S-ar putea să vă placă și
- Como Fabricar Antenas PDFDocument16 paginiComo Fabricar Antenas PDFJavier ViloriaÎncă nu există evaluări
- Teoria Musical SolfeoDocument58 paginiTeoria Musical SolfeoWilliam Moreno Reyes94% (16)
- CABLE COAXIAL, Lo Que Necesitas Saber. - EL CAJÓN DEL ELECTRÓNICODocument2 paginiCABLE COAXIAL, Lo Que Necesitas Saber. - EL CAJÓN DEL ELECTRÓNICOJavier ViloriaÎncă nu există evaluări
- Frequency - Scanner - Plug in Esp Esp Ver1Document43 paginiFrequency - Scanner - Plug in Esp Esp Ver1Javier ViloriaÎncă nu există evaluări
- Universidad Pedagógica Experimental Libertador - Venezuela - SecretaríaDocument2 paginiUniversidad Pedagógica Experimental Libertador - Venezuela - SecretaríaJavier ViloriaÎncă nu există evaluări
- Amsat Ea - Satélites OscarDocument3 paginiAmsat Ea - Satélites OscarJavier ViloriaÎncă nu există evaluări
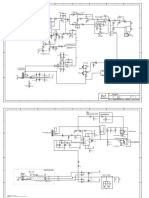
- ArrowDocument8 paginiArrowomaramilÎncă nu există evaluări
- Prevención Contra La Hepatitis ADocument2 paginiPrevención Contra La Hepatitis AJavier ViloriaÎncă nu există evaluări
- LEO, MEO, GEO, HEO y SSO - CurioseantesDocument4 paginiLEO, MEO, GEO, HEO y SSO - CurioseantesJavier ViloriaÎncă nu există evaluări
- Metotrexato en Psoriasis: ¿Es Necesaria Una Dosis de Prueba?Document4 paginiMetotrexato en Psoriasis: ¿Es Necesaria Una Dosis de Prueba?Javier ViloriaÎncă nu există evaluări
- Work FM Sats Spanish 20131010Document4 paginiWork FM Sats Spanish 20131010Javier ViloriaÎncă nu există evaluări
- Satélites, Antena Eggbeater 2, Tpm2..Radioaficion!Document6 paginiSatélites, Antena Eggbeater 2, Tpm2..Radioaficion!Javier ViloriaÎncă nu există evaluări
- Tema 1Document16 paginiTema 1vansoftÎncă nu există evaluări
- Abreviaturas fitosanitariasDocument2 paginiAbreviaturas fitosanitariasJavier ViloriaÎncă nu există evaluări
- Tema 1Document16 paginiTema 1vansoftÎncă nu există evaluări
- Merida ZoomDocument2 paginiMerida ZoomJavier ViloriaÎncă nu există evaluări
- Como Se Si El Magnetron Esta QuemadoDocument2 paginiComo Se Si El Magnetron Esta QuemadoJavier ViloriaÎncă nu există evaluări
- Tema 1Document16 paginiTema 1vansoftÎncă nu există evaluări
- Esquemas Electrico Laney para BajoDocument2 paginiEsquemas Electrico Laney para BajoJavier Viloria100% (2)
- Medidor de ROE - SWRDocument7 paginiMedidor de ROE - SWRJavier ViloriaÎncă nu există evaluări
- Modificaciones Superstar 3900Document1 paginăModificaciones Superstar 3900Javier ViloriaÎncă nu există evaluări
- Control de Temperatura Ambiente Con 555Document3 paginiControl de Temperatura Ambiente Con 555Javier ViloriaÎncă nu există evaluări
- Salsa de Ají PicanteDocument5 paginiSalsa de Ají PicanteJavier ViloriaÎncă nu există evaluări
- Sistema de alto voltaje en hornos de microondasDocument21 paginiSistema de alto voltaje en hornos de microondasalbaropernalete19_80Încă nu există evaluări
- Circuito Astable Con CDocument3 paginiCircuito Astable Con CJavier ViloriaÎncă nu există evaluări
- Para Probar Un Diodo de Alto Voltaje Es Lo Mismo Que Uno de Bajo VoltajeDocument1 paginăPara Probar Un Diodo de Alto Voltaje Es Lo Mismo Que Uno de Bajo VoltajeJavier ViloriaÎncă nu există evaluări
- CocadaDocument2 paginiCocadaJavier ViloriaÎncă nu există evaluări
- 7 pasos para hacer cañas de clarinete a manoDocument8 pagini7 pasos para hacer cañas de clarinete a manoJavier ViloriaÎncă nu există evaluări
- Recuperación Del Magnetrón en Hornos de MicroondasDocument16 paginiRecuperación Del Magnetrón en Hornos de Microondaslondon335Încă nu există evaluări
- Guasa CacaDocument6 paginiGuasa CacaJavier ViloriaÎncă nu există evaluări
