S-ar putea să vă placă și
- Mensuração de Atitudes: A proposição de um protocolo para elaboração de escalasDe la EverandMensuração de Atitudes: A proposição de um protocolo para elaboração de escalasÎncă nu există evaluări
- 08 Harpa Cristã - Cristo, o Fiel Amigo - Arranjo: Renato PimentaDocument32 pagini08 Harpa Cristã - Cristo, o Fiel Amigo - Arranjo: Renato PimentaRenato Pimenta100% (1)
- Soldadura Fio FluxadoDocument56 paginiSoldadura Fio FluxadoNuno de SáÎncă nu există evaluări
- Cargos Carreiras e Salários: Práticas e Técnicas de GestãoDe la EverandCargos Carreiras e Salários: Práticas e Técnicas de GestãoÎncă nu există evaluări
- Regulamentação da Lei 8080/90 e organização do SUS esquematizadasDocument37 paginiRegulamentação da Lei 8080/90 e organização do SUS esquematizadasRogério Furtado90% (10)
- Gestão Estratégica AvançadaDocument7 paginiGestão Estratégica AvançadaDenisÎncă nu există evaluări
- Flávio Porpino - PPT - Governança Corporativa - Parte 01Document21 paginiFlávio Porpino - PPT - Governança Corporativa - Parte 01Vítor MirandaÎncă nu există evaluări
- 10 Principios Da TQMDocument5 pagini10 Principios Da TQMlufasoÎncă nu există evaluări
- Gerenciando Projetos:De la EverandGerenciando Projetos:Încă nu există evaluări
- Recrutamento de talentos: estratégias e técnicasDocument69 paginiRecrutamento de talentos: estratégias e técnicasAugustoÎncă nu există evaluări
- Conceitos fundamentais de estratégiaDocument32 paginiConceitos fundamentais de estratégiahiana britoÎncă nu există evaluări
- O Planejamento Estratégico 1Document3 paginiO Planejamento Estratégico 1Renzo GuimarãesÎncă nu există evaluări
- Soluções globais, parcerias internacionais: O Relatório sobre o Desenvolvimento 2021 do Banco Europeu de InvestimentoDe la EverandSoluções globais, parcerias internacionais: O Relatório sobre o Desenvolvimento 2021 do Banco Europeu de InvestimentoÎncă nu există evaluări
- Fundamentos da logística para exportaçãoDocument127 paginiFundamentos da logística para exportaçãokarlamotta100% (2)
- Direito Aplicado À InformáticaDocument53 paginiDireito Aplicado À InformáticaGustavo Rossi100% (1)
- PNL FonsecaSara 28112023Document23 paginiPNL FonsecaSara 28112023MariaÎncă nu există evaluări
- Livro Processo de NegociaçãoDocument152 paginiLivro Processo de NegociaçãoSue WallaceÎncă nu există evaluări
- Manual Rápido de Pesquisa de Opinião e EleitoralDe la EverandManual Rápido de Pesquisa de Opinião e EleitoralÎncă nu există evaluări
- Apostila Curso PLC Siemens Software Step7Document343 paginiApostila Curso PLC Siemens Software Step7Erlon Carvalho100% (4)
- Pesquisa MercadológicaDocument10 paginiPesquisa MercadológicaLUIZ VEIGAÎncă nu există evaluări
- Administração Participativa - Slides - PDFDocument8 paginiAdministração Participativa - Slides - PDFElino LuckÎncă nu există evaluări
- Manual Do Exportador - Normas e Boas Práticas Do Exportador Autor TecMinhoDocument158 paginiManual Do Exportador - Normas e Boas Práticas Do Exportador Autor TecMinhoCamilo RoblesÎncă nu există evaluări
- Como potenciar a eficácia das equipas de trabalhoDocument46 paginiComo potenciar a eficácia das equipas de trabalhoDuarte Gonçalves RibeiroÎncă nu există evaluări
- Exportar para EspanhaDocument78 paginiExportar para Espanhasuu_sarmento100% (1)
- Termo de Abertura de ProjetoDocument9 paginiTermo de Abertura de ProjetoPricila YessayanÎncă nu există evaluări
- A Evolução da Função OSM e as Novas Tecnologias de GestãoDocument69 paginiA Evolução da Função OSM e as Novas Tecnologias de GestãoFabio FigueiredoÎncă nu există evaluări
- Probabilidade PCDFDocument54 paginiProbabilidade PCDFjose otavio100% (1)
