S-ar putea să vă placă și
- Heart Advicefor Practicing Dharmain Daily LifeDocument9 paginiHeart Advicefor Practicing Dharmain Daily Lifevivekgandhi7k7Încă nu există evaluări
- Samadhi Raja Sutra GampopaDocument7 paginiSamadhi Raja Sutra Gampopavivekgandhi7k7Încă nu există evaluări
- Translation of The Dattatreyayogasastra PDFDocument9 paginiTranslation of The Dattatreyayogasastra PDFLazy DogÎncă nu există evaluări
- Unravelling Mantra's Meaning in The Heart of Wisdom SūtraDocument9 paginiUnravelling Mantra's Meaning in The Heart of Wisdom SūtratabuÎncă nu există evaluări
- KalangiDocument35 paginiKalangivivekgandhi7k7100% (1)
- Mindfulness of Breathing: Pa-Auk Tawya SayadawDocument18 paginiMindfulness of Breathing: Pa-Auk Tawya Sayadawvivekgandhi7k7100% (1)
- Geshe Tenzin Namdak SessionsDocument6 paginiGeshe Tenzin Namdak Sessionsvivekgandhi7k7Încă nu există evaluări
- Dharma Benefits of Vajra Cutter SutraDocument2 paginiDharma Benefits of Vajra Cutter Sutrasamanera2Încă nu există evaluări
- Introducing Mahamudra - Mahamudra Teachings BookDocument21 paginiIntroducing Mahamudra - Mahamudra Teachings BookImran AhmadÎncă nu există evaluări
- Great CompletenessDocument1 paginăGreat Completenessvivekgandhi7k7Încă nu există evaluări
- IP Addressing and Subnetting For New Users: TranslationsDocument18 paginiIP Addressing and Subnetting For New Users: Translationsvivekgandhi7k7100% (1)
- Samatha Based Vipassana Meditation: Moung Htaung Myay Zinn Tawya SayadawDocument26 paginiSamatha Based Vipassana Meditation: Moung Htaung Myay Zinn Tawya Sayadawvivekgandhi7k7Încă nu există evaluări
- Samatha: BuddhismDocument13 paginiSamatha: Buddhismvivekgandhi7k7100% (1)
- Tenth Day Padma SambhavaDocument3 paginiTenth Day Padma Sambhavavivekgandhi7k7Încă nu există evaluări
- Parasurama Kalpa SutraDocument12 paginiParasurama Kalpa Sutravivekgandhi7k7100% (1)
- Inter-State Labour Legal Governance Project ProposalDocument1 paginăInter-State Labour Legal Governance Project Proposalvivekgandhi7k7Încă nu există evaluări
- Kabir QuotesDocument1 paginăKabir Quotesvivekgandhi7k7Încă nu există evaluări
- Hindu Mantras and Sacred Texts WebsiteDocument1 paginăHindu Mantras and Sacred Texts Websitevivekgandhi7k7Încă nu există evaluări
- It Is Not The Subject or Object That Is The Cause of Suffering But The Mind, The Unconscious Which Is Full of Hatred and GreedDocument2 paginiIt Is Not The Subject or Object That Is The Cause of Suffering But The Mind, The Unconscious Which Is Full of Hatred and Greedvivekgandhi7k7Încă nu există evaluări
- Osho On Depression: Try To Become Aware When You Are SufferingDocument17 paginiOsho On Depression: Try To Become Aware When You Are Sufferingvivekgandhi7k7Încă nu există evaluări
- Gurdjieff UnveiledDocument158 paginiGurdjieff UnveiledPerlim Pim Pom100% (1)
- Sadhana VajrayoginiDocument44 paginiSadhana VajrayoginiMan Sang Yan100% (1)
- From Attention To Self RememberingDocument5 paginiFrom Attention To Self Rememberingvivekgandhi7k7Încă nu există evaluări
- Vamadeva Article 1216Document4 paginiVamadeva Article 1216vivekgandhi7k7Încă nu există evaluări
- CCNA Networking SyllabusDocument9 paginiCCNA Networking Syllabusvivekgandhi7k7Încă nu există evaluări
- Publisher's Desk: A Hindu View of MindfulnessDocument2 paginiPublisher's Desk: A Hindu View of Mindfulnessvivekgandhi7k7Încă nu există evaluări
- The Question of Life and DeathDocument6 paginiThe Question of Life and DeathharoldmirandaÎncă nu există evaluări
- Questions Networking CcnaDocument4 paginiQuestions Networking Ccnavivekgandhi7k7Încă nu există evaluări
