S-ar putea să vă placă și
- A New Concept for Tuning Design Weights in Survey Sampling: Jackknifing in Theory and PracticeDe la EverandA New Concept for Tuning Design Weights in Survey Sampling: Jackknifing in Theory and PracticeÎncă nu există evaluări
- Image Recognition With Deep LearningDocument5 paginiImage Recognition With Deep LearningJust JasperÎncă nu există evaluări
- Detection of Plant Disease FFDocument11 paginiDetection of Plant Disease FFguptashyam199908Încă nu există evaluări
- Food Classification Using Deep Learning Ijariie14948Document7 paginiFood Classification Using Deep Learning Ijariie14948Dương Vũ MinhÎncă nu există evaluări
- "Detection and Classification of Consumed Food Items" Using Deep Learning AlgorithmDocument19 pagini"Detection and Classification of Consumed Food Items" Using Deep Learning Algorithmjeffery lawrenceÎncă nu există evaluări
- Feature Extraction Using Deep Learning For Food Type RecognitionDocument4 paginiFeature Extraction Using Deep Learning For Food Type RecognitionfarooqespnÎncă nu există evaluări
- Fruit Recognition System and Its Nutrition LevelDocument12 paginiFruit Recognition System and Its Nutrition LevelBirinchi MedhiÎncă nu există evaluări
- 6614 Ijcsit 12Document8 pagini6614 Ijcsit 12Anonymous Gl4IRRjzNÎncă nu există evaluări
- IEEE Conference Template 1Document4 paginiIEEE Conference Template 1NNM22MC020 DEVIKA UDUPA VÎncă nu există evaluări
- Breast Cancer Classification: 1 Problem MotivationDocument7 paginiBreast Cancer Classification: 1 Problem MotivationHuy DuongÎncă nu există evaluări
- Foodd: Food Detection Dataset For Calorie Measurement Using Food ImagesDocument8 paginiFoodd: Food Detection Dataset For Calorie Measurement Using Food Images78Rutuja SurveÎncă nu există evaluări
- Osteoporosis Detection Using Machine and Deep Learning TechniquesDocument15 paginiOsteoporosis Detection Using Machine and Deep Learning TechniquesSeddik KhamousÎncă nu există evaluări
- Image Recognition Using CNNDocument12 paginiImage Recognition Using CNNshilpaÎncă nu există evaluări
- Multimodal Biometric System Using Face, Ear and Gait BiometricsDocument4 paginiMultimodal Biometric System Using Face, Ear and Gait Biometricsبورنان محمدÎncă nu există evaluări
- Image Classification of Melanoma, Nevus and Seborrheic Keratosis by Deep Neural Network EnsembleDocument4 paginiImage Classification of Melanoma, Nevus and Seborrheic Keratosis by Deep Neural Network EnsembleAli HssanÎncă nu există evaluări
- Expert Systems With Applications: Yi-Leh Wu, Cheng-Yuan Tang, Maw-Kae Hor, Pei-Fen WuDocument6 paginiExpert Systems With Applications: Yi-Leh Wu, Cheng-Yuan Tang, Maw-Kae Hor, Pei-Fen WuBatuhan BÎncă nu există evaluări
- Isbi 2016 7493382Document4 paginiIsbi 2016 7493382Gautham SgÎncă nu există evaluări
- Group 6Document8 paginiGroup 6Bebetto BabulazarÎncă nu există evaluări
- Breast Cancer ClassificationDocument16 paginiBreast Cancer ClassificationTester100% (2)
- Comparison of Feature Selection MethodsDocument6 paginiComparison of Feature Selection Methodsmodel frameÎncă nu există evaluări
- Paddy Crop Disease Finder Using Probabilistic Approach: P.Tamije Selvy, Kowsalya N, Priyanka KrishnanDocument6 paginiPaddy Crop Disease Finder Using Probabilistic Approach: P.Tamije Selvy, Kowsalya N, Priyanka KrishnanerpublicationÎncă nu există evaluări
- Study of The Pre-Processing Impact in A Facial Recognition SystemDocument11 paginiStudy of The Pre-Processing Impact in A Facial Recognition Systemalmudena aguileraÎncă nu există evaluări
