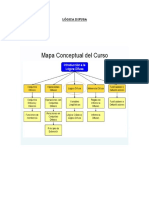
S-ar putea să vă placă și
- Introducción a las técnicas de lógica difusaDocument14 paginiIntroducción a las técnicas de lógica difusaJorgeJordanÎncă nu există evaluări
- Logica Difusa en La Vida DiariaDocument39 paginiLogica Difusa en La Vida Diariacharlybobo0% (1)
- Logica Difusa en La Vida DiariaDocument39 paginiLogica Difusa en La Vida DiariaJL AlarconÎncă nu există evaluări
- Lógica difusa: introducción a conjuntos difusosDocument48 paginiLógica difusa: introducción a conjuntos difusosKarla Arleth Santos LauraÎncă nu există evaluări
- Definicion Con Ceptos Basicos Logica Difusa PDFDocument60 paginiDefinicion Con Ceptos Basicos Logica Difusa PDFelectrocesÎncă nu există evaluări
- Introducción A La Lógica Difusa y Sus AplicacionesDocument15 paginiIntroducción A La Lógica Difusa y Sus Aplicacionesvamadi04Încă nu există evaluări
- Lógica BorrosaDocument19 paginiLógica BorrosaO Saul Paco Ramos100% (2)
- Lógica difusa y conjuntos difusos en la representación de la incertidumbreDocument8 paginiLógica difusa y conjuntos difusos en la representación de la incertidumbreantonio Gil AdrianzenÎncă nu există evaluări
- Lógica difusa conceptos básicosDocument8 paginiLógica difusa conceptos básicosmanuelÎncă nu există evaluări
- Logica TerminadoDocument6 paginiLogica TerminadoVíctor BacaÎncă nu există evaluări
- Lógicas no clásicasDocument11 paginiLógicas no clásicasJeanÎncă nu există evaluări
- Introducción A La Lógica DifusaDocument25 paginiIntroducción A La Lógica DifusalokoferoÎncă nu există evaluări
- Logica Difusa MatematicaDocument4 paginiLogica Difusa MatematicaLolero LuleroÎncă nu există evaluări
- Fuzzy 1Document5 paginiFuzzy 1voidreaderÎncă nu există evaluări
- Logica DifusaDocument62 paginiLogica DifusaYuridiana MargalliÎncă nu există evaluări
- Lógica difusa: conceptos básicos y aplicacionesDocument13 paginiLógica difusa: conceptos básicos y aplicacionesCarlos C RÎncă nu există evaluări
- Funciones y variables: dominio, rango y definiciónDocument9 paginiFunciones y variables: dominio, rango y definiciónEduardo JassoÎncă nu există evaluări
- Logica DifusaDocument15 paginiLogica DifusaLucero Luz Sanchez FaquinÎncă nu există evaluări
- Tutorial de Introducción de Lógica BorrosaDocument35 paginiTutorial de Introducción de Lógica BorrosaArmando CajahuaringaÎncă nu există evaluări
- Actividad 1 T4 10% Ensayo JatvDocument12 paginiActividad 1 T4 10% Ensayo JatvAbel torresÎncă nu există evaluări
- Lógica 2do Parcial Spers FCE UbaDocument6 paginiLógica 2do Parcial Spers FCE UbaAdrián CastioniÎncă nu există evaluări
- Teoría de control difuso enDocument15 paginiTeoría de control difuso enRenato Angel Basurto MonteroÎncă nu există evaluări
- Unidad II Lógica DifusaDocument16 paginiUnidad II Lógica DifusananitodigitalÎncă nu există evaluări
- Introducción a la lógica borrosa y sus aplicaciones en robóticaDocument7 paginiIntroducción a la lógica borrosa y sus aplicaciones en robóticaDiRoGuÎncă nu există evaluări
- Trabajo de Calculo! DominimoDocument8 paginiTrabajo de Calculo! DominimoLayla AguilarÎncă nu există evaluări
- Logica Borosa Apuntes U3Document18 paginiLogica Borosa Apuntes U3Eduardo AguirreÎncă nu există evaluări
- Logica DifusaDocument41 paginiLogica DifusamargutkbgÎncă nu există evaluări
- Logica DifusaDocument39 paginiLogica DifusaMauricio TercerosÎncă nu există evaluări
- 1 Los Conjuntos BorrososDocument25 pagini1 Los Conjuntos BorrosossouthdreamerÎncă nu există evaluări
- SCD Cap I IiDocument88 paginiSCD Cap I IicalixtoescobarÎncă nu există evaluări
- Guia 02Document27 paginiGuia 02Nicolas Villalba DavidÎncă nu există evaluări
- Logica DifusaDocument50 paginiLogica DifusaErick GuittonÎncă nu există evaluări
