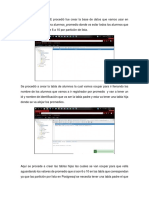
S-ar putea să vă placă și
- Evidencia 1 - Programa - Guion EntrevistaDocument2 paginiEvidencia 1 - Programa - Guion EntrevistaJOSEÎncă nu există evaluări
- Ing SoftDocument1 paginăIng SoftJOSEÎncă nu există evaluări
- Practica 1 U3 RedesDocument2 paginiPractica 1 U3 RedesJOSEÎncă nu există evaluări
- Actualizacion Del LibroDocument51 paginiActualizacion Del LibroOscar ArellanoÎncă nu există evaluări
- Planeación Taller 2 AlumnosDocument2 paginiPlaneación Taller 2 AlumnosJOSEÎncă nu există evaluări
- Conclusión Jordi Ing SoftwareDocument1 paginăConclusión Jordi Ing SoftwareJOSEÎncă nu există evaluări
- Reporte de InvestigacionDocument2 paginiReporte de InvestigacionJOSEÎncă nu există evaluări
- Capitulo 6Document10 paginiCapitulo 6Alejandra PetoÎncă nu există evaluări
- RadioDocument6 paginiRadioJOSEÎncă nu există evaluări
- E1 U4 SintesisDocument2 paginiE1 U4 SintesisJOSEÎncă nu există evaluări
- Bases de Datos Hermandad HuastecaDocument1 paginăBases de Datos Hermandad HuastecaJOSEÎncă nu există evaluări
- Temario IaDocument2 paginiTemario IaJOSEÎncă nu există evaluări
- Se Conoce Como Internet A UnaDocument11 paginiSe Conoce Como Internet A UnaJOSEÎncă nu există evaluări
- Problemática o NecesidadDocument1 paginăProblemática o NecesidadJOSEÎncă nu există evaluări
- Desarrollo apps móvilesDocument24 paginiDesarrollo apps móvilesJOSEÎncă nu există evaluări
- Particion-Hash-Con Nombres de Particiones PDFDocument1 paginăParticion-Hash-Con Nombres de Particiones PDFJOSEÎncă nu există evaluări
- Sistemas ProgramablesDocument1 paginăSistemas ProgramablesJOSEÎncă nu există evaluări
- Particion Por ListaDocument2 paginiParticion Por ListaJOSEÎncă nu există evaluări
- Particion-Hash-Con Nombres de Particiones PDFDocument1 paginăParticion-Hash-Con Nombres de Particiones PDFJOSEÎncă nu există evaluări
- Unidad Ii - S.ODocument66 paginiUnidad Ii - S.OJOSEÎncă nu există evaluări
- Qué Es SambaDocument1 paginăQué Es SambaJOSEÎncă nu există evaluări
- Temario - Sistemas ProgramablesDocument2 paginiTemario - Sistemas ProgramablesJOSEÎncă nu există evaluări
- 000003Document3 pagini000003JOSEÎncă nu există evaluări
- Particion-Hash-Con Nombres de Particiones PDFDocument1 paginăParticion-Hash-Con Nombres de Particiones PDFJOSEÎncă nu există evaluări
- Se Conoce Como Internet A UnaDocument11 paginiSe Conoce Como Internet A UnaJOSEÎncă nu există evaluări
- Significado de NullDocument73 paginiSignificado de Nullbrokeeen100% (3)
- CODIGODocument2 paginiCODIGOJOSEÎncă nu există evaluări
- Directivas de Windows Serve 2008Document3 paginiDirectivas de Windows Serve 2008JOSEÎncă nu există evaluări
- API PresentacionDocument58 paginiAPI PresentacionrobertuxwiredÎncă nu există evaluări
- Directivas de Windows Serve 2008Document3 paginiDirectivas de Windows Serve 2008JOSEÎncă nu există evaluări
- Resolución de problemas de ángulos y triángulos en ríos y ecuaciones trigonométricasDocument3 paginiResolución de problemas de ángulos y triángulos en ríos y ecuaciones trigonométricasrulvilloÎncă nu există evaluări
- Algoritmo Grasp - Corte de GuillotinaDocument37 paginiAlgoritmo Grasp - Corte de GuillotinaCharlie Tarazona VargasÎncă nu există evaluări
- S12.s01 CLASE 12 PYADocument11 paginiS12.s01 CLASE 12 PYAjohana ortegalÎncă nu există evaluări
