S-ar putea să vă placă și
- Apprendre PythonDocument10 paginiApprendre Pythonnpoirier2Încă nu există evaluări
- Tutorial de CrackingDocument53 paginiTutorial de Crackingkantymada100% (2)
- 9 Prompts ChatGPT Pour Apprentis CodeursDocument3 pagini9 Prompts ChatGPT Pour Apprentis CodeursSebastien LartigueÎncă nu există evaluări
- Les Bases Du BillardDocument165 paginiLes Bases Du BillardYvan Rodrigue MINLO MinloÎncă nu există evaluări
- Un Site Dynamique Avec PHP !: Partie 1: Les Bases de PHPDocument336 paginiUn Site Dynamique Avec PHP !: Partie 1: Les Bases de PHPlouamangaÎncă nu există evaluări
- Guide D'utilisation de REAPER v4.25Document441 paginiGuide D'utilisation de REAPER v4.25Anonymous upwK1TLts83% (6)
- Trouver Un Mot de Passe Avec La Bruteforce PDFDocument8 paginiTrouver Un Mot de Passe Avec La Bruteforce PDFreserraqiqoÎncă nu există evaluări
- RegexpDocument21 paginiRegexprvg_007Încă nu există evaluări
- Guide Formation Starter ProgrammationDocument32 paginiGuide Formation Starter ProgrammationPaul GuermonprezÎncă nu există evaluări
- Tutoriel Pour Maîtriser Les Expressions Régulières (Regex)Document20 paginiTutoriel Pour Maîtriser Les Expressions Régulières (Regex)Bisimwa Mugisho Pacifique100% (1)
- Exercices Python3Document49 paginiExercices Python3Devin Ramos100% (1)
- Exercices Python3Document49 paginiExercices Python3Devin Ramos100% (1)
- Tutorial de CrackingDocument53 paginiTutorial de CrackingConstant KefraneÎncă nu există evaluări
- (TUTO) VPN Server - Tutoriels - NAS-Forum PDFDocument18 pagini(TUTO) VPN Server - Tutoriels - NAS-Forum PDFAmari MalikÎncă nu există evaluări
- PHPDocument60 paginiPHPHarouna CoulibalyÎncă nu există evaluări
- Beggin Maneskin Partitura Educação Musical Jose GalvaoDocument1 paginăBeggin Maneskin Partitura Educação Musical Jose GalvaoJosé GalvãoÎncă nu există evaluări
- Cours PHPDocument10 paginiCours PHPJohn StanÎncă nu există evaluări
- Apprendre Haskell Vous Fera Le Plus Grand BienDocument210 paginiApprendre Haskell Vous Fera Le Plus Grand BienPatateAdelineÎncă nu există evaluări
- GuideREAPERv3ch1 17Document360 paginiGuideREAPERv3ch1 17revilo2Încă nu există evaluări
- MODULE Re NumpyDocument41 paginiMODULE Re Numpysanatravail1990Încă nu există evaluări
- cakePHP BookDocument42 paginicakePHP BookcomanavÎncă nu există evaluări
- Lumadis - Be Regex Tuto Pcre PDFDocument29 paginiLumadis - Be Regex Tuto Pcre PDFYespapaSavsabienÎncă nu există evaluări
- Apprendre - Html.pour - Les.zeros NaWraS - EbookDocument0 paginiApprendre - Html.pour - Les.zeros NaWraS - Ebookbassir2010Încă nu există evaluări
- Openclassrooms - Com Courses Concevez-Votre-Site-Web-Avec PDFDocument5 paginiOpenclassrooms - Com Courses Concevez-Votre-Site-Web-Avec PDFYespapaSavsabienÎncă nu există evaluări
- PHP CoursDocument5 paginiPHP CoursWan TheoÎncă nu există evaluări
- Tutoriel - (GeSHi) Colorer Son CodeDocument11 paginiTutoriel - (GeSHi) Colorer Son CodeJean marc KonanÎncă nu există evaluări
- Cours JAVA Script PDFDocument63 paginiCours JAVA Script PDFTHE SINANÎncă nu există evaluări
- Une Introduction À H2O Avec R - R-BlogueursDocument9 paginiUne Introduction À H2O Avec R - R-Blogueursméthode RMarcÎncă nu există evaluări
