S-ar putea să vă placă și
- Material Autoinstruccional Vol1Document133 paginiMaterial Autoinstruccional Vol1Zhaul Mezza EzkamiyaÎncă nu există evaluări
- Guía para profesores sobre educación económica y financieraDocument182 paginiGuía para profesores sobre educación económica y financieraAlexis Dario SuarezÎncă nu există evaluări
- Mcin U2 A1 JucmDocument6 paginiMcin U2 A1 JucmNacho Carranza MaravillaÎncă nu există evaluări
- ESTADISTICADocument18 paginiESTADISTICAPIERO ENRIQUE SUAREZ CHAVEZÎncă nu există evaluări
- Parcialesc PaginaDocument9 paginiParcialesc PaginaHerber Manza ChávezÎncă nu există evaluări
- Graficos Con Python PDFDocument24 paginiGraficos Con Python PDFNoe Felix SinchiÎncă nu există evaluări
- 9.1 EJERCICIOS Bosquejo de La Gráfica de Una FunciónDocument6 pagini9.1 EJERCICIOS Bosquejo de La Gráfica de Una FunciónJ Luis MlsÎncă nu există evaluări
- Ps MatchingDocument10 paginiPs MatchingGustavo F. Huamán FernándezÎncă nu există evaluări
- Enseñanza Del Número Racional Positivo en Primaria. Estudio Desde El Modelo Cociente PDFDocument10 paginiEnseñanza Del Número Racional Positivo en Primaria. Estudio Desde El Modelo Cociente PDFsara ferreroÎncă nu există evaluări
- Manual Stata Basico - Juan Carlos Abanto OrihuelaDocument79 paginiManual Stata Basico - Juan Carlos Abanto OrihuelaFaridRodriguez100% (2)
- Matematica 4° Ecr Diagnostico 2019Document5 paginiMatematica 4° Ecr Diagnostico 2019LucasÎncă nu există evaluări
- Resolución UC sobre continuidad académica en pandemiaDocument2 paginiResolución UC sobre continuidad académica en pandemiaAldair De Jesus Hoyos Torres100% (1)
- Comando AGGREGATE SPSS PDFDocument6 paginiComando AGGREGATE SPSS PDFEduardo Toro ValenciaÎncă nu există evaluări
- Guía Metodológica de Elaboración de Sílabos Por CompetenciasDocument116 paginiGuía Metodológica de Elaboración de Sílabos Por CompetenciasMaria AndreaÎncă nu există evaluări
- Aprender A InvestigarDocument47 paginiAprender A InvestigarYovannaIsabelÎncă nu există evaluări
- Actividad 1 Im2Document5 paginiActividad 1 Im2Make a Change50% (2)
- Maestria Terminal en MatemáticaDocument3 paginiMaestria Terminal en MatemáticaMarcelo GuarachiÎncă nu există evaluări
- Cointegración-Procedimiento de S-JohansenDocument69 paginiCointegración-Procedimiento de S-JohansenCecilia Ordoñez LozanoÎncă nu există evaluări
- Analisis Canónico de Poblaciones y Métodos Relacionados.Document15 paginiAnalisis Canónico de Poblaciones y Métodos Relacionados.gabigaralbÎncă nu există evaluări
- Excel Ejercicio 12 Funciones SI anidadasDocument3 paginiExcel Ejercicio 12 Funciones SI anidadasHaldiram59Încă nu există evaluări
- Tarea 1 Estadistica Mejia Alvarez Jose DanielDocument10 paginiTarea 1 Estadistica Mejia Alvarez Jose DanielDaniel Mejia AlvarezÎncă nu există evaluări
- De Cero Con SPSS PDFDocument99 paginiDe Cero Con SPSS PDFFidel Pizarro CordovaÎncă nu există evaluări
- Introduccion Al SpssDocument248 paginiIntroduccion Al SpssRoberto DacuñaÎncă nu există evaluări
