S-ar putea să vă placă și
- Index - 1: The Oracle B-Tree IndexDocument6 paginiIndex - 1: The Oracle B-Tree IndexprojectnehaÎncă nu există evaluări
- Pro Oracle SQL Development: Best Practices for Writing Advanced QueriesDe la EverandPro Oracle SQL Development: Best Practices for Writing Advanced QueriesÎncă nu există evaluări
- 32 Tips For Oracle SQL Query Writing and Performance TuningDocument4 pagini32 Tips For Oracle SQL Query Writing and Performance TuningSenthil Kumar JayabalanÎncă nu există evaluări
- Oracle SQL Tuning PDFDocument70 paginiOracle SQL Tuning PDFSunitha90% (1)
- Select B.book - Key From Book B, Sales S Where B.book - Key S.book - Key (+) and S.book - Key IS NULLDocument17 paginiSelect B.book - Key From Book B, Sales S Where B.book - Key S.book - Key (+) and S.book - Key IS NULLCTPL SupportÎncă nu există evaluări
- Selecting An Index StrategyDocument13 paginiSelecting An Index StrategyMd. Shamsul HaqueÎncă nu există evaluări
- SQL Basicsof IndexesDocument15 paginiSQL Basicsof Indexesgunners42Încă nu există evaluări
- Oracle Database Administration Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesDe la EverandOracle Database Administration Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesEvaluare: 5 din 5 stele5/5 (1)
- Oracle SQL HintsDocument6 paginiOracle SQL HintsLakshmi Priya MacharlaÎncă nu există evaluări
- ORACLE SQL Materialized ViewsDocument50 paginiORACLE SQL Materialized ViewsyprajuÎncă nu există evaluări
- Analyzing Awr ReportDocument9 paginiAnalyzing Awr ReportKamalakshi RajÎncă nu există evaluări
- Oracle DBA ChecklistDocument3 paginiOracle DBA ChecklistmvineetaÎncă nu există evaluări
- PLSQL UrgentDocument3 paginiPLSQL Urgenttota111Încă nu există evaluări
- Complex SQL Writing and Performance TuningDocument4 paginiComplex SQL Writing and Performance Tuningajaymrao0% (1)
- Awr Vs AshDocument22 paginiAwr Vs Ashapi-293702630Încă nu există evaluări
- TriggersDocument4 paginiTriggerssanjay.gupta8194Încă nu există evaluări
- ORACLE PLSQL Interview DocumentDocument60 paginiORACLE PLSQL Interview DocumentRajneeshÎncă nu există evaluări
- Oracle SQL Tuning - TipsDocument3 paginiOracle SQL Tuning - TipssvdonthaÎncă nu există evaluări
- Oracle CollectionsDocument20 paginiOracle CollectionsVenkatesh Gurusamy100% (1)
- Oracle InterviewDocument13 paginiOracle Interviewsubash pradhanÎncă nu există evaluări
- Oracle StatspackDocument14 paginiOracle StatspackAhmed QaidÎncă nu există evaluări
- Performance Tuning Is An Art Which Has Lots of Section Like The BelowDocument34 paginiPerformance Tuning Is An Art Which Has Lots of Section Like The Belowsriram4docsÎncă nu există evaluări
- Trace PLDocument39 paginiTrace PLnagarajuvcc123Încă nu există evaluări
- Oracle Database Utilities Data Pump BP 2019Document9 paginiOracle Database Utilities Data Pump BP 2019Harish NaikÎncă nu există evaluări
- Oracle - Collections: Kaushik RaghupathiDocument14 paginiOracle - Collections: Kaushik RaghupathiMário Araújo100% (1)
- Oracle Dbms - Stats TipsDocument6 paginiOracle Dbms - Stats TipsHeshamAboulattaÎncă nu există evaluări
- Oracle DBADocument7 paginiOracle DBAVikas SagarÎncă nu există evaluări
- Study Material For OracleDocument229 paginiStudy Material For OracleavinashÎncă nu există evaluări
- Understanding Oracle QUERY PLAN - A 10 Minutes GuideDocument7 paginiUnderstanding Oracle QUERY PLAN - A 10 Minutes GuideVinay Goddemme100% (1)
- Oracle Interview Questions and Answers: SQL: 1. To See Current User NameDocument18 paginiOracle Interview Questions and Answers: SQL: 1. To See Current User NameswarooperÎncă nu există evaluări
- Golden Gate Oracle ReplicationDocument3 paginiGolden Gate Oracle ReplicationCynthiaÎncă nu există evaluări
