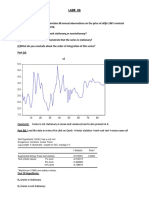
S-ar putea să vă placă și
- AsistDocument18 paginiAsistdeviÎncă nu există evaluări
- Inductive and Deductive Methods of TeachingDocument2 paginiInductive and Deductive Methods of TeachingVasugi Kuppan100% (1)
- Assignment 2 Mba 652 PDFDocument11 paginiAssignment 2 Mba 652 PDFRishav Shiv RanjanÎncă nu există evaluări
- Chapter 3 Homework (Take 2)Document7 paginiChapter 3 Homework (Take 2)Jaime Andres Chica PÎncă nu există evaluări
- Assignment 1Document8 paginiAssignment 1kowletÎncă nu există evaluări
- 312 F 12 Logistic Regression With R1Document8 pagini312 F 12 Logistic Regression With R1chandro2007Încă nu există evaluări
- QuasilikelihoodDocument14 paginiQuasilikelihoodK6 LyonÎncă nu există evaluări
- El Efecto Más Grande Es El de "D" Con Un Valor DE 2.43625Document6 paginiEl Efecto Más Grande Es El de "D" Con Un Valor DE 2.43625Carol CelyÎncă nu există evaluări
- R Programming Exam With SolutionsDocument9 paginiR Programming Exam With SolutionsJohana Coen JanssenÎncă nu există evaluări
- Outlier DetectionDocument41 paginiOutlier DetectionTanishi GuptaÎncă nu există evaluări
- Spring07 OBrien TDocument40 paginiSpring07 OBrien Tsatztg6089Încă nu există evaluări
- HW 6.8,6.12Document5 paginiHW 6.8,6.12AlbertEngÎncă nu există evaluări
- Econometrics FinalDocument16 paginiEconometrics FinalDanikaLiÎncă nu există evaluări
- Multinomial Logit Models With R: Library (Mlogit)Document8 paginiMultinomial Logit Models With R: Library (Mlogit)Páblo DiasÎncă nu există evaluări
- SAS Project 2 (31.3 Pts. + 4.2 Bonus) Due Dec. 8: 1. Confidence Intervals/Hypothesis TestsDocument21 paginiSAS Project 2 (31.3 Pts. + 4.2 Bonus) Due Dec. 8: 1. Confidence Intervals/Hypothesis TestsAshwani PasrichaÎncă nu există evaluări
- Matlab-STATISTICAL MODELS AND METHODS FOR FINANCIAL MARKETSDocument13 paginiMatlab-STATISTICAL MODELS AND METHODS FOR FINANCIAL MARKETSGonzalo SaavedraÎncă nu există evaluări
- Felix Suriel Duran: Presentado ADocument7 paginiFelix Suriel Duran: Presentado Aorlando venturaÎncă nu există evaluări
- Advanced Research Skills: Glms Ii Binomial FamilyDocument18 paginiAdvanced Research Skills: Glms Ii Binomial FamilyDiego MorenoÎncă nu există evaluări
- 9805 MBAex PredAnalBigDataMar22Document11 pagini9805 MBAex PredAnalBigDataMar22harishcoolanandÎncă nu există evaluări
- Logistic Regression (With R) : 1 TheoryDocument15 paginiLogistic Regression (With R) : 1 TheoryrattonxÎncă nu există evaluări
- RegressionDocument46 paginiRegressionGiannis GalanakisÎncă nu există evaluări
- BZAN 535: Linear RegressionDocument11 paginiBZAN 535: Linear RegressionMotasimaÎncă nu există evaluări
- Syntax Dan HasilnyaDocument6 paginiSyntax Dan HasilnyafitriyaniÎncă nu există evaluări
- Lab 3. Linear Regression 230223Document7 paginiLab 3. Linear Regression 230223ruso100% (1)
- PLDocument5 paginiPLMy SpotifyÎncă nu există evaluări
- HW 3 Econ 6Document5 paginiHW 3 Econ 6SEN GAOÎncă nu există evaluări
- 04 BasicAnalysesDocument44 pagini04 BasicAnalysesCotta LeeÎncă nu există evaluări
- QMDocument3 paginiQMPushpaÎncă nu există evaluări
- Solutions Chapter6Document19 paginiSolutions Chapter6yitagesu eshetuÎncă nu există evaluări
- Logistic RegressionDocument49 paginiLogistic RegressionAkash M KÎncă nu există evaluări
- Carolina Found The Following Site With An Example of Unit Root TestsDocument10 paginiCarolina Found The Following Site With An Example of Unit Root Testsneman018100% (1)
- Random Effects ModelsDocument37 paginiRandom Effects Modelshubik38Încă nu există evaluări
- Stats For Data Science Assignment-2: NAME: Rakesh Choudhary ROLL NO.-167 BATCH-Big Data B3Document9 paginiStats For Data Science Assignment-2: NAME: Rakesh Choudhary ROLL NO.-167 BATCH-Big Data B3Rakesh ChoudharyÎncă nu există evaluări
- Multiple Linear RegressionDocument14 paginiMultiple Linear RegressionNamdev100% (1)