- Funcion de PertenenciaDocument5 paginiFuncion de PertenenciaJossy H AtocheÎncă nu există evaluări
- Estrada, Luis - Cuanta Filosofía Hay en Una Tabla de VerdadDocument13 paginiEstrada, Luis - Cuanta Filosofía Hay en Una Tabla de VerdadAslam Gastòn HernàndezÎncă nu există evaluări
- Sistema de Control Borroso Conceptos y Teoría FundamentalDocument9 paginiSistema de Control Borroso Conceptos y Teoría FundamentalOtto StierÎncă nu există evaluări
- Analisis Matematico ModuloDocument41 paginiAnalisis Matematico ModuloZeke100% (1)
- Actividad Fuzzy 2Document15 paginiActividad Fuzzy 2milena delgadounadÎncă nu există evaluări
- 01.2b. BD Borrosa. Base de Conocimiento Borrosa-ILMDocument32 pagini01.2b. BD Borrosa. Base de Conocimiento Borrosa-ILMEverth RamosÎncă nu există evaluări
- Universidad Católica de Santa MaríaDocument13 paginiUniversidad Católica de Santa MaríaBianca Rivera CornejoÎncă nu există evaluări
- Matemática I 2020: Matemático Invitado: Pierre de FermatDocument39 paginiMatemática I 2020: Matemático Invitado: Pierre de FermatGorge GilÎncă nu există evaluări
- Mate I - Capítulo 2 - Conjuntos y Funciones-2020Document39 paginiMate I - Capítulo 2 - Conjuntos y Funciones-2020lzÎncă nu există evaluări
- Rodriguez Martinez MariaDocument39 paginiRodriguez Martinez MariaSD FelipeÎncă nu există evaluări
- Logica DifusaDocument32 paginiLogica DifusaJonathanÎncă nu există evaluări
- Mate I - Capítulo 2 Conjuntos y Funciones-2018Document30 paginiMate I - Capítulo 2 Conjuntos y Funciones-2018Ramiro PistoiaÎncă nu există evaluări
- LimitesDocument10 paginiLimitesjoextremoÎncă nu există evaluări
- Conjunto DifusoDocument5 paginiConjunto DifusoRecuerdos InolvidablesÎncă nu există evaluări
- Guia MATDocument57 paginiGuia MATDaniela BecerraÎncă nu există evaluări
- Regla de L'Hospital Derivadas Implícitas Teorema de Rolle Teorema Del Valor Medio (Lagrange) y Teorema de CauchyDocument22 paginiRegla de L'Hospital Derivadas Implícitas Teorema de Rolle Teorema Del Valor Medio (Lagrange) y Teorema de CauchyGabriel AlejandroÎncă nu există evaluări
- Fuzzy LogicDocument42 paginiFuzzy Logiccrvalencia2009Încă nu există evaluări
- Semana 2Document36 paginiSemana 2Hernesto ValverdeÎncă nu există evaluări
- Preferencias Del ConsumidorDocument10 paginiPreferencias Del ConsumidorYolanda HernándezÎncă nu există evaluări
- Logica DifusaDocument12 paginiLogica DifusaJair HerreraÎncă nu există evaluări
- (Matematicas) Funciones de Variable Compleja (Julio Rey Pastor) (MadMath)Document25 pagini(Matematicas) Funciones de Variable Compleja (Julio Rey Pastor) (MadMath)Leanza Paola100% (1)
- Teoria de Los Conjuntos BorrososDocument10 paginiTeoria de Los Conjuntos BorrososisidroparodiÎncă nu există evaluări
- Logica FuzzyDocument8 paginiLogica FuzzyAngelica Maria Abanto VeraÎncă nu există evaluări
- Claridad Ambigua: Explora el Arte de la Incertidumbre en la Lógica DifusaDe la EverandClaridad Ambigua: Explora el Arte de la Incertidumbre en la Lógica DifusaÎncă nu există evaluări
- Contra La Empatía - PAUL BLOOMDocument510 paginiContra La Empatía - PAUL BLOOMEdward Ritchie100% (7)
- 9 Poderosas Serpientes de La Historia y La Mitología - HISTORIADocument5 pagini9 Poderosas Serpientes de La Historia y La Mitología - HISTORIAEdward RitchieÎncă nu există evaluări
- Estructuras Clinicas LacanDocument6 paginiEstructuras Clinicas Lacanrayden015Încă nu există evaluări
- Astrología para Tiempos DifícilesDocument18 paginiAstrología para Tiempos DifícilesRodrigo Zúñiga García71% (7)
- ApoyoSocioEmotivoNiñosDocument7 paginiApoyoSocioEmotivoNiñosEdward RitchieÎncă nu există evaluări
- 02 Hoja de Respuesta - Test de Tipología de JungDocument1 pagină02 Hoja de Respuesta - Test de Tipología de JungEdward RitchieÎncă nu există evaluări
