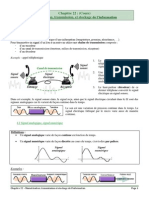
S-ar putea să vă placă și
- Fiche 8 - Le Materiel de SonorisationDocument3 paginiFiche 8 - Le Materiel de SonorisationPalmer Marc MercierÎncă nu există evaluări
- Guide de La Sonorisation PDFDocument84 paginiGuide de La Sonorisation PDFchinchay07100% (19)
- Guide Complet de La Sonorisation 2009 PDFDocument73 paginiGuide Complet de La Sonorisation 2009 PDFtinasupf100% (2)
- Traitement de Signal Acoustique (Cours Et Applications)Document52 paginiTraitement de Signal Acoustique (Cours Et Applications)Ahmed Rhif83% (6)
- Musique traditionnelle pour accordéon diatonique: Philippe BruneauDe la EverandMusique traditionnelle pour accordéon diatonique: Philippe BruneauÎncă nu există evaluări
- L'audionumérique - 3e Éd. Musique Et Informatique (Audio-Photo-Vidéo) - Curtis RoadsDocument688 paginiL'audionumérique - 3e Éd. Musique Et Informatique (Audio-Photo-Vidéo) - Curtis RoadsMichael Clark100% (3)
- Le Protocol MIDIDocument14 paginiLe Protocol MIDIjpcoteÎncă nu există evaluări
- Le Guide Du MixageDocument428 paginiLe Guide Du MixageLurys AndrianaivoÎncă nu există evaluări
- La Synthèse Sonore Son Hisoire, Ses PrincipesDocument48 paginiLa Synthèse Sonore Son Hisoire, Ses PrincipesBrice Deloose100% (7)
- Compression AudioDocument17 paginiCompression AudioDavidLomazziÎncă nu există evaluări
- SonorisationDocument13 paginiSonorisationdonÎncă nu există evaluări
- Memoire Mastering Lucas Desmottes Ists3 0611Document58 paginiMemoire Mastering Lucas Desmottes Ists3 0611don-lucioÎncă nu există evaluări
- 101 Recettes de La Cuisine de La ChasseDocument156 pagini101 Recettes de La Cuisine de La ChasseazaÎncă nu există evaluări
- Sae Mem 96 PDFDocument40 paginiSae Mem 96 PDFSAEBrusselsÎncă nu există evaluări
- 5-La Table de Mixage AnalogiqueDocument45 pagini5-La Table de Mixage AnalogiqueNadia HalouaniÎncă nu există evaluări
- SonorisationDocument19 paginiSonorisationtinasupfÎncă nu există evaluări
- Le MicrophoneDocument14 paginiLe MicrophonewiartÎncă nu există evaluări
- SonorisationDocument16 paginiSonorisationOrios AdklÎncă nu există evaluări
- Comment BIEN Comprendre L'enveloppe ADSR Peut Vous Aider en Production MusicaleDocument3 paginiComment BIEN Comprendre L'enveloppe ADSR Peut Vous Aider en Production MusicaleYann CostazÎncă nu există evaluări
- L'Équalisation - Les Bases À ConnaîtreDocument5 paginiL'Équalisation - Les Bases À ConnaîtrecabeaureyÎncă nu există evaluări
- Le Signal AudioDocument21 paginiLe Signal Audiosahliano100% (5)
- Prise de Son en StudioDocument53 paginiPrise de Son en StudioNadia HalouaniÎncă nu există evaluări
- Le Son MulticanalDocument445 paginiLe Son Multicanalgakeisha100% (1)
- Compression MultibandeDocument3 paginiCompression MultibandeBrice DelooseÎncă nu există evaluări
- Audio NumeriqueDocument49 paginiAudio Numeriquebobrac100% (4)
- Initiation A La Synthese SonoreDocument44 paginiInitiation A La Synthese Sonoreapi-3839180Încă nu există evaluări
- Cours de Traitement Des Signaux AudioDocument58 paginiCours de Traitement Des Signaux Audioisaac2008100% (5)
- Les Microphones CompletDocument17 paginiLes Microphones CompletMehdi WalkerÎncă nu există evaluări