- 0483 - Trần Công Sơn - Bài Tập Số 2Document12 pagini0483 - Trần Công Sơn - Bài Tập Số 20483Trần Công SơnÎncă nu există evaluări
- Isye4031 Regression and Forecasting Practice Problems 2 Fall 2014Document5 paginiIsye4031 Regression and Forecasting Practice Problems 2 Fall 2014cthunder_1Încă nu există evaluări
- Homework2 Chapter4 SolutionDocument7 paginiHomework2 Chapter4 SolutionncÎncă nu există evaluări
- HW1 - Problem 3.4.1: General ModelDocument6 paginiHW1 - Problem 3.4.1: General Model梁嫚芳Încă nu există evaluări
- Solutions Chapter6Document19 paginiSolutions Chapter6Zodwa MngometuluÎncă nu există evaluări
- Final EM2 2021 Perm 1 VNov22Document14 paginiFinal EM2 2021 Perm 1 VNov22Il MulinaioÎncă nu există evaluări
- 7708 - MBA PredAnanBigDataNov21Document11 pagini7708 - MBA PredAnanBigDataNov21Indian Lizard KingÎncă nu există evaluări
- Advance Stats Problem Statement 3 AnalysisDocument5 paginiAdvance Stats Problem Statement 3 AnalysisPratyasha SinghÎncă nu există evaluări
- I. Estimating The Linear Regression ModelDocument10 paginiI. Estimating The Linear Regression ModelWiktor MyszorÎncă nu există evaluări
- Classification and Regression TreesDocument48 paginiClassification and Regression TreesHaq KaleemÎncă nu există evaluări
- Regression Analysis: Kriti Bardhan Gupta Kriti@iiml - Ac.inDocument16 paginiRegression Analysis: Kriti Bardhan Gupta Kriti@iiml - Ac.inPavan PearliÎncă nu există evaluări
- Nur Syuhada Binti Safaruddin - Rba2403a - 2020819322Document6 paginiNur Syuhada Binti Safaruddin - Rba2403a - 2020819322syuhadasafar000Încă nu există evaluări
- Homework Assignment 3 Homework Assignment 3Document10 paginiHomework Assignment 3 Homework Assignment 3Ido AkovÎncă nu există evaluări
- Lab 6Document6 paginiLab 6AMQÎncă nu există evaluări
- Logistic RegressionDocument49 paginiLogistic Regressiontamim habybyÎncă nu există evaluări
- Logistic Regression With RDocument5 paginiLogistic Regression With RSelin PandeyÎncă nu există evaluări
- Probit and Logit Models R Program and OutputDocument6 paginiProbit and Logit Models R Program and Outputakhil sharmaÎncă nu există evaluări
- Dar Solved AnsDocument20 paginiDar Solved AnsDevÎncă nu există evaluări
- HW3 Solutions - Stats 500: Problem 1Document4 paginiHW3 Solutions - Stats 500: Problem 1Souleymane CoulibalyÎncă nu există evaluări
- Censoring & TruncationDocument14 paginiCensoring & TruncationkinshuksÎncă nu există evaluări
- Marginal Effects For Continuous Variables: Richard Williams, University of Notre Dame, Last Revised January 29, 2019Document12 paginiMarginal Effects For Continuous Variables: Richard Williams, University of Notre Dame, Last Revised January 29, 2019陈文源Încă nu există evaluări
- R Intro 2011Document115 paginiR Intro 2011marijkepauwelsÎncă nu există evaluări
- Analyzing GRT Data in StataDocument17 paginiAnalyzing GRT Data in StataAnonymous EAineTizÎncă nu există evaluări
- Analisis JalurDocument30 paginiAnalisis JaluradityanugrahassÎncă nu există evaluări
- Econometrics 2021Document9 paginiEconometrics 2021Yusuf ShotundeÎncă nu există evaluări
- Cash - Flow Analysis Model PDFDocument5 paginiCash - Flow Analysis Model PDFSohel RanaÎncă nu există evaluări
- Kyc FormDocument6 paginiKyc FormSohel RanaÎncă nu există evaluări
- About The Report: Management &Document89 paginiAbout The Report: Management &Sohel RanaÎncă nu există evaluări
- Account Activity: Mohakhali BranchDocument50 paginiAccount Activity: Mohakhali BranchSohel RanaÎncă nu există evaluări
- Final Report On Ring Road Br.Document13 paginiFinal Report On Ring Road Br.Sohel RanaÎncă nu există evaluări
- A Question of Ethics Towards A Common GoalDocument31 paginiA Question of Ethics Towards A Common GoalSohel RanaÎncă nu există evaluări
- A Modified English Auction: Filippo Balestrieri MIT HP LabDocument22 paginiA Modified English Auction: Filippo Balestrieri MIT HP LabSohel RanaÎncă nu există evaluări