- GUESE LAMSANG - Kamalashila Estadios de MeditacionDocument37 paginiGUESE LAMSANG - Kamalashila Estadios de MeditacionEdward RitchieÎncă nu există evaluări
- MMEG 15 Escala Desgaste Ocupacional Burnout EDODocument2 paginiMMEG 15 Escala Desgaste Ocupacional Burnout EDOEdward RitchieÎncă nu există evaluări
- ApoyoSocioEmotivoNiñosDocument7 paginiApoyoSocioEmotivoNiñosEdward RitchieÎncă nu există evaluări
- La Identidad y La Ausencia Del Yo en El BudismoDocument5 paginiLa Identidad y La Ausencia Del Yo en El BudismoMartha Inés Franco EÎncă nu există evaluări
- L27 Anm DepresionDocument410 paginiL27 Anm DepresionAnita Pérez50% (2)
- Bohm Krishnamurti La Cuestión Del ConocimientoDocument252 paginiBohm Krishnamurti La Cuestión Del ConocimientogonzaloÎncă nu există evaluări
- El Mal Paraje y La Mala Hora: Notas Sobre La Violencia Naturalista Hacia El Saber Médico AndinoDocument14 paginiEl Mal Paraje y La Mala Hora: Notas Sobre La Violencia Naturalista Hacia El Saber Médico AndinoEdward RitchieÎncă nu există evaluări
- La Influencia de Los Estilos de Personalidad en La Elección de Estrategias de Afrontamiento Ante Situaciones de ExamenDocument22 paginiLa Influencia de Los Estilos de Personalidad en La Elección de Estrategias de Afrontamiento Ante Situaciones de ExamenEdward RitchieÎncă nu există evaluări
- Tomo 6 Boroko SarabanderoDocument110 paginiTomo 6 Boroko SarabanderoOkanLashe100% (2)
- Julio Andrés Spinel Luna - El Psicólogo - Retórico, Sofista o Filósofo - Acheronta 22Document31 paginiJulio Andrés Spinel Luna - El Psicólogo - Retórico, Sofista o Filósofo - Acheronta 22Edward RitchieÎncă nu există evaluări
- Conferencia: ¿Qué Es Feng Shui? - María Fernanda GómezDocument54 paginiConferencia: ¿Qué Es Feng Shui? - María Fernanda GómezEdward RitchieÎncă nu există evaluări
- El Método Psicoanalítico de Freud (Texto)Document37 paginiEl Método Psicoanalítico de Freud (Texto)Ricardo NoyolaÎncă nu există evaluări
- Terapeutas tradicionales andinos en contexto de cambioDocument7 paginiTerapeutas tradicionales andinos en contexto de cambioRaulÎncă nu există evaluări
- 1320PlanetaryGeomancyespanollibrito PDFDocument8 pagini1320PlanetaryGeomancyespanollibrito PDFLinKs FlaKesÎncă nu există evaluări
- CivismoDocument7 paginiCivismoJohn DoexÎncă nu există evaluări
- Citas de Mao sobre filosofía y luchaDocument16 paginiCitas de Mao sobre filosofía y luchaEdward RitchieÎncă nu există evaluări
- Psicoterapia Del Oprimido - MoffatDocument137 paginiPsicoterapia Del Oprimido - MoffatManuel Latorres100% (3)
- Espiritismo y Psiquiatría en Buenos Aires A Fines Del Siglo Xix. Un Análisis de La Obra de Wilfrido Rodríguez de La Torre (1889)Document9 paginiEspiritismo y Psiquiatría en Buenos Aires A Fines Del Siglo Xix. Un Análisis de La Obra de Wilfrido Rodríguez de La Torre (1889)Edward RitchieÎncă nu există evaluări
- La Perspectiva de Género en El Curanderismo en El Norte Del PerúDocument46 paginiLa Perspectiva de Género en El Curanderismo en El Norte Del PerúEdward RitchieÎncă nu există evaluări
- Por La Mano Del Hombre. Prácticas y Creencias Sobre Chamanismo y Curandería en México y El PerúDocument2 paginiPor La Mano Del Hombre. Prácticas y Creencias Sobre Chamanismo y Curandería en México y El PerúEdward RitchieÎncă nu există evaluări
- Almanaque EspiritoDocument76 paginiAlmanaque EspiritoSergio CacedaÎncă nu există evaluări
- Habilidades terapéuticas: características del terapeuta y relación con el clienteDocument70 paginiHabilidades terapéuticas: características del terapeuta y relación con el clienteAriel Gajardo100% (1)
- 158 - Krumm Heller Tratado de Quirologa Medica PDFDocument89 pagini158 - Krumm Heller Tratado de Quirologa Medica PDFGonzalo IvanÎncă nu există evaluări