- Manual de Iss IbmDocument12 paginiManual de Iss IbmCesar CunalataÎncă nu există evaluări
- SPSS Fundamentos de EstadisticaDocument111 paginiSPSS Fundamentos de EstadisticaJavier Senent AparicioÎncă nu există evaluări
- Introducción SPSSDocument97 paginiIntroducción SPSSNoe MunferÎncă nu există evaluări
- Practica 1 de SPSS PDFDocument111 paginiPractica 1 de SPSS PDFMisael Lima CardenasÎncă nu există evaluări
- Introducción al software estadístico SPSS Ver 18.0Document18 paginiIntroducción al software estadístico SPSS Ver 18.0onlylen86Încă nu există evaluări
- Introduccion StatgraphicsDocument10 paginiIntroduccion Statgraphicsalucard14789632Încă nu există evaluări
- Manual SPSSDocument16 paginiManual SPSSjulio calvoÎncă nu există evaluări
- Práctica 1 - SpssDocument46 paginiPráctica 1 - SpssjanderÎncă nu există evaluări
- Guía SPSS Sesión 1Document49 paginiGuía SPSS Sesión 1David PerezÎncă nu există evaluări
- Manual StathgraphicsDocument104 paginiManual StathgraphicsJhon UrrestaÎncă nu există evaluări
- Manual de SPSS 15 IrgDocument50 paginiManual de SPSS 15 IrgMarilyn AlbertoÎncă nu există evaluări
- Tutorial de SpssDocument98 paginiTutorial de SpssJuan JoseÎncă nu există evaluări
- Módulo 03 SpssDocument12 paginiMódulo 03 SpssJota SantanderÎncă nu există evaluări
- Spss (Resumen)Document24 paginiSpss (Resumen)celia esterÎncă nu există evaluări
- SPSS25 ContenidosDocument20 paginiSPSS25 ContenidosINGRID NICOLE ALVA VILLAÎncă nu există evaluări
- Práctica Guiada Propiedad VariablesDocument41 paginiPráctica Guiada Propiedad VariablesFrank VillaÎncă nu există evaluări
- WINQSBDocument16 paginiWINQSBRosmery MoralesÎncă nu există evaluări
- Practica Guiada Propiedad VariablesDocument42 paginiPractica Guiada Propiedad VariablesElisabeth Dayana Gusman LopesÎncă nu există evaluări
- R intro estadística descriptivaDocument11 paginiR intro estadística descriptivaJulián Moreno LesmesÎncă nu există evaluări
- Practica - Intro A SPSSDocument32 paginiPractica - Intro A SPSScasaliglla25Încă nu există evaluări
- Qué Es El SPSSDocument4 paginiQué Es El SPSSfelicianoÎncă nu există evaluări
- Manual Statgraphics CenturionDocument16 paginiManual Statgraphics CenturionDabnysdÎncă nu există evaluări
- Guía de Bioestadística - SPSSDocument32 paginiGuía de Bioestadística - SPSSMau CabreraÎncă nu există evaluări
- Guía Rápida de SPSS 22Document13 paginiGuía Rápida de SPSS 22miguelpaz98Încă nu există evaluări
- Estructura de La Aplicación: Barra de TítuloDocument4 paginiEstructura de La Aplicación: Barra de TítuloJeanfrank Sicha PonceÎncă nu există evaluări
- SPSS, Entorno de TrabajoDocument8 paginiSPSS, Entorno de TrabajoSergio Samuel Mas ChanÎncă nu există evaluări
- Guion Practica - 0Document14 paginiGuion Practica - 0Dario10kltrÎncă nu există evaluări
- Analisis de Datos - StatgraphicsDocument290 paginiAnalisis de Datos - StatgraphicsRadaylin AdamesÎncă nu există evaluări
- Análisis Los Datos CuantitativosDocument4 paginiAnálisis Los Datos CuantitativosKendry SorianoÎncă nu există evaluări
