paginiR Cours1diarrassouba kolotielomaÎncă nu există evaluări
- Polycopie JavaDocument16 paginiPolycopie JavaJed LambachÎncă nu există evaluări
- Chap 2 PDFDocument6 paginiChap 2 PDFCecile SpykilineÎncă nu există evaluări
- Chapitre 2Document11 paginiChapitre 2AÎncă nu există evaluări
- Pour Se Donner Un Peu D'R: Chapitre 1: IntroductionDocument62 paginiPour Se Donner Un Peu D'R: Chapitre 1: IntroductionNaoui IkramÎncă nu există evaluări
- Sciences Des Données Appliquées (Fondamentales) : Cours 5Document71 paginiSciences Des Données Appliquées (Fondamentales) : Cours 5Oumayma ISMAAILIÎncă nu există evaluări
- Cours Matlab FIDocument68 paginiCours Matlab FIing_taharÎncă nu există evaluări
- tp2 POO en Java Fatma EllouzeDocument4 paginitp2 POO en Java Fatma EllouzeMohamed Kadhem BelghuithÎncă nu există evaluări
- Cour StructDocument100 paginiCour StructoussamaessouidizÎncă nu există evaluări
- FR Tanagra Tensorflow Keras Python PDFDocument15 paginiFR Tanagra Tensorflow Keras Python PDFMatisiSpraÎncă nu există evaluări
- POO PyDocument26 paginiPOO PyGuershom PakaÎncă nu există evaluări
- TP 4Document11 paginiTP 4Ferdinand AttaÎncă nu există evaluări
- Scheme Doctor RacketDocument21 paginiScheme Doctor RacketrenaudÎncă nu există evaluări
- Meflab V2Document7 paginiMeflab V2Mourad TajÎncă nu există evaluări
- Presentation Du Logiciel MatlabDocument11 paginiPresentation Du Logiciel MatlabBoubacar DialloÎncă nu există evaluări
- Chapitre1 Asd1 Moez Ben RkayaDocument26 paginiChapitre1 Asd1 Moez Ben RkayacreateursiteÎncă nu există evaluări
- Cours Matlab2Document26 paginiCours Matlab2Yassine EL FAKHAOUIÎncă nu există evaluări
- StatDonnees Fiches 1516Document12 paginiStatDonnees Fiches 1516FatouÎncă nu există evaluări
- Atelier 1Document5 paginiAtelier 1eya boulaabaÎncă nu există evaluări
- 3fonctions RDocument7 pagini3fonctions RThiaré ModouÎncă nu există evaluări
- MEthode Sous RDocument19 paginiMEthode Sous Rdaoud ounaissiÎncă nu există evaluări
- Cours ExcelDocument51 paginiCours ExcelTaha Can100% (2)
- Guide MatlabDocument15 paginiGuide MatlabLucien SikapaÎncă nu există evaluări
- Cours Et Excercice en AlgorithmeDocument28 paginiCours Et Excercice en AlgorithmeJaouad Ba100% (1)
- Introduction To MatlabDocument20 paginiIntroduction To MatlabSamir SayahÎncă nu există evaluări
- ExeossDocument4 paginiExeossMohamed OuaggaÎncă nu există evaluări
- Info Prepare Su MeDocument5 paginiInfo Prepare Su MeAnime Final BattlesÎncă nu există evaluări
- Compte Rendu Du TP 1Document5 paginiCompte Rendu Du TP 1israe.boutaharÎncă nu există evaluări
- Juin 12Document8 paginiJuin 12Best OffensiveÎncă nu există evaluări
- ALG08 Algorithme kNN2Document4 paginiALG08 Algorithme kNN2OrnetAndIceÎncă nu există evaluări
- Maniement Matricielle Et Affichage D'imageDocument10 paginiManiement Matricielle Et Affichage D'imagekikizouzouÎncă nu există evaluări
- MEFtaveDocument7 paginiMEFtaveANDAHMOU SoulaimanÎncă nu există evaluări
- Initiation À Matlab Simulink - CHAFIK - 2023Document28 paginiInitiation À Matlab Simulink - CHAFIK - 2023Gleone KaiserinÎncă nu există evaluări
- Exercices Algo 3Document5 paginiExercices Algo 3Mouhamed GueyeÎncă nu există evaluări
- AlgorithmiqueDocument62 paginiAlgorithmiqueZan LayleÎncă nu există evaluări