- Sub: Notice To Vacate: Brig. Gen. Belal Uddin MahmoodDocument1 paginăSub: Notice To Vacate: Brig. Gen. Belal Uddin MahmoodSohel RanaÎncă nu există evaluări
- 17-BSA 700 and 705Document16 pagini17-BSA 700 and 705Sohel Rana100% (1)
- Submitted ToDocument1 paginăSubmitted ToSohel RanaÎncă nu există evaluări
- Regression Analysis - CheatsheetDocument9 paginiRegression Analysis - Cheatsheetvasanth reddy nallagunduÎncă nu există evaluări
- Hypothesis TestingDocument196 paginiHypothesis TestingSahil KumarÎncă nu există evaluări
- Chapter Three: Estimation of Multiple Linear Regression ModelDocument18 paginiChapter Three: Estimation of Multiple Linear Regression ModelGetachew HussenÎncă nu există evaluări
- Learning Objectives: Nature of Inquiry and ResearchDocument47 paginiLearning Objectives: Nature of Inquiry and ResearchVince Darwin GabonaÎncă nu există evaluări
- Insights On Discrete StructureDocument118 paginiInsights On Discrete Structuresuraj poudelÎncă nu există evaluări
- Unit 5: Test of Significance/Hypothesis Testing (Topics 20, 22, 23)Document24 paginiUnit 5: Test of Significance/Hypothesis Testing (Topics 20, 22, 23)Riddhiman PalÎncă nu există evaluări
- Philosophy of Man With LogicDocument5 paginiPhilosophy of Man With LogicbryÎncă nu există evaluări
- Skittles Term Project Final PaperDocument15 paginiSkittles Term Project Final Paperapi-339884559Încă nu există evaluări
- ch09 Quantitative FinanceDocument41 paginich09 Quantitative FinanceYogeeta RughooÎncă nu există evaluări
- Advanced Statistic2Document7 paginiAdvanced Statistic2Muhammad Aly Sa'idÎncă nu există evaluări
- Metode Forecasting: Lintang Perwitasari P2D018006 Aziz Pradana P2D018007Document26 paginiMetode Forecasting: Lintang Perwitasari P2D018006 Aziz Pradana P2D018007Aziz PradanaÎncă nu există evaluări
- Math 153 ProjectDocument8 paginiMath 153 Projectapi-521310088Încă nu există evaluări
- Statistical Significance HypothesisDocument17 paginiStatistical Significance HypothesisSherwan R ShalÎncă nu există evaluări
- Business Econometrics Lecture Notes Quiz Econ2271Document2 paginiBusiness Econometrics Lecture Notes Quiz Econ2271gedtmaxÎncă nu există evaluări
- WALTZ 1979 - Theory of International Pol PDFDocument129 paginiWALTZ 1979 - Theory of International Pol PDFTuğba YürükÎncă nu există evaluări
- Chapter 4 Basic Estimation TechniquesDocument20 paginiChapter 4 Basic Estimation TechniquesNadeen ZÎncă nu există evaluări
- Module6 ADGEDocument11 paginiModule6 ADGEHersie BundaÎncă nu există evaluări
- Fixed-E Ect Panel Threshold Model Using StataDocument14 paginiFixed-E Ect Panel Threshold Model Using StataAli JamaliÎncă nu există evaluări
- Reading To Write From Source Texts - 2021Document95 paginiReading To Write From Source Texts - 2021Guillermo PandoÎncă nu există evaluări
- 2278 9131 1 PB PDFDocument9 pagini2278 9131 1 PB PDFOlivia GiovanniÎncă nu există evaluări
- New GEC 104 SyllabusDocument11 paginiNew GEC 104 SyllabusCharlyne Mari Flores100% (1)
- Lesson 1 - Inductive & Deductive Reasoning (Midterm Coverage)Document19 paginiLesson 1 - Inductive & Deductive Reasoning (Midterm Coverage)NATIVIDAD BANATAOÎncă nu există evaluări
- PhiloDocument26 paginiPhiloIzeyk VillaflorÎncă nu există evaluări
- Practice Problems - Part 1Document6 paginiPractice Problems - Part 1Pratip BeraÎncă nu există evaluări
- Spss 3Document27 paginiSpss 3Eleni BirhanuÎncă nu există evaluări
- Analysis of Variance ANOVADocument3 paginiAnalysis of Variance ANOVAnorhanifah matanogÎncă nu există evaluări
- Monthly Demand ABC CorporationDocument9 paginiMonthly Demand ABC CorporationVivek NairÎncă nu există evaluări
- Advantages of Deductive ApproachDocument3 paginiAdvantages of Deductive ApproachJaimie Paz Opinion-AngÎncă nu există evaluări
- X1 Ke Y: Variables Entered/RemovedDocument3 paginiX1 Ke Y: Variables Entered/RemovedAgeng FitriyantoÎncă nu există evaluări