- Presentation On Plant Disease Identification Using MatlabDocument20 paginiPresentation On Plant Disease Identification Using MatlabSayantan Banerjee100% (1)
- 'AI & Machine Vision Coursework Implementation of Deep Learning For Classification of Natural ImagesDocument13 pagini'AI & Machine Vision Coursework Implementation of Deep Learning For Classification of Natural ImagesResearchpro GlobalÎncă nu există evaluări
- External Quality Grading of Apple Using Deep Learning: Nitika - Cse@cumail - inDocument8 paginiExternal Quality Grading of Apple Using Deep Learning: Nitika - Cse@cumail - inTECHTOBYTEÎncă nu există evaluări
- Fruit Quality Classifier - Group 1Document12 paginiFruit Quality Classifier - Group 1Bruno TelesÎncă nu există evaluări
- Convolutional Neural Networks Based Plant Leaf Diseases Detection SchemeDocument7 paginiConvolutional Neural Networks Based Plant Leaf Diseases Detection SchemeSudhaÎncă nu există evaluări
- Journal On Estimate Food CalorieDocument9 paginiJournal On Estimate Food CalorieAmit GopeÎncă nu există evaluări
- Food-101 - Mining Discriminative Components With Random ForestsDocument16 paginiFood-101 - Mining Discriminative Components With Random ForestsFjnk TLKlklÎncă nu există evaluări
- Classification and Grading of Wheat Granules Using SVM and Naive Bayes ClassifierDocument6 paginiClassification and Grading of Wheat Granules Using SVM and Naive Bayes ClassifierEditor IJRITCCÎncă nu există evaluări
- Ensemble U-Net Model For Efficient Polyp SegmentationDocument3 paginiEnsemble U-Net Model For Efficient Polyp SegmentationshrutiÎncă nu există evaluări
- Paper 01Document7 paginiPaper 01saketag66Încă nu există evaluări
- Implementasi CNN Dan VGG-16 Untuk Mendeteksi GenderDocument10 paginiImplementasi CNN Dan VGG-16 Untuk Mendeteksi GenderAji PurwinarkoÎncă nu există evaluări
- Image Segmentation K Mean PDFDocument7 paginiImage Segmentation K Mean PDFCường TrầnÎncă nu există evaluări
- Vegetable Recognition and Classification Based OnDocument6 paginiVegetable Recognition and Classification Based Onrenato otaniÎncă nu există evaluări
- Android Based Object Detection Application For Food ItemsDocument6 paginiAndroid Based Object Detection Application For Food ItemsHafza GhafoorÎncă nu există evaluări
- TRW Assignment 1Document10 paginiTRW Assignment 1Zain UsmaniÎncă nu există evaluări
- WebMedia CarolinaWatanabe Et AlDocument8 paginiWebMedia CarolinaWatanabe Et AlCarolina WatanabeÎncă nu există evaluări
- Batch Size To Improve ResultDocument4 paginiBatch Size To Improve ResultKeren Evangeline. IÎncă nu există evaluări
- (Paperhub - Ir) 10.1007 - s00500 020 04884 XDocument16 pagini(Paperhub - Ir) 10.1007 - s00500 020 04884 XMojtaba SabooriÎncă nu există evaluări
- Genetic Algorithms For Object Recognition IN A: Complex SceneDocument4 paginiGenetic Algorithms For Object Recognition IN A: Complex Scenehvactrg1Încă nu există evaluări
- Applicability of Scaling Laws To Vision Encoding ModelsDocument7 paginiApplicability of Scaling Laws To Vision Encoding ModelsDaniele MarconiÎncă nu există evaluări
- 6e06 PDFDocument7 pagini6e06 PDFviraj vastÎncă nu există evaluări
- Clustering Before ClassificationDocument3 paginiClustering Before Classificationmc awartyÎncă nu există evaluări
- Fine-Grained Food Classification Methods On TheDocument5 paginiFine-Grained Food Classification Methods On ThePavan KumarÎncă nu există evaluări
- Traitement Du Signal: Received: 23 October 2019 Accepted: 5 February 2020Document10 paginiTraitement Du Signal: Received: 23 October 2019 Accepted: 5 February 2020123__asdfÎncă nu există evaluări