- Manual Cidadania Global DigitalDocument116 paginiManual Cidadania Global Digitalnandsantos100% (2)
- Apostila TGA. IIDocument5 paginiApostila TGA. IIMaria Do Carmo VerasÎncă nu există evaluări
- Ufcd0606 - Projetos de InvestimentoDocument83 paginiUfcd0606 - Projetos de InvestimentoMarilia GenovevoÎncă nu există evaluări
- Análise Estatística DiagnósticoDocument5 paginiAnálise Estatística DiagnósticodullucaÎncă nu există evaluări
- Negociação e Gestão de ConflitosDocument50 paginiNegociação e Gestão de ConflitosSilvio SilvaÎncă nu există evaluări
- Estatistica Multivariada SPSS 07 Regressao Linear MultiplaDocument83 paginiEstatistica Multivariada SPSS 07 Regressao Linear MultiplapauloÎncă nu există evaluări
- Dicas etiqueta empresarialDocument6 paginiDicas etiqueta empresarialAnalice Guasti Felix LinharesÎncă nu există evaluări
- Formas de amostragem probabilísticaDocument6 paginiFormas de amostragem probabilísticaRoland Van Abudo AmaroÎncă nu există evaluări
- Teste Hipoteses PDFDocument21 paginiTeste Hipoteses PDFthiago luiizÎncă nu există evaluări
- Estrutura Do Plano de NegociosDocument2 paginiEstrutura Do Plano de NegociosMariana UzuelliÎncă nu există evaluări
- Perfis psicológicos e estilos de negociaçãoDocument18 paginiPerfis psicológicos e estilos de negociaçãoCarol CastroÎncă nu există evaluări
- Estatística Básica: População, Amostra, Variáveis e TiposDocument20 paginiEstatística Básica: População, Amostra, Variáveis e TiposjeanfmcÎncă nu există evaluări
- Formulacao EstrategicaDocument12 paginiFormulacao EstrategicaNajo MatabelaÎncă nu există evaluări
- ANÁLISE DE REGRESSÃO - Uma Ferramenta para A Previsão de Vendas.Document16 paginiANÁLISE DE REGRESSÃO - Uma Ferramenta para A Previsão de Vendas.Paulo OliverÎncă nu există evaluări
- Negociação de pneus - 10% de desconto à vistaDocument5 paginiNegociação de pneus - 10% de desconto à vistaRonylson Ferreira CameloÎncă nu există evaluări
- Como Elaborar Uma Pesquisa de Mercado - Sebrae - 1º Passo1Document3 paginiComo Elaborar Uma Pesquisa de Mercado - Sebrae - 1º Passo1Fernanda Lima Avena CostaÎncă nu există evaluări
- Regressao Linear MultiplaDocument54 paginiRegressao Linear MultiplacassianopachecoÎncă nu există evaluări
- GLOSSÁRIO Sistema DigestórioDocument2 paginiGLOSSÁRIO Sistema DigestórioandermedvetÎncă nu există evaluări
- Questionario-Tecnicas de NegociacaoDocument3 paginiQuestionario-Tecnicas de NegociacaoFarllen Guedes0% (1)
- Análise AdministrativaDocument8 paginiAnálise AdministrativaEuricles TeixeiraÎncă nu există evaluări
- Consultoria InternaDocument13 paginiConsultoria InternapesselaÎncă nu există evaluări
- Psicologia TrabalhoDocument114 paginiPsicologia TrabalhoelzasenaÎncă nu există evaluări
- Escalas de mensuração de atitudes: Thurstone, Osgood, Stapel, Likert, Guttman e AlpertDocument26 paginiEscalas de mensuração de atitudes: Thurstone, Osgood, Stapel, Likert, Guttman e AlpertMarilene Olivier100% (1)
- INTRODUÇÃO Importação e Exportação - SEMINÁRIO (Salvo Automaticamente)Document20 paginiINTRODUÇÃO Importação e Exportação - SEMINÁRIO (Salvo Automaticamente)Ana ReisÎncă nu există evaluări
- A Venda Pessoal - ArtigoDocument46 paginiA Venda Pessoal - ArtigoDesirée SilvaÎncă nu există evaluări
- Teoria dos Jogos: Estudo de decisões interdependentesDocument12 paginiTeoria dos Jogos: Estudo de decisões interdependentesShelton UamusseÎncă nu există evaluări
- Administração da Produção e OperaçõesDocument78 paginiAdministração da Produção e Operaçõesgleisonguimaraes100% (1)