- Manual de Probabilidad y Estadistica AmbientalDocument310 paginiManual de Probabilidad y Estadistica Ambientalpubliese100% (1)
- Ensayo MinitabDocument6 paginiEnsayo MinitabMoisesÎncă nu există evaluări
- Introducción al SPSSDocument37 paginiIntroducción al SPSSMarc SbustamanteÎncă nu există evaluări
- Práctica Guiada 0 StataDocument7 paginiPráctica Guiada 0 StataMateoQuiguiríÎncă nu există evaluări
- Tutorial Spss 8Document3 paginiTutorial Spss 8Ramiro PerasÎncă nu există evaluări
- R AutoaprendizajeDocument38 paginiR AutoaprendizajeToni OteroÎncă nu există evaluări
- Elementos Basicos de SPSS. Poy y Rodr+¡guezDocument14 paginiElementos Basicos de SPSS. Poy y Rodr+¡guezMiguel AngelÎncă nu există evaluări
- Instructivo Ingreso de en SpssDocument8 paginiInstructivo Ingreso de en SpssVictor AlvarezÎncă nu există evaluări
- Manual ScilabDocument84 paginiManual ScilabSulpicio Tizapa100% (3)
- Arduino MyOpenlabDocument0 paginiArduino MyOpenlabEmilio QuinterosÎncă nu există evaluări
- Derivacion de Funciones AlgebraicasDocument11 paginiDerivacion de Funciones AlgebraicasIsaac Perez MorenoÎncă nu există evaluări
- Aprenda C++ BasicoDocument70 paginiAprenda C++ BasicoSergio SantiagoÎncă nu există evaluări
- Función PolinomialDocument5 paginiFunción PolinomialEdwin Tipo MamaniÎncă nu există evaluări
- Practicas Con Arduino Nivel IDocument73 paginiPracticas Con Arduino Nivel Ialvaronevi100% (6)
- El C++ Por La Práctica, Introducción Al Lenguaje y Su FilosofíaDocument154 paginiEl C++ Por La Práctica, Introducción Al Lenguaje y Su Filosofíaapi-3775614Încă nu există evaluări
- Aprenda C++ BasicoDocument70 paginiAprenda C++ BasicoSergio SantiagoÎncă nu există evaluări
- ProbabilidadDocument17 paginiProbabilidadquatriviumfraccionesÎncă nu există evaluări
- Tema 2. Aprendes Vectores PDFDocument11 paginiTema 2. Aprendes Vectores PDFIsaac Perez MorenoÎncă nu există evaluări
- MRUADocument12 paginiMRUAIsaac Perez MorenoÎncă nu există evaluări
- Parte Vi Estadistica EmpresarialDocument36 paginiParte Vi Estadistica EmpresarialShawna Schmidt100% (2)
- Cálculo Diferencial Examen DepartamentalDocument24 paginiCálculo Diferencial Examen DepartamentalbrayanÎncă nu există evaluări
- Proyecto de Tesis Marcabal Huamachuco 4Document47 paginiProyecto de Tesis Marcabal Huamachuco 4Carlos David Arroyo LongaÎncă nu există evaluări
- Revestimientos ProtectoresDocument17 paginiRevestimientos Protectoresomar rojasÎncă nu există evaluări
- IO I - Guillermo Jimenez Lozano - Parte1Document93 paginiIO I - Guillermo Jimenez Lozano - Parte1Erick Lc50% (2)
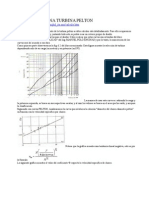
- Calculo de Una Turbina PeltonDocument3 paginiCalculo de Una Turbina PeltonDennis Enrique Herrera VelásquezÎncă nu există evaluări
- Perfil de Proyecto Diseño TérmicoDocument22 paginiPerfil de Proyecto Diseño TérmicoKlo DgArÎncă nu există evaluări
