S-ar putea să vă placă și
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Simple, Efficient and Effective Encodings of Local Deep Features For Video Action RecognitionDocument8 paginiSimple, Efficient and Effective Encodings of Local Deep Features For Video Action RecognitionAnonymous ntIcRwM55RÎncă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Influence of The Similarity Measure To Relevance FeedbackDocument5 paginiThe Influence of The Similarity Measure To Relevance FeedbackAnonymous ntIcRwM55RÎncă nu există evaluări
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- UPB HES SO at PlantCLEF 2017 Automatic Plant Image Identification Using Transfer Learning Via Convolutional Neural NetworksDocument9 paginiUPB HES SO at PlantCLEF 2017 Automatic Plant Image Identification Using Transfer Learning Via Convolutional Neural NetworksAnonymous ntIcRwM55RÎncă nu există evaluări
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Event-Based Media Processing and Analysis A Survey of The LiteratureDocument28 paginiEvent-Based Media Processing and Analysis A Survey of The LiteratureAnonymous ntIcRwM55RÎncă nu există evaluări
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Black Body RadiationDocument46 paginiBlack Body RadiationKryptosÎncă nu există evaluări
- FACT SHEET KidZaniaDocument4 paginiFACT SHEET KidZaniaKiara MpÎncă nu există evaluări
- Sugar Industries of PakistanDocument19 paginiSugar Industries of Pakistanhelperforeu50% (2)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- HSE Induction Training 1687407986Document59 paginiHSE Induction Training 1687407986vishnuvarthanÎncă nu există evaluări
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Economic Survey 2023 2Document510 paginiEconomic Survey 2023 2esr47Încă nu există evaluări
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Kindergarten Report Card SampleDocument3 paginiKindergarten Report Card Sampleapi-294165063Încă nu există evaluări
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Pesticides 2015 - Full BookDocument297 paginiPesticides 2015 - Full BookTushar Savaliya100% (1)
- Powerpoints 4 4up8Document9 paginiPowerpoints 4 4up8Ali KalyarÎncă nu există evaluări
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- How To Select The Right Motor DriverDocument4 paginiHow To Select The Right Motor DriverHavandinhÎncă nu există evaluări
- Earnings Statement: Hilton Management Lane TN 38117 Lane TN 38117 LLC 755 Crossover MemphisDocument2 paginiEarnings Statement: Hilton Management Lane TN 38117 Lane TN 38117 LLC 755 Crossover MemphisSelina González HerreraÎncă nu există evaluări
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- Economis Project-MCOM SEM 1Document19 paginiEconomis Project-MCOM SEM 1Salma KhorakiwalaÎncă nu există evaluări
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- Evolution Epidemiology and Etiology of Temporomandibular Joint DisordersDocument6 paginiEvolution Epidemiology and Etiology of Temporomandibular Joint DisordersCM Panda CedeesÎncă nu există evaluări
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- Reflective Learning Journal (Teacher Guide) PDFDocument21 paginiReflective Learning Journal (Teacher Guide) PDFGary ZhaiÎncă nu există evaluări
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- Vocabulary Words - 20.11Document2 paginiVocabulary Words - 20.11ravindra kumar AhirwarÎncă nu există evaluări
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- 2nd Quarter Exam All Source g12Document314 pagini2nd Quarter Exam All Source g12Bobo Ka100% (1)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Bimetallic ZN and HF On Silica Catalysts For The Conversion of Ethanol To 1,3-ButadieneDocument10 paginiBimetallic ZN and HF On Silica Catalysts For The Conversion of Ethanol To 1,3-ButadieneTalitha AdhyaksantiÎncă nu există evaluări
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- JurisprudenceDocument11 paginiJurisprudenceTamojit DasÎncă nu există evaluări
- Sorsogon State College: Republic of The Philippines Bulan Campus Bulan, SorsogonDocument4 paginiSorsogon State College: Republic of The Philippines Bulan Campus Bulan, Sorsogonerickson hernanÎncă nu există evaluări
- Astm C1898 20Document3 paginiAstm C1898 20Shaik HussainÎncă nu există evaluări
- Peacekeepers: First Term ExamDocument2 paginiPeacekeepers: First Term ExamNoOry foOT DZ & iNT100% (1)
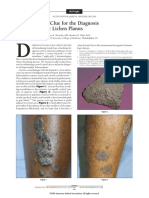
- A Novel Visual Clue For The Diagnosis of Hypertrophic Lichen PlanusDocument1 paginăA Novel Visual Clue For The Diagnosis of Hypertrophic Lichen Planus600WPMPOÎncă nu există evaluări
- Value Chain AnalaysisDocument100 paginiValue Chain AnalaysisDaguale Melaku AyeleÎncă nu există evaluări
- Solved SSC CHSL 4 March 2018 Evening Shift Paper With Solutions PDFDocument40 paginiSolved SSC CHSL 4 March 2018 Evening Shift Paper With Solutions PDFSumit VermaÎncă nu există evaluări
- Surge Protectionfor ACMachineryDocument8 paginiSurge Protectionfor ACMachineryvyroreiÎncă nu există evaluări
- WRAP HandbookDocument63 paginiWRAP Handbookzoomerfins220% (1)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- X-Roc Latex: Product DescriptionDocument2 paginiX-Roc Latex: Product DescriptionAmr RagabÎncă nu există evaluări
- 2-Emotional Abuse, Bullying and Forgiveness Among AdolescentsDocument17 pagini2-Emotional Abuse, Bullying and Forgiveness Among AdolescentsClinical and Counselling Psychology ReviewÎncă nu există evaluări
- Corrugated Board Bonding Defect VisualizDocument33 paginiCorrugated Board Bonding Defect VisualizVijaykumarÎncă nu există evaluări
- Congestion AvoidanceDocument23 paginiCongestion AvoidanceTheIgor997Încă nu există evaluări
- 5.4 Marketing Arithmetic For Business AnalysisDocument12 pagini5.4 Marketing Arithmetic For Business AnalysisashÎncă nu există evaluări
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)