- 4découvrez Le Vocabulaire de Python - Démarrez Votre Projet Avec Python - OpenClassroomsDocument6 pagini4découvrez Le Vocabulaire de Python - Démarrez Votre Projet Avec Python - OpenClassroomsSohaib AdjaoutÎncă nu există evaluări
- Cour Initiation-PhpDocument57 paginiCour Initiation-PhpBlh OussamaÎncă nu există evaluări
- Chargement D'un Firmware Sous IDA PRO IIDocument10 paginiChargement D'un Firmware Sous IDA PRO IIIliaÎncă nu există evaluări
- XHTML2Document237 paginiXHTML2Ikbel BakloutiÎncă nu există evaluări
- Apprendre PHPDocument182 paginiApprendre PHPhibaÎncă nu există evaluări
- Cracking de PasswordDocument4 paginiCracking de PasswordLaine MoiseÎncă nu există evaluări
- Tutoriel - Tout Sur Le Javascript !Document148 paginiTutoriel - Tout Sur Le Javascript !Serge OngoloÎncă nu există evaluări
- Guide D Utilisation de REAPER v3 ch1 11Document214 paginiGuide D Utilisation de REAPER v3 ch1 11Gilles MalatrayÎncă nu există evaluări
- Open AI TutorialDocument5 paginiOpen AI Tutorialch kbsÎncă nu există evaluări
- Conjugaison Imparfait ScenarioDocument5 paginiConjugaison Imparfait ScenarioSamuel MolayÎncă nu există evaluări
- Les Espaces de Noms en PHPDocument12 paginiLes Espaces de Noms en PHPferid_tlili_2013Încă nu există evaluări
- Guide D'utilisation de REAPER v3.67 Ch1 À 17Document360 paginiGuide D'utilisation de REAPER v3.67 Ch1 À 17ludÎncă nu există evaluări
- Mise en Place de Notre Environnement de Travail: Le Travail en Local Et Le Travail en ProductionDocument27 paginiMise en Place de Notre Environnement de Travail: Le Travail en Local Et Le Travail en ProductionOlivierÎncă nu există evaluări
- Pyth 4Document2 paginiPyth 4Oussama Lahlou Alias SoupinetÎncă nu există evaluări
- 3 WebdynDocument42 pagini3 WebdynAbdelwahid Ben AmeurÎncă nu există evaluări
- Wpcookbook ExcerptDocument38 paginiWpcookbook Excerptbintou emicivÎncă nu există evaluări
- Les Expressions Régulières - Le Super Rechercher-Remplacer - Data Sciences SocialesDocument16 paginiLes Expressions Régulières - Le Super Rechercher-Remplacer - Data Sciences Socialesméthode RMarcÎncă nu există evaluări
- Partie 5-CoursDocument6 paginiPartie 5-CoursLeila BaÎncă nu există evaluări
- Séance 3Document13 paginiSéance 3mahadÎncă nu există evaluări
- Cours ProgFonct ProgLog ZekengDocument64 paginiCours ProgFonct ProgLog ZekengTchonbe Albert TchonbeÎncă nu există evaluări
- Hackers Mag 32Document32 paginiHackers Mag 32NadhirSouissi100% (1)
- Analyse de La Décompression Du Maincode Type C MajDocument20 paginiAnalyse de La Décompression Du Maincode Type C MajIliaÎncă nu există evaluări
- Debuter PerlDocument10 paginiDebuter PerlFred SobonÎncă nu există evaluări
- 3 Bibliothèques Python Low - CodeDocument7 pagini3 Bibliothèques Python Low - CodeAristide GoutchebamiÎncă nu există evaluări
- 8structurez Votre Programme en Utilisant Les Fonctions - Démarrez Votre Projet Avec Python - OpenClassroomsDocument3 pagini8structurez Votre Programme en Utilisant Les Fonctions - Démarrez Votre Projet Avec Python - OpenClassroomsSohaib AdjaoutÎncă nu există evaluări