- Pca15E04 Database Administration Unit-2Document11 paginiPca15E04 Database Administration Unit-2Mohammed Alramadi100% (1)
- Oracle New Material-UpdatedDocument330 paginiOracle New Material-UpdatedLakshmi Kanth100% (3)
- PLSQL CursorDocument2 paginiPLSQL CursorhkÎncă nu există evaluări
- Oracle PL/SQL Faq: Neosoft TechnologiesDocument10 paginiOracle PL/SQL Faq: Neosoft TechnologiesSagar Paul'gÎncă nu există evaluări
- MV Refresh ParallelDocument37 paginiMV Refresh ParallelBiplab ParidaÎncă nu există evaluări
- PLSQL Self NotesDocument10 paginiPLSQL Self NotesAnandRajÎncă nu există evaluări
- Oracle Performance TuningDocument9 paginiOracle Performance TuningMSG1803Încă nu există evaluări
- Oracle LocksDocument5 paginiOracle LocksSurya Surendra Reddy JangaÎncă nu există evaluări
- PLSQLDocument131 paginiPLSQLSubhobrata MukherjeeÎncă nu există evaluări
- A Comprehensive Guide To Oracle Partitioning With SamplesDocument36 paginiA Comprehensive Guide To Oracle Partitioning With SamplesSreenivasa Reddy GopireddyÎncă nu există evaluări
- PL SQLDocument8 paginiPL SQLsreejtihÎncă nu există evaluări
- Analyzing Oracle TraceDocument13 paginiAnalyzing Oracle TraceChen XuÎncă nu există evaluări
- Oracle PL SQL CursorsDocument34 paginiOracle PL SQL CursorsDSunte WilsonÎncă nu există evaluări
- Oracle Database 12c New Features For Administrators Ed 2 NEW - D77758GC20 - 1080544 - USDocument6 paginiOracle Database 12c New Features For Administrators Ed 2 NEW - D77758GC20 - 1080544 - USJinendraabhiÎncă nu există evaluări
- Kali Krishna - A: With Extensive Understanding ofDocument6 paginiKali Krishna - A: With Extensive Understanding ofvenkat uÎncă nu există evaluări
- CON3632 Nanda-SQL Tuning Without TryingDocument18 paginiCON3632 Nanda-SQL Tuning Without TryingSambasivarao KethineniÎncă nu există evaluări
- Oracle Interview QDocument105 paginiOracle Interview QLalit KumarÎncă nu există evaluări
- ORACLE-BASE - DBA Scripts For Oracle 19c, 18c, 12c, 11g, 10g, 9i and 8iDocument5 paginiORACLE-BASE - DBA Scripts For Oracle 19c, 18c, 12c, 11g, 10g, 9i and 8iVaso BekaÎncă nu există evaluări
- Oracle SQL Tuning - File IO PerformanceDocument6 paginiOracle SQL Tuning - File IO Performancelado55Încă nu există evaluări
- Oracle Questions and Answers 4Document58 paginiOracle Questions and Answers 4Ashok BabuÎncă nu există evaluări
- Oracle PLSQL Performance Tuning SyllabusDocument2 paginiOracle PLSQL Performance Tuning Syllabusoraappsforum100% (2)
- How To Stabilize The Execution Plan Using SQL PLAN BaselineDocument3 paginiHow To Stabilize The Execution Plan Using SQL PLAN BaselinenizamÎncă nu există evaluări
- Oracle SQL Language Quick Reference: 40020GC10 Production 1.0 April 1999 M08684Document56 paginiOracle SQL Language Quick Reference: 40020GC10 Production 1.0 April 1999 M08684EvaÎncă nu există evaluări
- Oracle DBADocument25 paginiOracle DBAAvinash SinghÎncă nu există evaluări
- Oracle QsDocument6 paginiOracle QshellopavaniÎncă nu există evaluări
- Data Guard Failover Test Using SQLDocument8 paginiData Guard Failover Test Using SQLKrishna8765Încă nu există evaluări
- Top CommandDocument1 paginăTop CommandredroÎncă nu există evaluări
- Sales TaxDocument2 paginiSales TaxredroÎncă nu există evaluări
- Apps Modules RelationDocument1 paginăApps Modules RelationredroÎncă nu există evaluări
- Mahmoud Muhammad Elasry: EducationDocument5 paginiMahmoud Muhammad Elasry: EducationredroÎncă nu există evaluări
- Shipping Transactions Form Action Bar Greyed OutDocument1 paginăShipping Transactions Form Action Bar Greyed OutredroÎncă nu există evaluări
- M OrgDocument13 paginiM OrgpolimersubbuÎncă nu există evaluări
