S-ar putea să vă placă și
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- NEET Compendium Physics Motion of System ParticlesDocument78 paginiNEET Compendium Physics Motion of System ParticlesRahul Bhimakari100% (1)
- Ornament & Crime 1.3.0 User ManualDocument49 paginiOrnament & Crime 1.3.0 User ManualGiona VintiÎncă nu există evaluări
- The Unified Theory of Physics: The Unified UniverseDocument62 paginiThe Unified Theory of Physics: The Unified Universedao einsnewt67% (3)
- Amm 2010 N3Document101 paginiAmm 2010 N31110004Încă nu există evaluări
- Regular Expressions Cheat SheetDocument2 paginiRegular Expressions Cheat Sheettibork1Încă nu există evaluări
- Transient Stability Analysis With PowerWorld SimulatorDocument32 paginiTransient Stability Analysis With PowerWorld SimulatorvitaxeÎncă nu există evaluări
- Test Bank For Quantitative Analysis For Management 12th EditionDocument12 paginiTest Bank For Quantitative Analysis For Management 12th EditionVathasil VasasiriÎncă nu există evaluări
- Basic Review CardDocument6 paginiBasic Review CardSheena LeavittÎncă nu există evaluări
- Functions and SequenceDocument13 paginiFunctions and SequenceVanshika WadhwaniÎncă nu există evaluări
- Business Mathematics: Quarter 1 - Module 3: Kinds of ProportionDocument25 paginiBusiness Mathematics: Quarter 1 - Module 3: Kinds of ProportionZia Belle Bedro - LuardoÎncă nu există evaluări
- PIAR ExampleDocument7 paginiPIAR ExampleScribdTranslationsÎncă nu există evaluări
- Experimental Design - Chapter 1 - Introduction and BasicsDocument83 paginiExperimental Design - Chapter 1 - Introduction and BasicsThuỳ Trang100% (1)
- Martin Caidin - The God MachineDocument134 paginiMartin Caidin - The God MachineLogan BlackstoneÎncă nu există evaluări
- SME QA Answering Directions General PDFDocument20 paginiSME QA Answering Directions General PDFSagan AlamÎncă nu există evaluări
- Dynamic and Structural Analysis: Foundation For A Pendulum MillDocument32 paginiDynamic and Structural Analysis: Foundation For A Pendulum MillMenna AhmedÎncă nu există evaluări
- Britannica Content EngineeringDocument6 paginiBritannica Content EngineeringMaksudur Rahman SumonÎncă nu există evaluări
- Net Iq Portion (Part-8)Document35 paginiNet Iq Portion (Part-8)Sana AftabÎncă nu există evaluări
- Algebraic Factorization and Remainder TheoremsDocument5 paginiAlgebraic Factorization and Remainder TheoremsNisheli Amani PereraÎncă nu există evaluări
- Physics CalaDocument7 paginiPhysics CalaMunazÎncă nu există evaluări
- Math N4 Syllabus BreakdownDocument23 paginiMath N4 Syllabus BreakdownButi MotsamaiÎncă nu există evaluări
- Effect of Attenuation and Distortion in Transmission LineDocument16 paginiEffect of Attenuation and Distortion in Transmission Lineமணி பிரபுÎncă nu există evaluări
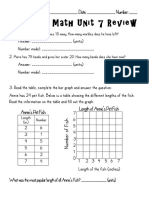
- Everyday Math Unit 7 ReviewDocument3 paginiEveryday Math Unit 7 ReviewReekhaÎncă nu există evaluări
- 5 Difference Between Hashmap and Hashset in Java With ExampleDocument6 pagini5 Difference Between Hashmap and Hashset in Java With ExampleJeya Shree Arunjunai RajÎncă nu există evaluări
- REVIEWDocument21 paginiREVIEWJulie Ann PahilagmagoÎncă nu există evaluări
- Final BlackjackDocument34 paginiFinal Blackjackapi-359332959Încă nu există evaluări
- MAFE208IU-L7 InterpolationDocument35 paginiMAFE208IU-L7 InterpolationThy VũÎncă nu există evaluări
- Conversion of Dates and Amount To Arabic Numerals in SSRS AX ReportsDocument5 paginiConversion of Dates and Amount To Arabic Numerals in SSRS AX ReportsDynamic Netsoft TechnologiesÎncă nu există evaluări
- Understanding Attribute Acceptance Sampling: Dan O'Leary Cba, Cqa, Cqe, Cre, SSBB, Cirm President Ombu Enterprises, LLCDocument72 paginiUnderstanding Attribute Acceptance Sampling: Dan O'Leary Cba, Cqa, Cqe, Cre, SSBB, Cirm President Ombu Enterprises, LLCDarren TanÎncă nu există evaluări
- 3021 - 07 Predetermined Time SystemsDocument37 pagini3021 - 07 Predetermined Time Systemssunilkjain6105100% (1)