- Exo 1Document4 paginiExo 1Hssina AbaÎncă nu există evaluări
- Cours Laravel 9 - La LocalisationDocument8 paginiCours Laravel 9 - La LocalisationKHALID EDAIGÎncă nu există evaluări
- Utiliser ScrapeBox Pour Avoir Plusieurs Mots Clés Pour Vos RéférencementsDocument5 paginiUtiliser ScrapeBox Pour Avoir Plusieurs Mots Clés Pour Vos RéférencementsLudovic BarthelemyÎncă nu există evaluări
- TP1 PHPDocument7 paginiTP1 PHPTayssir SahliÎncă nu există evaluări
- Tutoriel Pour Maîtriser Les Expressions Régulières - Regex PDFDocument7 paginiTutoriel Pour Maîtriser Les Expressions Régulières - Regex PDFYespapaSavsabienÎncă nu există evaluări
- Parser Un Format SimpleDocument17 paginiParser Un Format SimpleMouhamed Rassoul GueyeÎncă nu există evaluări
- CrackDocument7 paginiCrackAnonymous OLKgVHÎncă nu există evaluări
- Les Bases de C-SharpDocument17 paginiLes Bases de C-SharpdeedgiÎncă nu există evaluări
- Programmer en C | Pas à Pas: Le guide simple pour les débutantsDe la EverandProgrammer en C | Pas à Pas: Le guide simple pour les débutantsÎncă nu există evaluări
- Guide d'utilisation des logiciels de reconnaissance vocale :De la EverandGuide d'utilisation des logiciels de reconnaissance vocale :Încă nu există evaluări
- Python pour Débutants : Guide Complet pour Apprendre la Programmation Pas à PasDe la EverandPython pour Débutants : Guide Complet pour Apprendre la Programmation Pas à PasÎncă nu există evaluări
- STPDocument28 paginiSTPWidad El OuazzaniÎncă nu există evaluări
- Q in QDocument4 paginiQ in QMi NgolamamyÎncă nu există evaluări
- ACL CiscoDocument16 paginiACL CisconamalkaÎncă nu există evaluări
- Adsl PDFDocument3 paginiAdsl PDFAmari MalikÎncă nu există evaluări
- SPAI C1 ArchiC S 6p PDFDocument28 paginiSPAI C1 ArchiC S 6p PDFAmari MalikÎncă nu există evaluări
- L'Internet Rapide Et Permanent - La Réalisation D'un Proxy Transparent PDFDocument11 paginiL'Internet Rapide Et Permanent - La Réalisation D'un Proxy Transparent PDFAmari MalikÎncă nu există evaluări
- Cote Labo GSBEonDocument68 paginiCote Labo GSBEonFteiti MondherÎncă nu există evaluări
- Entête IPv6 - FRAMEIP PDFDocument13 paginiEntête IPv6 - FRAMEIP PDFAmari MalikÎncă nu există evaluări
- Ospf Migration PDFDocument12 paginiOspf Migration PDFAmari MalikÎncă nu există evaluări
- Autoconf Ipv6 PDFDocument14 paginiAutoconf Ipv6 PDFAmari MalikÎncă nu există evaluări
- Architecture L2TP - Layer 2 Tunneling Protocol - FRAMEIP PDFDocument23 paginiArchitecture L2TP - Layer 2 Tunneling Protocol - FRAMEIP PDFAmari MalikÎncă nu există evaluări
- Commandes CiscoDocument11 paginiCommandes CiscoYoussef YLÎncă nu există evaluări
- FastPHP PDFDocument103 paginiFastPHP PDFAmari MalikÎncă nu există evaluări
- Bilgin RTBDocument106 paginiBilgin RTBidrissÎncă nu există evaluări
- Excel 2007 - 2010 - 2013 - Exercice Sur Le Tableau Croisé Dynamique PDFDocument9 paginiExcel 2007 - 2010 - 2013 - Exercice Sur Le Tableau Croisé Dynamique PDFAmari MalikÎncă nu există evaluări
- PHP Seance1Document11 paginiPHP Seance1Amari MalikÎncă nu există evaluări