- Recent Developments in Application of Image Processing TechnDocument11 paginiRecent Developments in Application of Image Processing TechnathmadhaÎncă nu există evaluări
- Chapter 3 Methodology Sunita Upreti 2250878 (Updated2)Document29 paginiChapter 3 Methodology Sunita Upreti 2250878 (Updated2)Aashutosh SinhaÎncă nu există evaluări
- Comparison of Artificial Neural Network and Bayesian Belief Network in Computer-Assisted Diagnosis Scheme For MammographyDocument5 paginiComparison of Artificial Neural Network and Bayesian Belief Network in Computer-Assisted Diagnosis Scheme For MammographyUma GloriousÎncă nu există evaluări
- Implementing Tumor Detection and Area Calculation in Mri Image of Human Brain Using Image Processing TechniquesDocument6 paginiImplementing Tumor Detection and Area Calculation in Mri Image of Human Brain Using Image Processing TechniquesmanjunathrvÎncă nu există evaluări
- Remote Sensing Image Classification ThesisDocument4 paginiRemote Sensing Image Classification ThesisPaperWritingServicesForCollegeStudentsOmaha100% (2)
- Aditya Bhandari, Ameya Joshi, Rohit Patki, Bird Species Identification From An ImageDocument5 paginiAditya Bhandari, Ameya Joshi, Rohit Patki, Bird Species Identification From An ImageSajari KangutkarÎncă nu există evaluări
- Machine Learning Promising Prediction in Feature ExtractionDocument5 paginiMachine Learning Promising Prediction in Feature ExtractionRahul SharmaÎncă nu există evaluări
- CancerDocument7 paginiCancerALNATRON GROUPSÎncă nu există evaluări
- Technical Answers For Real World Problems Digital Assignment 1Document15 paginiTechnical Answers For Real World Problems Digital Assignment 1Raj AryanÎncă nu există evaluări
- Results: Figure 1 CRNN Architecture ClassificationDocument5 paginiResults: Figure 1 CRNN Architecture ClassificationAisha ZulifqarÎncă nu există evaluări
- MelsreeieeeDocument15 paginiMelsreeieeemelvinÎncă nu există evaluări
- Medical Image Processing - Detection of Cancer BrainDocument7 paginiMedical Image Processing - Detection of Cancer BrainIntegrated Intelligent ResearchÎncă nu există evaluări
- Remote Sensing: Improvements in Sample Selection Methods For Image ClassificationDocument12 paginiRemote Sensing: Improvements in Sample Selection Methods For Image ClassificationThales Sehn KörtingÎncă nu există evaluări
- Classification and Segmentation of Plants Using Adam Optimization Based On Deep Neural NetworksDocument26 paginiClassification and Segmentation of Plants Using Adam Optimization Based On Deep Neural NetworksmanikantaÎncă nu există evaluări
- Fake Currency Detection Using Image ProcessingDocument4 paginiFake Currency Detection Using Image ProcessingInformatika Universitas Malikussaleh100% (1)
- Indian Currency Recognition and Verification Using Image ProcessingDocument5 paginiIndian Currency Recognition and Verification Using Image ProcessingInformatika Universitas MalikussalehÎncă nu există evaluări
- 3 CurrencyDocument5 pagini3 CurrencySajith SachuÎncă nu există evaluări
- Image Recognition of 85 Food Categories by Feature FusionDocument6 paginiImage Recognition of 85 Food Categories by Feature FusionInformatika Universitas MalikussalehÎncă nu există evaluări
- Real-Time Mobile Food Recognition SystemDocument7 paginiReal-Time Mobile Food Recognition SystemInformatika Universitas MalikussalehÎncă nu există evaluări
- Measuring Calories and Nutrition From Food ImageDocument3 paginiMeasuring Calories and Nutrition From Food ImageInformatika Universitas MalikussalehÎncă nu există evaluări
- Measuring String SimilarityDocument5 paginiMeasuring String SimilarityInformatika Universitas MalikussalehÎncă nu există evaluări