- Técnico Comunicação, Marketing, Relações Públicas e Publicidade Módulo 5 – Sistemas de Informação / Estudos de MercadoDocument36 paginiTécnico Comunicação, Marketing, Relações Públicas e Publicidade Módulo 5 – Sistemas de Informação / Estudos de Mercadocarlasantossilva103Încă nu există evaluări
- Apol+prova Ferramentas de QualidadeDocument6 paginiApol+prova Ferramentas de QualidadeVanessa CostaÎncă nu există evaluări
- Avaliação de desempenho em gestão empresarialDocument16 paginiAvaliação de desempenho em gestão empresarialJones LipequeÎncă nu există evaluări
- Auxiliar Financeiro: Organização e ServiçosDocument22 paginiAuxiliar Financeiro: Organização e ServiçosPrínciaÎncă nu există evaluări
- Gerenciando negociações e conflitosDocument102 paginiGerenciando negociações e conflitosÉrica AlvesÎncă nu există evaluări
- Av2 Gestão Da QualidadeDocument3 paginiAv2 Gestão Da QualidadeTorres LaideÎncă nu există evaluări
- Grid GerencialDocument6 paginiGrid GerencialFernanda BocoliÎncă nu există evaluări
- 02 - Quebra de Paradigmas e o Cotidiano Das OrganizaçõesDocument19 pagini02 - Quebra de Paradigmas e o Cotidiano Das Organizaçõesferpad17Încă nu există evaluări
- Estratégias de preços e marketingDocument2 paginiEstratégias de preços e marketinggutynhoÎncă nu există evaluări
- Introdução à AdministraçãoDocument15 paginiIntrodução à AdministraçãoCelio AlvesÎncă nu există evaluări
- Mudança Organizacional e Ação Comunicativa: o resgate da dignidade e da emancipação humanaDe la EverandMudança Organizacional e Ação Comunicativa: o resgate da dignidade e da emancipação humanaÎncă nu există evaluări
- Granulação e Revestimento em LeitoDocument13 paginiGranulação e Revestimento em LeitoMatheusoliveÎncă nu există evaluări
- Relatório 4 Nano - Grupo 05Document3 paginiRelatório 4 Nano - Grupo 05MatheusoliveÎncă nu există evaluări
- 07 Compostos FenolicosDocument28 pagini07 Compostos FenolicosMatheusoliveÎncă nu există evaluări
- Apostila EnterobacteriasDocument7 paginiApostila EnterobacteriasMarina FerreiraÎncă nu există evaluări
- Micro P 4Document12 paginiMicro P 4Teodoro FariaÎncă nu există evaluări
- Fundamentos de DiluiçãoDocument4 paginiFundamentos de DiluiçãocorvofakeÎncă nu există evaluări
- 109 23075 20042014 231129Document37 pagini109 23075 20042014 231129MatheusoliveÎncă nu există evaluări
- Micol VirolDocument2 paginiMicol VirolMatheusoliveÎncă nu există evaluări
- Microbiologia de Alimentos na UESBDocument24 paginiMicrobiologia de Alimentos na UESBMatheusoliveÎncă nu există evaluări
- Fundamentos de DiluiçãoDocument4 paginiFundamentos de DiluiçãocorvofakeÎncă nu există evaluări
- Gestão JIT em hospitaisDocument4 paginiGestão JIT em hospitaisMatheusoliveÎncă nu există evaluări
- SVS P802 98medDocument11 paginiSVS P802 98medMatheusoliveÎncă nu există evaluări
- 1 SPDocument12 pagini1 SPMatheusoliveÎncă nu există evaluări
- Citopatologia lesões mamaDocument8 paginiCitopatologia lesões mamaMatheusoliveÎncă nu există evaluări
- Quest Satisf HemocentroDocument10 paginiQuest Satisf HemocentroMatheusoliveÎncă nu există evaluări
- INTRODUÇÃO Auculta!Document3 paginiINTRODUÇÃO Auculta!MatheusoliveÎncă nu există evaluări
- Toxicologia SocialDocument5 paginiToxicologia SocialMatheusoliveÎncă nu există evaluări
- ADocument4 paginiAMatheusoliveÎncă nu există evaluări
- Controle Da QualidadeDocument49 paginiControle Da QualidadeAntonio Tadeu MenesesÎncă nu există evaluări
- 3490 11672 1 PBDocument16 pagini3490 11672 1 PBMatheusoliveÎncă nu există evaluări
- Introdução à Cromatografia: Princípios e TécnicasDocument20 paginiIntrodução à Cromatografia: Princípios e TécnicasPatricia Lopes LealÎncă nu există evaluări
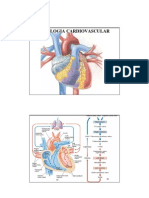