- Manuel Flstudio FRDocument93 paginiManuel Flstudio FRValentin GossmannÎncă nu există evaluări
- Tutoriel Mastering Version A5 v1.0 PDFDocument62 paginiTutoriel Mastering Version A5 v1.0 PDFdjelvrÎncă nu există evaluări
- Les Bases Du Mastering Pour..Document10 paginiLes Bases Du Mastering Pour..Eric MarquisÎncă nu există evaluări
- Terminer Un Mixage en Vue Masterinf Version LongDocument6 paginiTerminer Un Mixage en Vue Masterinf Version Longrobertlangdon99Încă nu există evaluări
- Programme de Cours StudioDocument2 paginiProgramme de Cours StudioMercier Palmer MarcÎncă nu există evaluări
- Le Son TPEDocument3 paginiLe Son TPEP_f_Fall_4927100% (1)
- Petite Tortue AmigurumiDocument3 paginiPetite Tortue AmigurumiLe Pavoux100% (1)
- Feuilletage - 3259 Le Livre Des Techniques de SonDocument30 paginiFeuilletage - 3259 Le Livre Des Techniques de SonSidy Semba DagnogoÎncă nu există evaluări
- 05 Egalisation PDFDocument10 pagini05 Egalisation PDFRomain MantoÎncă nu există evaluări
- Cours Son PDFDocument7 paginiCours Son PDFWilliam Marilleau100% (1)
- Les Appareils de Traitement de SonDocument10 paginiLes Appareils de Traitement de SonkarimÎncă nu există evaluări
- BENOIT Daniel Les Microphones 1997Document25 paginiBENOIT Daniel Les Microphones 1997ManesÎncă nu există evaluări
- ABCsonorisation SIDocument72 paginiABCsonorisation SIbouwazraÎncă nu există evaluări
- RTA Citroen E-Mehari NoticeDocument16 paginiRTA Citroen E-Mehari NoticeStukineÎncă nu există evaluări
- La Prise de Son 2020Document3 paginiLa Prise de Son 2020Planemo100% (1)
- Serum ManualDocument76 paginiSerum ManualLéo GallacioÎncă nu există evaluări
- Cablage XLRDocument5 paginiCablage XLRbipbipchris100% (3)
- La Compression Du Signal Audio (Ziggy's Sonorisation)Document5 paginiLa Compression Du Signal Audio (Ziggy's Sonorisation)villaandreÎncă nu există evaluări
- C22 COURS Numerisation Transmission Stockage InformationDocument10 paginiC22 COURS Numerisation Transmission Stockage Informationmatmatijamel100% (1)
- Le Placement Des Micros Pour Une Prise de Son StereoDocument9 paginiLe Placement Des Micros Pour Une Prise de Son Stereoremusik2Încă nu există evaluări
- c3 Vocabulaire Sport Exploits SportifsDocument16 paginic3 Vocabulaire Sport Exploits SportifsNadir Aïder100% (1)
- Cours Fondement de Réseau: SonDocument27 paginiCours Fondement de Réseau: SonSaf Bes100% (1)
- 1 - Définitions Et Grandeurs AcoustiqueDocument16 pagini1 - Définitions Et Grandeurs AcoustiqueVictor SaurelÎncă nu există evaluări
- Portfolio Full Basstards Espagne - Sound and Production Engineering PDFDocument8 paginiPortfolio Full Basstards Espagne - Sound and Production Engineering PDFBezetaFullBasstardsÎncă nu există evaluări
- 2-Les ConnecteursDocument23 pagini2-Les ConnecteursNadia HalouaniÎncă nu există evaluări
- Ingénieur Du Son Fiche RomeDocument4 paginiIngénieur Du Son Fiche RomeMaxence LetempsÎncă nu există evaluări
- Cours de SonorisationDocument74 paginiCours de SonorisationSam MenardÎncă nu există evaluări
- Plan Mémoire de Master 1Document2 paginiPlan Mémoire de Master 1Rhaumeo ProdsÎncă nu există evaluări
- TDR Sonorisation Et Lumières Du SiteDocument4 paginiTDR Sonorisation Et Lumières Du SiteAnto RaolosonÎncă nu există evaluări