- Acta de Comite de Obra - San Agustin - ChaquiraDocument4 paginiActa de Comite de Obra - San Agustin - ChaquiraKAREN ROJASÎncă nu există evaluări
- Migración datos 40Document3 paginiMigración datos 40Ivan TerrientesÎncă nu există evaluări
- Módulo 1: Generalidades y Ventas en SAPDocument2 paginiMódulo 1: Generalidades y Ventas en SAPPersi MoralesÎncă nu există evaluări
- Refinería minimiza costos comprando petróleo crudoDocument5 paginiRefinería minimiza costos comprando petróleo crudoJose Luis Condori PintoÎncă nu există evaluări
- Instalacion SSHDocument6 paginiInstalacion SSHGustavoÎncă nu există evaluări
- Entrenamiento CPC100-CP TD1Document104 paginiEntrenamiento CPC100-CP TD1Armando Estrada Mendez67% (3)
- Desde La Primera Hasta La Cuarta Revolución IndustrialDocument4 paginiDesde La Primera Hasta La Cuarta Revolución IndustrialAgustin Caal AsigÎncă nu există evaluări
- Caso Practico Unidad 2 Gerencia de Proyectos II PDFDocument4 paginiCaso Practico Unidad 2 Gerencia de Proyectos II PDFIvanCamiloDazaCruzÎncă nu există evaluări
- Tecnologia e Informatica Clei 5 Guia 1 Periodo 2Document15 paginiTecnologia e Informatica Clei 5 Guia 1 Periodo 2yofa menaÎncă nu există evaluări
- LicenciasDocument4 paginiLicenciasFabio Durán VerdugoÎncă nu există evaluări
- Competencias Transversales A Las ÁreasDocument6 paginiCompetencias Transversales A Las ÁreasAFERNANDOCCÎncă nu există evaluări
- Examen U2 PROYECTODocument8 paginiExamen U2 PROYECTOAngela FavoÎncă nu există evaluări
- Sistema de Numeracion BinarioDocument34 paginiSistema de Numeracion BinarioLuis PecciÎncă nu există evaluări
- Ejercicios de AlgoritmosDocument9 paginiEjercicios de Algoritmoslucas100% (1)
- Act 3 Modelo Matematico en Hoja de Calculo 1895499 IMEDocument7 paginiAct 3 Modelo Matematico en Hoja de Calculo 1895499 IMERubi GallegosÎncă nu există evaluări
- Instagram Marketing y Publicidad en Facebook - Lo Que Ares (Spanish Edition) - Mark Hollister - Susan SmithDocument280 paginiInstagram Marketing y Publicidad en Facebook - Lo Que Ares (Spanish Edition) - Mark Hollister - Susan SmithPablo Edgardo RubioÎncă nu există evaluări
- Redes BayesianasDocument10 paginiRedes BayesianaskennyÎncă nu există evaluări
- Registro de Conversaciones Curso WiFi Con PIC IoT 2020 - 04 - 11 13 - 57Document11 paginiRegistro de Conversaciones Curso WiFi Con PIC IoT 2020 - 04 - 11 13 - 57Bri GeorgeÎncă nu există evaluări
- Actividad N°1Document4 paginiActividad N°1Pablo Morales arceÎncă nu există evaluări
- Contrato CompletoDocument6 paginiContrato Completomesa controlÎncă nu există evaluări
- Tarea Explorador de ArchivosDocument6 paginiTarea Explorador de ArchivosCuritaCuritaÎncă nu există evaluări
- Clase de Autocad Civil 2017 (21-01-2017)Document39 paginiClase de Autocad Civil 2017 (21-01-2017)Richar Ruben Jorge BerrocalÎncă nu există evaluări
- Inteligencia Artificial Sistemas Basados en Reglas 02 JRPDocument29 paginiInteligencia Artificial Sistemas Basados en Reglas 02 JRPVega LuisÎncă nu există evaluări
- INNOVO - Presentación ERP ComercialDocument11 paginiINNOVO - Presentación ERP ComercialZOCO MARKETÎncă nu există evaluări
- Manual Shaft 200Document93 paginiManual Shaft 200Israel RiquelmeÎncă nu există evaluări
- Niveles OSI y funcionesDocument5 paginiNiveles OSI y funcionesRobin PaterninaÎncă nu există evaluări
- Linea Del Tiempo Del InternetDocument1 paginăLinea Del Tiempo Del InternetHanna SahianyÎncă nu există evaluări