- Ruby Paquets 100 Coups: Maîtrise en Une Heure - Édition 2024De la EverandRuby Paquets 100 Coups: Maîtrise en Une Heure - Édition 2024Încă nu există evaluări
- Avantages D'investissementsDocument1 paginăAvantages D'investissementsyassin900Încă nu există evaluări
- BO - 6248 - FR - Suppression ZF Port Tanger VilleDocument144 paginiBO - 6248 - FR - Suppression ZF Port Tanger Villeyassin900Încă nu există evaluări
- Programme de Recherche - 1Document2 paginiProgramme de Recherche - 1yassin900Încă nu există evaluări
- 32 Resolution Probleme PDFDocument5 pagini32 Resolution Probleme PDFImmamHadramy0% (1)
- Approche Processus 27 03 2019Document20 paginiApproche Processus 27 03 2019yassin900Încă nu există evaluări
- Résumé Management s2 2Document5 paginiRésumé Management s2 2yassin900Încă nu există evaluări
- Formation Fonctionnelle SAP MM1Document4 paginiFormation Fonctionnelle SAP MM1yassin900Încă nu există evaluări
- Arrêté - Matières Et Produits ExplosifsDocument5 paginiArrêté - Matières Et Produits Explosifsyassin900Încă nu există evaluări
- Rdii 30581Document2 paginiRdii 30581Houssine IbourkÎncă nu există evaluări
- M06 Securite Et Qualite Entier TRA-TSETDocument132 paginiM06 Securite Et Qualite Entier TRA-TSETyassin900Încă nu există evaluări
- La Pratique de Laudit Interne - MjsDocument78 paginiLa Pratique de Laudit Interne - MjsCheikh NgomÎncă nu există evaluări
- Les Écoles de Pensée Du ManagementDocument34 paginiLes Écoles de Pensée Du Managementyassin900100% (3)
- Standards de Manutention de BaseDocument30 paginiStandards de Manutention de Baseyassin900100% (1)
- Rapport Danalyses Et Recommandations Des Acteurs de LOSP-JEEP Rapport Des Tables Thmatiques de Laprs-MidiDocument41 paginiRapport Danalyses Et Recommandations Des Acteurs de LOSP-JEEP Rapport Des Tables Thmatiques de Laprs-Midiyassin900Încă nu există evaluări
- Livre Blanc Evaluation de La Performance Web 2018Document17 paginiLivre Blanc Evaluation de La Performance Web 2018yassin900Încă nu există evaluări
- Tanger Chaoual 1440Document1 paginăTanger Chaoual 1440yassin900Încă nu există evaluări
- Template CV 2Document1 paginăTemplate CV 2yassin900Încă nu există evaluări
- M09 - Tableaux de BordDocument23 paginiM09 - Tableaux de BordimaneÎncă nu există evaluări
- Circulaireloi 77-15646Document2 paginiCirculaireloi 77-15646yassin900Încă nu există evaluări
- Ue Cgem - Programme FRDocument12 paginiUe Cgem - Programme FRyassin900Încă nu există evaluări
- Territoires Et Flux de La Mondialisation: Entraînement Au CroquisDocument11 paginiTerritoires Et Flux de La Mondialisation: Entraînement Au Croquisyassin900Încă nu există evaluări
- TDR. SI. RevusDocument9 paginiTDR. SI. Revusyassin900Încă nu există evaluări
- Les Echanges de MarchandisesDocument49 paginiLes Echanges de Marchandisesyassin900Încă nu există evaluări
- Arretés Plastiques - BO - ArDocument3 paginiArretés Plastiques - BO - Aryassin900Încă nu există evaluări
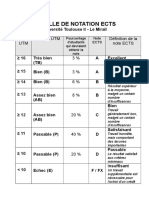
- Echelle de Notation ECTSDocument3 paginiEchelle de Notation ECTSyassin900Încă nu există evaluări
- Cours CATIA V5Document28 paginiCours CATIA V5Gana100% (1)
- Détroits Et Canaux Au Coeur Des Échanges v15Document1 paginăDétroits Et Canaux Au Coeur Des Échanges v15yassin900Încă nu există evaluări
- L.3: Shanghai, Un Port Sur Les Routes de La Chine Et Du MondeDocument13 paginiL.3: Shanghai, Un Port Sur Les Routes de La Chine Et Du Mondeyassin900Încă nu există evaluări