- Formation Aux Techniques Audionumériques en Homestudio Par Tutoriel Vidéo - Apprendre Les Techniques AudionumériquesDocument2 paginiFormation Aux Techniques Audionumériques en Homestudio Par Tutoriel Vidéo - Apprendre Les Techniques AudionumériquessedearrÎncă nu există evaluări
- Ingenieur SonDocument2 paginiIngenieur SonMarro Jacques Daniel guiagnini koukoÎncă nu există evaluări
- Calrec Audio Product Guide, in FrenchDocument12 paginiCalrec Audio Product Guide, in FrenchCalrecCommunityÎncă nu există evaluări
- Chef Operateur de Prise de Son TV - 4Document4 paginiChef Operateur de Prise de Son TV - 4zaydÎncă nu există evaluări
- DissertDocument4 paginiDissertvelqceÎncă nu există evaluări
- La Bergère Et Le Ramoneur (Andersen-Soldi)Document4 paginiLa Bergère Et Le Ramoneur (Andersen-Soldi)JeanJames KöningÎncă nu există evaluări
- Unjardinierbruxelles BrochureDocument12 paginiUnjardinierbruxelles BrochureUn jardinier BruxellesÎncă nu există evaluări
- 0 0 Mots Croises Rentree Des ClassesDocument1 pagină0 0 Mots Croises Rentree Des Classesdiana panteaÎncă nu există evaluări
- Projet SesDocument9 paginiProjet SesMat WlitugÎncă nu există evaluări
- Histoire Instruments Moyen-AgeDocument2 paginiHistoire Instruments Moyen-AgeNicolas MartelloÎncă nu există evaluări
- Yamaha - Guide D'achat Du Piano 2018Document17 paginiYamaha - Guide D'achat Du Piano 2018konepartners4479Încă nu există evaluări
- Baudino 8 Studi Legati PreviewDocument2 paginiBaudino 8 Studi Legati PreviewRoccoBrÎncă nu există evaluări
- 2019 11 v2Document24 pagini2019 11 v2JemÎncă nu există evaluări
- Discours IndirectDocument2 paginiDiscours IndirectBarbu IuliaÎncă nu există evaluări
- Rapport de Stage Dans Une MediathequeDocument7 paginiRapport de Stage Dans Une MediathequeFlori31Încă nu există evaluări
- 1H Sans M'arrêter - Jogging InternationalDocument2 pagini1H Sans M'arrêter - Jogging InternationalSerraÎncă nu există evaluări
- Monitor ProDocument25 paginiMonitor ProJamel CharefÎncă nu există evaluări
- Les Echelles de PlansDocument6 paginiLes Echelles de PlansdantzerprofÎncă nu există evaluări
- Record Can PDF MinDocument8 paginiRecord Can PDF MinLahad DiaÎncă nu există evaluări
- Paganini Sonatina in CDocument2 paginiPaganini Sonatina in Cyjk123456Încă nu există evaluări
- Conjcm 2Document15 paginiConjcm 2kingnachiÎncă nu există evaluări
- Tableaux Suivi Trame 2014Document10 paginiTableaux Suivi Trame 2014kwameÎncă nu există evaluări
- Du Rhum Des Femmes Chords by Soldat Louis @Document1 paginăDu Rhum Des Femmes Chords by Soldat Louis @Bottox ToxiicÎncă nu există evaluări
- La Musique BaroqueDocument4 paginiLa Musique Baroqueelise frouardÎncă nu există evaluări
- Casi Humanos - Dvicio PDFDocument6 paginiCasi Humanos - Dvicio PDFSoy RockstarÎncă nu există evaluări
- Diction ArticulationDocument2 paginiDiction ArticulationByntou TraoréÎncă nu există evaluări
- Dialogues 4Document116 paginiDialogues 4ibsfrÎncă nu există evaluări
- Blues For Big Scotia - Full ScoreDocument3 paginiBlues For Big Scotia - Full Score김상준Încă nu există evaluări
- AikidoDocument41 paginiAikidoKokona CocoÎncă nu există evaluări
- L'hôtelDocument4 paginiL'hôtelAida HejazianÎncă nu există evaluări