- Autran JR - Fisiologia Humana - CardiovascularDocument33 paginiAutran JR - Fisiologia Humana - CardiovascularMatheusoliveÎncă nu există evaluări
- Sem Título 1Document1 paginăSem Título 1MatheusoliveÎncă nu există evaluări
- Reações RadicalaresDocument3 paginiReações RadicalaresMatheusoliveÎncă nu există evaluări
- Automacao PDFDocument330 paginiAutomacao PDFBruno GenteluciÎncă nu există evaluări
- Fis Giars Guia Informacao Apuracao Icms RsDocument11 paginiFis Giars Guia Informacao Apuracao Icms RsHitler Antonio de AlmeidaÎncă nu există evaluări
- Atualização da legenda do mapa de solos do ESDocument34 paginiAtualização da legenda do mapa de solos do ESAndre VaccariÎncă nu există evaluări
- Ensaio compressão carotes betãoDocument2 paginiEnsaio compressão carotes betãoAzuriak1Încă nu există evaluări
- Construção de cisterna de 4500LDocument4 paginiConstrução de cisterna de 4500LJonathan PistoriusÎncă nu există evaluări
- Exercicios Grupo 1 - Algoritimia - UFCD 0809 - Programação em CIC++ - FundamentosDocument5 paginiExercicios Grupo 1 - Algoritimia - UFCD 0809 - Programação em CIC++ - FundamentosAndreia DiasÎncă nu există evaluări
- Estatística Básica: População, Amostra, Variáveis e TiposDocument20 paginiEstatística Básica: População, Amostra, Variáveis e TiposjeanfmcÎncă nu există evaluări
- MySQL banco de dados aberto multiplataformaDocument4 paginiMySQL banco de dados aberto multiplataformaDiego Igor0% (1)
- DOMINGODocument35 paginiDOMINGOchromabrassÎncă nu există evaluări
- Curso VBA Excel - Básico PDFDocument28 paginiCurso VBA Excel - Básico PDFitalo_junjiÎncă nu există evaluări
- Nova operadora revoluciona telefonia e divide lucrosDocument27 paginiNova operadora revoluciona telefonia e divide lucrosAilsonÎncă nu există evaluări
- Ed. Física, 3º EMEJA - A Influência Da Mídia e Da Tecnologia Nas Nossas Práticas CorporaisDocument9 paginiEd. Física, 3º EMEJA - A Influência Da Mídia e Da Tecnologia Nas Nossas Práticas CorporaisCristiane FariasÎncă nu există evaluări
- Lista de exercícios avaliativa de circuitos digitaisDocument9 paginiLista de exercícios avaliativa de circuitos digitaisElder SantosÎncă nu există evaluări
- PMT3110 Lista 09 2018Document5 paginiPMT3110 Lista 09 2018ccq256867Încă nu există evaluări
- Administração da fila de esperaDocument31 paginiAdministração da fila de esperamarisaÎncă nu există evaluări
- Metropolitana Dabr-Rj23060995-02rev003Document2 paginiMetropolitana Dabr-Rj23060995-02rev003DENISE MESQUITAÎncă nu există evaluări
- PAV - Aula 1 - Introdução - Generalidades Sobre PavimentosDocument29 paginiPAV - Aula 1 - Introdução - Generalidades Sobre PavimentosWaleson MagaveÎncă nu există evaluări
- Plano Diretor de Drenagem Urbana de Teresina/PI - Tomo 3Document58 paginiPlano Diretor de Drenagem Urbana de Teresina/PI - Tomo 3rjarfÎncă nu există evaluări
- EPL2 diretamente para LP2844 Zebra via CDocument5 paginiEPL2 diretamente para LP2844 Zebra via CVinicius AraujoÎncă nu există evaluări
- Licença de Atividade Rural para pecuária/agricultura em 88,80 haDocument2 paginiLicença de Atividade Rural para pecuária/agricultura em 88,80 haLucas DonidaÎncă nu există evaluări
- NEED FOR SPEED PROSTREET (PS2) CÓDIGOSDocument15 paginiNEED FOR SPEED PROSTREET (PS2) CÓDIGOSalexbreisÎncă nu există evaluări
- Resolvendo LMIs no MATLAB com Yalmip e SedumiDocument20 paginiResolvendo LMIs no MATLAB com Yalmip e SedumiLuis Carvalho50% (2)
- Cadernos 9Document303 paginiCadernos 9Luiza ValladaresÎncă nu există evaluări
- Controlo de rendimentos e mão de obra em construçãoDocument102 paginiControlo de rendimentos e mão de obra em construçãoCarlos MagalhãesÎncă nu există evaluări