- Comparison of Maize Similarity and Dissimilarity Genetic Coefficients Based On Microsatellite MarkersDocument11 paginiComparison of Maize Similarity and Dissimilarity Genetic Coefficients Based On Microsatellite MarkersInformatika Universitas MalikussalehÎncă nu există evaluări
- Measuring The Structural Similarity Between Source Code EntitiesDocument6 paginiMeasuring The Structural Similarity Between Source Code EntitiesInformatika Universitas MalikussalehÎncă nu există evaluări
- 19 1 128 4 10 20170718Document7 pagini19 1 128 4 10 20170718Informatika Universitas MalikussalehÎncă nu există evaluări
- Implementation of Some Similarity Coefficients in Conjunction With Multiple Upgma and Neighbor-Joining Algorithms For Enhancing Phylogenetic TreesDocument15 paginiImplementation of Some Similarity Coefficients in Conjunction With Multiple Upgma and Neighbor-Joining Algorithms For Enhancing Phylogenetic TreesInformatika Universitas MalikussalehÎncă nu există evaluări
- Similarity Measures For Fingerprint MatchingDocument4 paginiSimilarity Measures For Fingerprint MatchingInformatika Universitas MalikussalehÎncă nu există evaluări
- Measuring The Structural Similarity Between Source Code EntitiesDocument6 paginiMeasuring The Structural Similarity Between Source Code EntitiesInformatika Universitas MalikussalehÎncă nu există evaluări
- Ranking Fuzzy Numbers Based On Sokal and Sneath IndexDocument21 paginiRanking Fuzzy Numbers Based On Sokal and Sneath IndexInformatika Universitas MalikussalehÎncă nu există evaluări
- Image Manipulation Detection With Binary Similarity MeasuresDocument4 paginiImage Manipulation Detection With Binary Similarity MeasuresInformatika Universitas MalikussalehÎncă nu există evaluări
- Image Steganalysis With Binary Similarity MeasuresDocument9 paginiImage Steganalysis With Binary Similarity MeasuresInformatika Universitas MalikussalehÎncă nu există evaluări
- A Survey of Binary Similarity and Distance MeasuresDocument6 paginiA Survey of Binary Similarity and Distance MeasuresInformatika Universitas MalikussalehÎncă nu există evaluări
- Computation of Similarity Measures Sequential Data Using Generalized Suffix TreesDocument8 paginiComputation of Similarity Measures Sequential Data Using Generalized Suffix TreesInformatika Universitas MalikussalehÎncă nu există evaluări
- A Model For Spectra-Based Software DiagnosisDocument37 paginiA Model For Spectra-Based Software DiagnosisInformatika Universitas MalikussalehÎncă nu există evaluări
- Combined Use of Association Rules Mining and Clustering Methods To Find Relevant Links Between Binary Rare Attributes in A Large Data SetDocument18 paginiCombined Use of Association Rules Mining and Clustering Methods To Find Relevant Links Between Binary Rare Attributes in A Large Data SetInformatika Universitas MalikussalehÎncă nu există evaluări
- JDS 192Document16 paginiJDS 192amrajeeÎncă nu există evaluări
- A Machine Learning Approach To Multiword Expression ExtractionDocument4 paginiA Machine Learning Approach To Multiword Expression ExtractionInformatika Universitas MalikussalehÎncă nu există evaluări
- 3 Distance, SimilarityDocument56 pagini3 Distance, SimilarityInformatika Universitas MalikussalehÎncă nu există evaluări
- III. Mountain ProvinceDocument8 paginiIII. Mountain Provincehey its e.100% (2)
- Vestigians Voice June 2012Document26 paginiVestigians Voice June 2012Samir K MishraÎncă nu există evaluări
- Ice Cream History 2Document3 paginiIce Cream History 2Ankita SoniÎncă nu există evaluări