- InterfacesDocument4 paginiInterfacesredroÎncă nu există evaluări
- Course Topics v1.2Document3 paginiCourse Topics v1.2redroÎncă nu există evaluări
- System Administration User GuideDocument472 paginiSystem Administration User GuideRizwan233Încă nu există evaluări
- 1) Swapping of Two Numbers and Also Without Using 3 VariablesDocument7 pagini1) Swapping of Two Numbers and Also Without Using 3 VariablesredroÎncă nu există evaluări
- Flexfields in Oracle HRMSDocument6 paginiFlexfields in Oracle HRMSredroÎncă nu există evaluări
- ChatLog 1750 Oracle SCM Prakash Teja 7 00am IST 2018-04-18 23 54Document1 paginăChatLog 1750 Oracle SCM Prakash Teja 7 00am IST 2018-04-18 23 54redroÎncă nu există evaluări
- Advanced PLSQL - UpdatedDocument81 paginiAdvanced PLSQL - UpdatedredroÎncă nu există evaluări
- InterfacesDocument4 paginiInterfacesredroÎncă nu există evaluări
- H.V.S.Vara Prasad Email: Mobile: 8688330479Document2 paginiH.V.S.Vara Prasad Email: Mobile: 8688330479redroÎncă nu există evaluări
- What Are The Interfaces in Oracle Project Costing andDocument5 paginiWhat Are The Interfaces in Oracle Project Costing andredroÎncă nu există evaluări
- Oracle Projects Is Suite of Modules Which CombinesDocument8 paginiOracle Projects Is Suite of Modules Which CombinesredroÎncă nu există evaluări
- Start MenuDocument6 paginiStart MenuredroÎncă nu există evaluări
- Room2 Innovin (To Everyone) : Room2 Innovin (To Everyone) :: Best-Practices/ Manufacturing?next - Slideshow 1Document1 paginăRoom2 Innovin (To Everyone) : Room2 Innovin (To Everyone) :: Best-Practices/ Manufacturing?next - Slideshow 1redroÎncă nu există evaluări
- Preface in This Book I Have Explained About A Complete Beginners Guide For Oracle Apps. Hope This Will Be A Great Start For BeginnersDocument209 paginiPreface in This Book I Have Explained About A Complete Beginners Guide For Oracle Apps. Hope This Will Be A Great Start For BeginnersredroÎncă nu există evaluări
- ChatLog 1750 Oracle SCM Prakash Teja 7 00am IST 2018-03-22 03 53Document1 paginăChatLog 1750 Oracle SCM Prakash Teja 7 00am IST 2018-03-22 03 53redroÎncă nu există evaluări
- Room 1 Innovinit (To Everyone) : Room 1 Innovinit (To Everyone) : Nanda (To Everyone)Document1 paginăRoom 1 Innovinit (To Everyone) : Room 1 Innovinit (To Everyone) : Nanda (To Everyone)redroÎncă nu există evaluări
- ChatLog 1750 Oracle SCM Prakash Teja 7 00am IST 2018-04-03 23 45Document1 paginăChatLog 1750 Oracle SCM Prakash Teja 7 00am IST 2018-04-03 23 45redroÎncă nu există evaluări
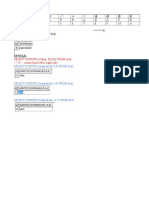
- 11 - 10 - 9 - 8 - 7 - 6 - 5 - 4 - 3 - 2 - 1 J A Y A P R A K A S H 1 2 3 4 5 6 7 8 9 10 11 L R SELECT 'Jayaprakash' FROM DualDocument1 pagină11 - 10 - 9 - 8 - 7 - 6 - 5 - 4 - 3 - 2 - 1 J A Y A P R A K A S H 1 2 3 4 5 6 7 8 9 10 11 L R SELECT 'Jayaprakash' FROM DualredroÎncă nu există evaluări
- Start MenuDocument1 paginăStart MenuredroÎncă nu există evaluări
- ChatLog 1750 Oracle SCM Prakash Teja 7 00am IST 2018-04-10 23 47Document1 paginăChatLog 1750 Oracle SCM Prakash Teja 7 00am IST 2018-04-10 23 47redroÎncă nu există evaluări
- ChatLog 1750 Oracle SCM Prakash Teja 7 00am IST 2018-04-09 23 52Document1 paginăChatLog 1750 Oracle SCM Prakash Teja 7 00am IST 2018-04-09 23 52redroÎncă nu există evaluări
- PL/SQL Runtime Engine: Without Bulk Bind Oracle ServerDocument2 paginiPL/SQL Runtime Engine: Without Bulk Bind Oracle ServerredroÎncă nu există evaluări
- ChatLog 1750 Oracle SCM Prakash Teja 7 00am IST 2018-04-17 23 58Document1 paginăChatLog 1750 Oracle SCM Prakash Teja 7 00am IST 2018-04-17 23 58redroÎncă nu există evaluări
- ChatLog 1750 Oracle SCM Prakash Teja 7 00am IST 2018-04-18 23 54Document1 paginăChatLog 1750 Oracle SCM Prakash Teja 7 00am IST 2018-04-18 23 54redroÎncă nu există evaluări