- SIG Conceptos Definiciones Herramientas QGISDocument2 paginiSIG Conceptos Definiciones Herramientas QGISrmaddio1Încă nu există evaluări
- Solicitudes VariasDocument7 paginiSolicitudes VariasEd QzÎncă nu există evaluări
- Manual de Uso Software ProModel StudentDocument9 paginiManual de Uso Software ProModel StudentAngelik CastroÎncă nu există evaluări
- Curso Administración de Proyectos IndustrialesDocument8 paginiCurso Administración de Proyectos IndustrialesFirst Consulting Group100% (1)
- Arquitectura de SoftwareDocument12 paginiArquitectura de SoftwareJose LuisÎncă nu există evaluări
- Red Hopfield 38Document10 paginiRed Hopfield 38DarkSideeÎncă nu există evaluări
- Actualizar Xperia Mini ProDocument30 paginiActualizar Xperia Mini ProImelda SánchezÎncă nu există evaluări
- Propuesta Capacitacion de Emprendimiento GeneralDocument5 paginiPropuesta Capacitacion de Emprendimiento GeneralNicolas MarrugoÎncă nu există evaluări
- Distribución de Poisson: ejemplos y fórmulaDocument3 paginiDistribución de Poisson: ejemplos y fórmulaKarla DelgadoÎncă nu există evaluări
- Diferencias Entre Google Drive Presentaciones, Power Point y KeynoteDocument2 paginiDiferencias Entre Google Drive Presentaciones, Power Point y KeynoteNiels Estrada Vila44% (9)
- SAE Requisiciones de CompraDocument12 paginiSAE Requisiciones de CompraYareli GómezÎncă nu există evaluări
- Taller de Est Descriptiva 1 (EST. DESCRIPTIVA) - 1Document2 paginiTaller de Est Descriptiva 1 (EST. DESCRIPTIVA) - 1Luis GalarzaÎncă nu există evaluări
- Teoría Matemática de La AdministraciónDocument16 paginiTeoría Matemática de La AdministraciónBenjo QuispeÎncă nu există evaluări
- El Teléfono Móvil: A Continuación Subraya, Sumilla, Segmenta, Integra y Condensa El Siguiente TextoDocument1 paginăEl Teléfono Móvil: A Continuación Subraya, Sumilla, Segmenta, Integra y Condensa El Siguiente TextoOscar MagallanesÎncă nu există evaluări
- Construir Servidores Com En. NetDocument80 paginiConstruir Servidores Com En. NetjhonedwardÎncă nu există evaluări
- Temario SimDocument12 paginiTemario SimKevin RomanÎncă nu există evaluări
- Marketing de Guerrilla - Jay Conrad LevinsonDocument2 paginiMarketing de Guerrilla - Jay Conrad LevinsonRoger Sequeda100% (2)
- Aprendiendo habilidad operativaDocument2 paginiAprendiendo habilidad operativaRachele Bernard100% (1)
- Practica 2Document9 paginiPractica 2Mario GarciaÎncă nu există evaluări
- Informe JclicDocument33 paginiInforme JclicYoser MuñozÎncă nu există evaluări
- Las 5 Computadoras Más Potentes Del MundoDocument14 paginiLas 5 Computadoras Más Potentes Del MundoJESUS ARTURO DIAZ VIDAURREÎncă nu există evaluări
- Proceso selección 2 vacantes logística y asistenteDocument2 paginiProceso selección 2 vacantes logística y asistenteCristian Arevalo RicoÎncă nu există evaluări
- Administracion de Procesos IIDocument36 paginiAdministracion de Procesos IIanon_711940956Încă nu există evaluări
- Trabajo Drive Unidad 1:1005Document9 paginiTrabajo Drive Unidad 1:1005santiago torresÎncă nu există evaluări
- Miguel Castillo Curriculum VitaeDocument2 paginiMiguel Castillo Curriculum VitaeMiguel CastilloÎncă nu există evaluări
- Prácticas 1 U1Document2 paginiPrácticas 1 U1Jonny HrÎncă nu există evaluări
- Certificado Microsoft Licencia Genuina Office2013Document3 paginiCertificado Microsoft Licencia Genuina Office2013Eduardo CastilloÎncă nu există evaluări
- Flujogramas y FloxogramasDocument19 paginiFlujogramas y FloxogramasYeiSon CaalÎncă nu există evaluări
- Guia Novatos DreamboxDocument12 paginiGuia Novatos DreamboxFelix RedondoÎncă nu există evaluări
- Mapa Conceptual Hipertexto TextoDocument2 paginiMapa Conceptual Hipertexto TextoMaye TautivaÎncă nu există evaluări