- Lava Latte MenuDocument2 paginiLava Latte MenuIan ArungaÎncă nu există evaluări
- Monsters University Mike Wazowski Snack Pack Craft Template 0413 FDCOMDocument1 paginăMonsters University Mike Wazowski Snack Pack Craft Template 0413 FDCOMSuchi RavaliaÎncă nu există evaluări
- Project Closure Report: Document VersionDocument4 paginiProject Closure Report: Document VersionMahendraSinghÎncă nu există evaluări
- James Joyce - Letters To NoraDocument19 paginiJames Joyce - Letters To Norafxxfy100% (1)
- Subject Link 1 - Translation Worksheet - WORDDocument32 paginiSubject Link 1 - Translation Worksheet - WORDkoalaheidiÎncă nu există evaluări
- 1 Year New NotesDocument75 pagini1 Year New NotesPoornima Adithi100% (2)
- Eco Friendly Pharmaceutical Packaging MaterialDocument14 paginiEco Friendly Pharmaceutical Packaging MaterialRohit SikriÎncă nu există evaluări
- Industrial Training ReportDocument48 paginiIndustrial Training Reportkavin raja.s80% (10)
- ITC Schemes Debit Working - RelianceDocument462 paginiITC Schemes Debit Working - ReliancehwagdareÎncă nu există evaluări
- Restaurantes de Chalatenango - Es.enDocument5 paginiRestaurantes de Chalatenango - Es.enAlejandra VenturaÎncă nu există evaluări
- Soal NarrativeDocument7 paginiSoal NarrativeAi ChanÎncă nu există evaluări
- Question & Answer: Lake St. George Field CentreDocument19 paginiQuestion & Answer: Lake St. George Field Centreapi-242869786Încă nu există evaluări
- Orisha AttributesDocument13 paginiOrisha AttributesIfalase Fagbenro100% (28)
- The Digestive System Summative Test - Q3 - M1Document2 paginiThe Digestive System Summative Test - Q3 - M1Metchel100% (1)
- Six-Pack Secrets PDFDocument15 paginiSix-Pack Secrets PDFmangozillaÎncă nu există evaluări
- 06 Basic II Handout 12 Unit 3 Getting Help What Do You Do Every DayDocument1 pagină06 Basic II Handout 12 Unit 3 Getting Help What Do You Do Every DayEnrique FerroÎncă nu există evaluări
- Procedure TextDocument10 paginiProcedure TextNadya AlkadzaÎncă nu există evaluări
- Catering Equipment Rental: Examples of CostsDocument12 paginiCatering Equipment Rental: Examples of CostsChristy Brown100% (1)
- Quản trị thực phẩm -Chapter 1 Food Management-An Overview Dhdd15 2021 E-learning IUHDocument26 paginiQuản trị thực phẩm -Chapter 1 Food Management-An Overview Dhdd15 2021 E-learning IUHNam NguyenHoangÎncă nu există evaluări
- Welcome Speech - 08 - Parbud Siang B - I Putu Adi Ardana YasaDocument4 paginiWelcome Speech - 08 - Parbud Siang B - I Putu Adi Ardana YasaAdi ArdanaÎncă nu există evaluări
- Restaurant Opening and Closing Checklist PDFDocument7 paginiRestaurant Opening and Closing Checklist PDFNiniÎncă nu există evaluări
- Test EndDocument16 paginiTest EndŠabić Nail60% (5)
- .Au June.2017 FiLELiSTDocument142 pagini.Au June.2017 FiLELiSTDringo AlexÎncă nu există evaluări
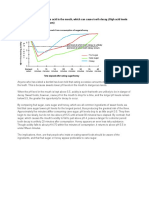
- Eating Sweet Foods Produces Acid in The Mouth, Which Can Cause Tooth Decay. (High Acid Levels Are Measured by Low PH Values)Document19 paginiEating Sweet Foods Produces Acid in The Mouth, Which Can Cause Tooth Decay. (High Acid Levels Are Measured by Low PH Values)Munawir Rahman IslamiÎncă nu există evaluări
- Issuance of Curfew Passes For Critical/Essential Employees of BOI EnterprisesDocument5 paginiIssuance of Curfew Passes For Critical/Essential Employees of BOI EnterprisesGalkandaÎncă nu există evaluări
- Finals On Purposive Communication 2Document4 paginiFinals On Purposive Communication 2Domilyn Zantua BallaÎncă nu există evaluări
- Kids Activity Sheets: Class 1Document24 paginiKids Activity Sheets: Class 1Vindu ViharamÎncă nu există evaluări