- La Medicina Tradicional y La Medicina Moderna en CuscoDocument55 paginiLa Medicina Tradicional y La Medicina Moderna en CuscoRodrigo David Lopez FernandezÎncă nu există evaluări
- Programación lógica inductiva UNICENDocument25 paginiProgramación lógica inductiva UNICENmariaÎncă nu există evaluări
- Cuestionario Sobre Paes.Document7 paginiCuestionario Sobre Paes.Enrique PaniaguaÎncă nu există evaluări
- Hipótesis EstadísticaDocument12 paginiHipótesis EstadísticaGiulianno Tarrillo UriarteÎncă nu există evaluări
- Salida Optativa (Humanidades y Lenguas Modernas)Document26 paginiSalida Optativa (Humanidades y Lenguas Modernas)Benjamin GuzmanÎncă nu există evaluări
- Taller 1, EstadisticaDocument22 paginiTaller 1, EstadisticaAndresito Qbds LsmsÎncă nu există evaluări
- Evaluación Lenguaje y Comunicación 6° BásicoDocument16 paginiEvaluación Lenguaje y Comunicación 6° BásicoClaudia Pino TorresÎncă nu există evaluări
- Ejercicio 1 ExamenDocument14 paginiEjercicio 1 ExamenJulia SolisÎncă nu există evaluări
- Estimación e Intervalos de ConfianzaDocument23 paginiEstimación e Intervalos de ConfianzaleidyÎncă nu există evaluări
- 2do Examen Practico Eco-21 IIDocument6 pagini2do Examen Practico Eco-21 IIRONALD RUBEN TTITO MAMANIÎncă nu există evaluări
- Ejercicios 01 de Repaso de Reglas de Inferencia, Proposiciones Categóricas Típicas y Silogismos Categóricos TípicosDocument3 paginiEjercicios 01 de Repaso de Reglas de Inferencia, Proposiciones Categóricas Típicas y Silogismos Categóricos TípicosFloralicia Chacón CalzadillaÎncă nu există evaluări
- Introduccion A La Logica 2Document394 paginiIntroduccion A La Logica 210812454100% (1)
- Validacion de ArgumentosDocument14 paginiValidacion de ArgumentosCarlos MoraÎncă nu există evaluări
- 4° Medio Guía InferenciaDocument6 pagini4° Medio Guía InferenciaMatias Ismael Hernandez GonzalezÎncă nu există evaluări
- Erik Larson - "Los Avances Actuales No Nos Acercan Más A Tener Una Inteligencia Artificial Similar A La Humana"Document10 paginiErik Larson - "Los Avances Actuales No Nos Acercan Más A Tener Una Inteligencia Artificial Similar A La Humana"Ser PaÎncă nu există evaluări
- BUAP Guia PRE-Aptitud AcademicaDocument67 paginiBUAP Guia PRE-Aptitud AcademicaKarenNogueda100% (1)
- IC1 - Sistemas de Inferencia Difusa - 2 - RevisadoDocument28 paginiIC1 - Sistemas de Inferencia Difusa - 2 - RevisadoJake Javier Alvarez VeraÎncă nu există evaluări
- Lógica-DefinicionesDocument98 paginiLógica-DefinicionesEduardo C.Încă nu există evaluări
- Krig IngDocument9 paginiKrig IngFranz Gustavo Vargas MamaniÎncă nu există evaluări
- Inferencia LógicaDocument38 paginiInferencia LógicaMarco Antonio Aguirre LamÎncă nu există evaluări
- Sesión 12Document31 paginiSesión 12KeshuxÎncă nu există evaluări
- Sesión #04Document32 paginiSesión #04Patrick Jara cruzadoÎncă nu există evaluări
- Trabajo de Logica JuridicaDocument9 paginiTrabajo de Logica JuridicaERnesto Vlb100% (1)
- Introduccion A La Logica - Irving Copi - Ultima EdicionDocument76 paginiIntroduccion A La Logica - Irving Copi - Ultima EdicionMjguerreroc100% (2)
- Clases Unidad 2 Estimación Por Intervalos de ConfianzaDocument56 paginiClases Unidad 2 Estimación Por Intervalos de ConfianzaCrispin Diaz RiveraÎncă nu există evaluări
- UntitledDocument132 paginiUntitledMartín CEÎncă nu există evaluări
- Practica 20Document17 paginiPractica 20IRENEÎncă nu există evaluări
- Teoria de La OrganizacionDocument66 paginiTeoria de La OrganizacionDaniel Alejandro AlzateÎncă nu există evaluări
- Regresión LinealDocument4 paginiRegresión Linealjose juan torresÎncă nu există evaluări
- Actividad 4Document2 paginiActividad 4Gadiel HernándezÎncă nu există evaluări
- Clase Semana 6Document14 paginiClase Semana 6Gabriel Chara HuamanÎncă nu există evaluări