S-ar putea să vă placă și
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- AOE 3024: Thin Walled Structures Solutions To Homework # 9: For Section 1-2 For Section 2-3Document8 paginiAOE 3024: Thin Walled Structures Solutions To Homework # 9: For Section 1-2 For Section 2-3akhil akkiÎncă nu există evaluări
- 1212 6206Document52 pagini1212 6206akhil akkiÎncă nu există evaluări
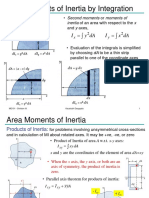
- Are A Moment of InertiaDocument20 paginiAre A Moment of Inertiaakhil akkiÎncă nu există evaluări
- Department of Mathematics: Indian Institute of Technology, Bombay Powai, Mumbai-400076, INDIADocument4 paginiDepartment of Mathematics: Indian Institute of Technology, Bombay Powai, Mumbai-400076, INDIASuvajit MajumderÎncă nu există evaluări
- Ma106 PDFDocument71 paginiMa106 PDFakhil akkiÎncă nu există evaluări
- Notes PDFDocument56 paginiNotes PDFakhil akkiÎncă nu există evaluări
- T/W 1/L 1/T T Double T, T/W Changes by 1/2Document1 paginăT/W 1/L 1/T T Double T, T/W Changes by 1/2akhil akkiÎncă nu există evaluări
- Impulse Turbine KrishnaDocument7 paginiImpulse Turbine Krishnaakhil akkiÎncă nu există evaluări
- Impulse Turbine KrishnaDocument7 paginiImpulse Turbine Krishnaakhil akkiÎncă nu există evaluări
- Rosat SpacecraftDocument21 paginiRosat Spacecraftakhil akkiÎncă nu există evaluări
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Hamilton SystemDocument4 paginiHamilton SystemmrhflameableÎncă nu există evaluări
- math2AG 2Document1 paginămath2AG 2sanjeevsarswatÎncă nu există evaluări
- What Is Time?Document1 paginăWhat Is Time?sam iam / Salvatore Gerard MichealÎncă nu există evaluări
- Quantum MechanicsDocument3 paginiQuantum MechanicsSteven ScottÎncă nu există evaluări
- The Quantum Theory of Fields Vol 3 - Supersymmetry (Weinberg)Document438 paginiThe Quantum Theory of Fields Vol 3 - Supersymmetry (Weinberg)Musa Rahim Khan100% (2)
- Turbomole Manual 7-5Document547 paginiTurbomole Manual 7-5Shekhar HansdaÎncă nu există evaluări
- Branches of PhysicsDocument5 paginiBranches of PhysicsGeanelleRicanorEsperon100% (1)
- Solving FSI Solving FSI Applications Using ANSYS Mechanical and CFXDocument26 paginiSolving FSI Solving FSI Applications Using ANSYS Mechanical and CFXRajeuv GovindanÎncă nu există evaluări
- Integrated Photonic Quantum TechnologiesDocument12 paginiIntegrated Photonic Quantum TechnologiesChinÎncă nu există evaluări
- 2018 Book LinearAlgebraAndAnalyticGeomet PDFDocument348 pagini2018 Book LinearAlgebraAndAnalyticGeomet PDFCristian Ibañez100% (2)
- Physics Paper Fundamental Forcesdocx FinalDocument14 paginiPhysics Paper Fundamental Forcesdocx FinalUrva PatelÎncă nu există evaluări
- Dunne - Resurgence in Quantum Field Theory and Quantum MechanicsDocument58 paginiDunne - Resurgence in Quantum Field Theory and Quantum MechanicsL VÎncă nu există evaluări
- HW 02 PDFDocument3 paginiHW 02 PDFQFTWÎncă nu există evaluări
- Spontaneous Breakdown of Parity in A Class of Gauge TheoriesDocument31 paginiSpontaneous Breakdown of Parity in A Class of Gauge TheoriesFRANK BULA MARTINEZÎncă nu există evaluări
- Vector Dot Product WSDocument4 paginiVector Dot Product WSDavid Reese100% (1)
- NAST Practical FileDocument18 paginiNAST Practical Filesachin prajapatiÎncă nu există evaluări
- HW2 SolDocument5 paginiHW2 SolMouliÎncă nu există evaluări
- BEE 361 Lecture 1Document17 paginiBEE 361 Lecture 1Jack MikeÎncă nu există evaluări
- Supernova Neutrinos - WikipediaDocument8 paginiSupernova Neutrinos - WikipediaBibhubhusan SwainÎncă nu există evaluări
- Review Article ReportDocument7 paginiReview Article ReportTanu ChoudharyÎncă nu există evaluări
- Geometry Optimization in Redundant Internal CoordinatesDocument6 paginiGeometry Optimization in Redundant Internal CoordinatesLorena Monterrosas PérezÎncă nu există evaluări
- Advanced Quantum Field Theory PDFDocument393 paginiAdvanced Quantum Field Theory PDFHemily Gomes MarcianoÎncă nu există evaluări
- The Maxwell Capacitance Matrix WP110301 R01Document3 paginiThe Maxwell Capacitance Matrix WP110301 R01grujic8553Încă nu există evaluări
- Cylindrical and Spherical CoordinatesDocument33 paginiCylindrical and Spherical Coordinatessumi36117Încă nu există evaluări
- Particles of The Standard ModelDocument190 paginiParticles of The Standard ModelTravisÎncă nu există evaluări
- Chapter 1: Ordinary Differential EquationsDocument3 paginiChapter 1: Ordinary Differential EquationsColorgold BirlieÎncă nu există evaluări
- Module-2, Modern Physics: Black Body RadiationDocument16 paginiModule-2, Modern Physics: Black Body RadiationRohithÎncă nu există evaluări
- UEM Sol To Exerc Chap 059Document13 paginiUEM Sol To Exerc Chap 059Prototype MichaelÎncă nu există evaluări
- Lecturenotes 1Document4 paginiLecturenotes 1Anubhav VardhanÎncă nu există evaluări
- CH 28 Solutions Glencoe 2013Document20 paginiCH 28 Solutions Glencoe 2013Doe BlackÎncă nu există evaluări