- Aplicaciones de Las Superficies A La Ingeniería CivilDocument3 paginiAplicaciones de Las Superficies A La Ingeniería Civiljose rubenÎncă nu există evaluări
- Formato - ESE - IntegraMXRH - RojoDocument21 paginiFormato - ESE - IntegraMXRH - RojoRafaelÎncă nu există evaluări
- Armamento ColectivoDocument19 paginiArmamento Colectivorobert67% (3)
- Walter A. ShewhartDocument4 paginiWalter A. ShewhartMiguel HernándezÎncă nu există evaluări
- Reglamento de Las ComunicacionesDocument660 paginiReglamento de Las Comunicacionesfrancis_128Încă nu există evaluări
- Convocatoria Beca Interacción Social y Extension Universitaria2020Document3 paginiConvocatoria Beca Interacción Social y Extension Universitaria2020Wilfredo CusipumaÎncă nu există evaluări
- Bombas de aviación: clasificación y componentesDocument50 paginiBombas de aviación: clasificación y componentesLuis DucheÎncă nu există evaluări
- Unprg - Examen Final - GptiDocument4 paginiUnprg - Examen Final - GptiVladimirSGonzalesMÎncă nu există evaluări
- Cementación de Tuberías de RevestimientoDocument4 paginiCementación de Tuberías de RevestimientoMtDaniel Acosta100% (1)
- Gomez MartinezDocument40 paginiGomez MartinezNerinaMenchónAzzaliniÎncă nu există evaluări
- Continuidad Servicio CLARODocument12 paginiContinuidad Servicio CLAROMaria del Pilar OtaloraÎncă nu există evaluări
- Capitulo 1Document40 paginiCapitulo 1Guillermo Delgado CastilloÎncă nu există evaluări
- Taller 7 PtunDocument6 paginiTaller 7 Ptunleonel Ariste ZúñigaÎncă nu există evaluări
- Guia Didactica Unidad3 Calc IIDocument7 paginiGuia Didactica Unidad3 Calc IIDiomer A. MejiasÎncă nu există evaluări
- CAPÍTULO IV Materiales AglomerantesDocument45 paginiCAPÍTULO IV Materiales AglomerantesJoseph100% (1)
- Urbanismo Del Siglo XXDocument50 paginiUrbanismo Del Siglo XXrdra69Încă nu există evaluări
- Solicitud Aprobacion Proyecto SeremiDocument8 paginiSolicitud Aprobacion Proyecto SeremiRegularización de ViviendasÎncă nu există evaluări
- 2013-03-Hermann Noll-PYMEs y Direccion de ProyectosDocument19 pagini2013-03-Hermann Noll-PYMEs y Direccion de ProyectosPablo BenitezÎncă nu există evaluări
- La Importancia de La Educación Jerome Bruner CAPÍTULO 6Document6 paginiLa Importancia de La Educación Jerome Bruner CAPÍTULO 6Elisabet Aguilar100% (1)
- Punteras Terminales RegletasDocument7 paginiPunteras Terminales Regletaslector255Încă nu există evaluări
- Conceptos Fundamentales AceroDocument101 paginiConceptos Fundamentales AceroAlfredo I. Baez RamirezÎncă nu există evaluări
- Caso de Aplicacion 1Document3 paginiCaso de Aplicacion 1AdrianaOrozcoPereiraÎncă nu există evaluări
- Organización trabajo sector transporteDocument123 paginiOrganización trabajo sector transporteJon EdortaÎncă nu există evaluări
- Linea Estrategica ALTICE DOMINICANA S.ADocument2 paginiLinea Estrategica ALTICE DOMINICANA S.AJose Fernando HernandezÎncă nu există evaluări
- Reclamo de Recupero de Energía Por Consumo No FacturadoDocument4 paginiReclamo de Recupero de Energía Por Consumo No FacturadoLEON DE JUDAÎncă nu există evaluări