- STAND-V101Q REV1 Online PDFDocument8 paginiSTAND-V101Q REV1 Online PDFEL HANGAR DEL GUNPLAÎncă nu există evaluări
- Lapp - Pro217en - PT FSL 5x075 - Db0034302en - DatasheetDocument1 paginăLapp - Pro217en - PT FSL 5x075 - Db0034302en - DatasheetMihai BancuÎncă nu există evaluări
- Applied Machine Learning For Engineers: Introduction To NumpyDocument13 paginiApplied Machine Learning For Engineers: Introduction To NumpyGilbe TestaÎncă nu există evaluări
- Gerenciamento MensalDocument18 paginiGerenciamento MensalclailtonÎncă nu există evaluări
- Gemeni GEM-P800 - WI850a - INST PDFDocument28 paginiGemeni GEM-P800 - WI850a - INST PDFIone MaximÎncă nu există evaluări
- Unit-1 Color Models in Image and VideoDocument58 paginiUnit-1 Color Models in Image and VideosunnynnusÎncă nu există evaluări
- BIM PresentationDocument73 paginiBIM PresentationAnonymous mFO3zAqCÎncă nu există evaluări
- Design Criteria: 7. Mobile Staff Duress SystemDocument2 paginiDesign Criteria: 7. Mobile Staff Duress SystemVinay PallivalppilÎncă nu există evaluări
- Rancher Com Docs k3s Latest en Backup RestoreDocument8 paginiRancher Com Docs k3s Latest en Backup RestoreJose BoullosaÎncă nu există evaluări
- Compare Agilent Vs PerkinDocument2 paginiCompare Agilent Vs PerkinMohamad HarisÎncă nu există evaluări
- PG42-USB Vocal Microphone - Shure User GuideDocument14 paginiPG42-USB Vocal Microphone - Shure User GuidewatermelontacoÎncă nu există evaluări
- Sharad Institute of Technology Polytecnic, Yadrav: Advanced Java ProgrammingDocument58 paginiSharad Institute of Technology Polytecnic, Yadrav: Advanced Java ProgrammingPooja PatilÎncă nu există evaluări
- OAG Oauth UserGuideDocument121 paginiOAG Oauth UserGuideMatiasÎncă nu există evaluări
- 2004 CE CS Paper II C VersionDocument15 pagini2004 CE CS Paper II C Versionapi-3739994Încă nu există evaluări
- Auromage AVP 8000 SVDocument7 paginiAuromage AVP 8000 SVRadit SiregarÎncă nu există evaluări
- Meek PETS 2015 PDFDocument19 paginiMeek PETS 2015 PDFjuan100% (1)
- Data RepresentationDocument21 paginiData RepresentationVikas KumarÎncă nu există evaluări
- AES01 - EN - Automation Engine-Script - Automic UniversityDocument2 paginiAES01 - EN - Automation Engine-Script - Automic Universityneaman_ahmedÎncă nu există evaluări
- Amdahl SolutionDocument2 paginiAmdahl SolutionGOPI CHANDÎncă nu există evaluări
- Compact NSX LV432081Document2 paginiCompact NSX LV432081Lucian ChorusÎncă nu există evaluări
- Session 4 - CRISC Exam Prep Course - Domain 4 Risk and Control Monitoring and ReportingDocument83 paginiSession 4 - CRISC Exam Prep Course - Domain 4 Risk and Control Monitoring and ReportingMarco Ermini100% (8)
- Unit 2Document49 paginiUnit 2Kirty RajÎncă nu există evaluări
- Thanks For Downloading OperaDocument2 paginiThanks For Downloading OperaAlexis KarampasÎncă nu există evaluări
- LLD TemplateDocument2 paginiLLD TemplateZafar Imam Khan0% (1)
- FIL0814 DavaoDocument27 paginiFIL0814 DavaoangelomercedeblogÎncă nu există evaluări
- "Online Shopping Java Project": VisitDocument47 pagini"Online Shopping Java Project": Visithimanshi pratapÎncă nu există evaluări
- BW Interop Summary Apr2016Document61 paginiBW Interop Summary Apr2016alsvrj100% (1)
- Biomerieux Vidas PC - User ManualDocument294 paginiBiomerieux Vidas PC - User ManualLucila Figueroa Gallo100% (1)
- Defining Forecasting Methods and Rules in Oracle R12Document9 paginiDefining Forecasting Methods and Rules in Oracle R12Pritesh MoganeÎncă nu există evaluări
- GNS 430 (A) : Pilot's Guide and ReferenceDocument266 paginiGNS 430 (A) : Pilot's Guide and Referencesm789Încă nu există evaluări