- Manual - Metodologia Cercetarii PDFDocument397 paginiManual - Metodologia Cercetarii PDFChiriac Margareta86% (7)
- SQL ServerDocument114 paginiSQL ServerjulllessÎncă nu există evaluări
- Corrige TD 5Document6 paginiCorrige TD 5mourad100% (1)
- RPA Methode StatiqueDocument21 paginiRPA Methode StatiqueAbdelhakim BelaidÎncă nu există evaluări
- Note de Calcul RadierDocument15 paginiNote de Calcul RadierNZOMO91% (23)
- Entraînements Réglés HEIG - Ex - Et - Corr - CompletDocument75 paginiEntraînements Réglés HEIG - Ex - Et - Corr - ComplettoulouiÎncă nu există evaluări
- TP Diffraction Des Rayons XDocument16 paginiTP Diffraction Des Rayons XNoura Zhd100% (1)
- Guide Chargement CamionsDocument20 paginiGuide Chargement CamionsAnas El AkramiÎncă nu există evaluări
- 1811-Leçons Élémenaitres de Mathématiques-l'Abbé de La CailleDocument546 pagini1811-Leçons Élémenaitres de Mathématiques-l'Abbé de La Caillemartin160464Încă nu există evaluări
- Unghi Dilatanta Din Forfecare in Aparat TriaxialDocument4 paginiUnghi Dilatanta Din Forfecare in Aparat TriaxialAndor-Csongor NagyÎncă nu există evaluări
- 06 Noces (Camus)Document14 pagini06 Noces (Camus)RafaelSilvaÎncă nu există evaluări
- Dynamique Des Rotors en Torsion-IntroductionDocument2 paginiDynamique Des Rotors en Torsion-IntroductionMed RjebÎncă nu există evaluări
- Facades Verrieres Avis Technique Structura Duo 2-07-1231Document22 paginiFacades Verrieres Avis Technique Structura Duo 2-07-1231akreitÎncă nu există evaluări
- Cable MT NFC 33 226 18 30 36 KVDocument2 paginiCable MT NFC 33 226 18 30 36 KVbensalem_470934083Încă nu există evaluări
- Ad2 CONFORTpentexemplesDocument22 paginiAd2 CONFORTpentexemplesYounes BingaÎncă nu există evaluări
- Cours Cotes Tolerancees PRDocument3 paginiCours Cotes Tolerancees PRbelkaidÎncă nu există evaluări
- 2018 Grok Lighting EN ES FR PDFDocument337 pagini2018 Grok Lighting EN ES FR PDFNakhayo JumaÎncă nu există evaluări
- Modèle RicardoDocument11 paginiModèle RicardozinebencgistÎncă nu există evaluări
- Probabilité Exercices-CorrigesDocument33 paginiProbabilité Exercices-CorrigesosefresistanceÎncă nu există evaluări
- Controle Continu 1 - CORRECTION (Octobre 2012)Document3 paginiControle Continu 1 - CORRECTION (Octobre 2012)Omar LâsriÎncă nu există evaluări
- Dc1 4tech2Document2 paginiDc1 4tech2Omar MakhÎncă nu există evaluări
- 2008 National Exo1 Correction BBT 6 5ptsDocument2 pagini2008 National Exo1 Correction BBT 6 5ptsla physique selon le programme FrançaisÎncă nu există evaluări
- Règles CM66 Et Additif 80Document392 paginiRègles CM66 Et Additif 80AyoubThunder100% (7)
- Équations (4ème)Document3 paginiÉquations (4ème)MATHS - VIDEOS100% (1)
- Abdelmeziane NabilDocument176 paginiAbdelmeziane NabildanemsalÎncă nu există evaluări
- D.S 1 3M 14 15Document2 paginiD.S 1 3M 14 15Hayk ElÎncă nu există evaluări
- Ag LagrangeDocument1 paginăAg LagrangeSoufiane BouchlaghemÎncă nu există evaluări
- Exercice 01:: P Q PQ P P PDocument4 paginiExercice 01:: P Q PQ P P PAbderrazzak ElhaimerÎncă nu există evaluări
- 03.conception Structure PorteuseDocument54 pagini03.conception Structure PorteuseFares Chammam0% (1)
- Technologie Et Principes de La Régulation BTSDocument8 paginiTechnologie Et Principes de La Régulation BTSkamradscorpionÎncă nu există evaluări