- Addressing SRH Needs of MigrantsDocument32 paginiAddressing SRH Needs of Migrantsvivekgandhi7k7Încă nu există evaluări
- Heart SutraDocument3 paginiHeart SutraloshudeÎncă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- A Black and Red TriangleDocument3 paginiA Black and Red TriangleJunn Ree MontillaÎncă nu există evaluări
- Cost Management Periodic Average Costing Setup and Process Flow PDFDocument58 paginiCost Management Periodic Average Costing Setup and Process Flow PDFSmart Diamond0% (2)
- SQL Queries Select StatementDocument5 paginiSQL Queries Select StatementmkumarshahiÎncă nu există evaluări
- Daa MCQ SetDocument20 paginiDaa MCQ SetVamsi KrishnaÎncă nu există evaluări
- Agam Singh Resume 2Document3 paginiAgam Singh Resume 2AgampaviÎncă nu există evaluări
- Veritas™ Cluster Server by Symantec: Reduce Application DowntimeDocument5 paginiVeritas™ Cluster Server by Symantec: Reduce Application DowntimekarthickmsitÎncă nu există evaluări
- Case Processing SummaryDocument2 paginiCase Processing SummarySiti Fatimah KaharÎncă nu există evaluări
- Vectoring Compatibility CISS 2012 (Web)Document6 paginiVectoring Compatibility CISS 2012 (Web)markÎncă nu există evaluări
- BLM 8-2 Chapter 8 Get ReadDocument3 paginiBLM 8-2 Chapter 8 Get Readapi-349184429Încă nu există evaluări
- Photoshop Normal Map FilterDocument7 paginiPhotoshop Normal Map FilterDarek CzarneckiÎncă nu există evaluări
- IBM DS3200 System Storage PDFDocument144 paginiIBM DS3200 System Storage PDFelbaronrojo2008Încă nu există evaluări
- Or QB AutoDocument17 paginiOr QB AutorrathoreÎncă nu există evaluări
- Final Report of Antenna ProjectDocument40 paginiFinal Report of Antenna ProjectdododorerereÎncă nu există evaluări
- Studocu Is Not Sponsored or Endorsed by Any College or UniversityDocument51 paginiStudocu Is Not Sponsored or Endorsed by Any College or UniversityDK SHARMAÎncă nu există evaluări
- Vehicle Insurance Management SystemDocument92 paginiVehicle Insurance Management Systemeyob.abate.legesse0% (1)
- Resume Faisal AmanDocument5 paginiResume Faisal AmanFaisal AmanÎncă nu există evaluări
- Bhagavad GitaDocument27 paginiBhagavad GitaKarthik ChandrasekaranÎncă nu există evaluări
- Design Calculation Roof ShadeDocument26 paginiDesign Calculation Roof ShadeAbuAhmedQuazi100% (1)
- Document For AgileDocument5 paginiDocument For Agilemohan1221itÎncă nu există evaluări
- CrashReport 8d5ad934 67a9 4d2d 961d B8b7b5da7ceaDocument2 paginiCrashReport 8d5ad934 67a9 4d2d 961d B8b7b5da7ceaM Default NameÎncă nu există evaluări
- Manual WECON PLC EDITOR PDFDocument375 paginiManual WECON PLC EDITOR PDFChristian JacoboÎncă nu există evaluări
- Introduction To Artificial IntelligenceDocument26 paginiIntroduction To Artificial IntelligenceAvdhesh GuptaÎncă nu există evaluări
- What Is A GC Buffer Busy WaitDocument2 paginiWhat Is A GC Buffer Busy Waitmrstranger1981Încă nu există evaluări
- Shortcodes Ultimate CheatsheetDocument21 paginiShortcodes Ultimate CheatsheetBleza XerofÎncă nu există evaluări
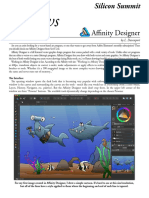
- Affinity DesignerDocument4 paginiAffinity DesignerManu7750% (2)
- Artificial Intelligence A Z Learn How To Build An AI 2Document33 paginiArtificial Intelligence A Z Learn How To Build An AI 2Suresh Naidu100% (1)
- Math Unit 1 Final StudentDocument10 paginiMath Unit 1 Final Studentapi-266063796Încă nu există evaluări
- Telecom GlossaryDocument206 paginiTelecom GlossaryAshish Mohapatra0% (1)
- Group Policy Health Check (GPOHC)Document2 paginiGroup Policy Health Check (GPOHC)Guido OliveiraÎncă nu există evaluări
- Multivariate Analysis-MRDocument8 paginiMultivariate Analysis-MRhemalichawlaÎncă nu există evaluări