- Valorisation de La Plante D'alfa Article 02.03.2016Document7 paginiValorisation de La Plante D'alfa Article 02.03.2016Err SaraÎncă nu există evaluări
- Blanche NeigeDocument2 paginiBlanche NeigeSamaÎncă nu există evaluări
- ECE 23 PC 02 244860fd80Document2 paginiECE 23 PC 02 244860fd80Mathilde BosquierÎncă nu există evaluări
- Récap Module Sécurité Réseaux 10-13 Ccna2Document3 paginiRécap Module Sécurité Réseaux 10-13 Ccna2Bouazza Mohammed RedaÎncă nu există evaluări
- Cangur 2019 SolucionsDocument8 paginiCangur 2019 SolucionsRida Eddellah MohamedÎncă nu există evaluări
- Comment Convertir PDF en Jpeg en LigneDocument2 paginiComment Convertir PDF en Jpeg en LigneLaurenÎncă nu există evaluări
- Chaussée 122345Document5 paginiChaussée 122345ZeroualÎncă nu există evaluări
- Voip PDFDocument74 paginiVoip PDFhocineÎncă nu există evaluări
- Utiliser Les Repères de Mise en Page Et DDocument4 paginiUtiliser Les Repères de Mise en Page Et DYoussef ZelmadÎncă nu există evaluări
- RCS - DVDDocument117 paginiRCS - DVDrobertopinto487Încă nu există evaluări
- Blue in Green - Tenor Sax 2Document2 paginiBlue in Green - Tenor Sax 2Tim LinÎncă nu există evaluări
- Tutoriel PfsenseDocument11 paginiTutoriel Pfsenseapi-373592080Încă nu există evaluări
- Cuisine Traditionnelle FrancaiseDocument2 paginiCuisine Traditionnelle FrancaiseCorina TeteleaÎncă nu există evaluări
- 2.1.6 L Épi Et Son Musoir L ÉpiDocument50 pagini2.1.6 L Épi Et Son Musoir L ÉpiFeki MahdiÎncă nu există evaluări
- Les Vacances Du Petit Nicolas - 05 - La GymDocument3 paginiLes Vacances Du Petit Nicolas - 05 - La GymSamaneh AbdiÎncă nu există evaluări
- Flyer 40039228Document2 paginiFlyer 40039228goithiuuuhhhtÎncă nu există evaluări
- Creer Des DossierDocument5 paginiCreer Des DossierSabrina YousfiÎncă nu există evaluări
- Zoom Hebdo 1422 - 344Document10 paginiZoom Hebdo 1422 - 344Morgane patrick EffoutameÎncă nu există evaluări
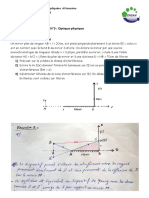
- Corr TD 3 - Optique PhysiqueDocument7 paginiCorr TD 3 - Optique PhysiqueAbdellader NmiraÎncă nu există evaluări
- Fiche Présentation Dessine Moi Un Kwatyor PDFDocument3 paginiFiche Présentation Dessine Moi Un Kwatyor PDFatelier d'écritureÎncă nu există evaluări
- Sport 111Document48 paginiSport 111final65100% (4)
- Recensement AbidjanDocument34 paginiRecensement AbidjanRhaumeo ProdsÎncă nu există evaluări
- TP4 DWM2 - 2019 - 2020Document5 paginiTP4 DWM2 - 2019 - 2020Tàs NîmeÎncă nu există evaluări
- Heat Waves - Glass Animals - Partitura Flauta - Educação Musical - José GalvãoDocument1 paginăHeat Waves - Glass Animals - Partitura Flauta - Educação Musical - José GalvãoJosé GalvãoÎncă nu există evaluări
- Free ADSLDocument1 paginăFree ADSLpippobaudo666Încă nu există evaluări
- Biscuit À La CuillèreDocument5 paginiBiscuit À La CuillèreTarak ZayaniÎncă nu există evaluări
- Poursuivre Croisade VF CompressedDocument1 paginăPoursuivre Croisade VF Compressedvalentin vantournhoudtÎncă nu există evaluări
- Dictionnaire Du Transport Et de La Logistique 3eme Edition Gestion Industrielle B00TEEB9WGDocument2 paginiDictionnaire Du Transport Et de La Logistique 3eme Edition Gestion Industrielle B00TEEB9WGKen Tien'sÎncă nu există evaluări