S-ar putea să vă placă și
- MVA Techniques for Multivariate AnalysisDocument11 paginiMVA Techniques for Multivariate AnalysisDaya UnnikrishnanÎncă nu există evaluări
- Residual AnalysisDocument6 paginiResidual AnalysisGagandeep SinghÎncă nu există evaluări
- 5682 - 4433 - Factor & Cluster AnalysisDocument22 pagini5682 - 4433 - Factor & Cluster AnalysisSubrat NandaÎncă nu există evaluări
- Analysis of Variance (Anova)Document67 paginiAnalysis of Variance (Anova)thanawat sungsomboonÎncă nu există evaluări
- Supply Chain System Dynamics VGDocument10 paginiSupply Chain System Dynamics VGapi-3854027Încă nu există evaluări
- Harvard Referencing: AIC LSU Student ResourcesDocument20 paginiHarvard Referencing: AIC LSU Student ResourcesAmir PanditÎncă nu există evaluări
- Validation of The General Health QuestionnaireDocument9 paginiValidation of The General Health QuestionnaireBoitor ValerianÎncă nu există evaluări
- Experimental Design and Statistical AnalysisDocument75 paginiExperimental Design and Statistical AnalysisAli RostamiÎncă nu există evaluări
- Chapter 3 - Describing DataDocument39 paginiChapter 3 - Describing DatazanibabÎncă nu există evaluări
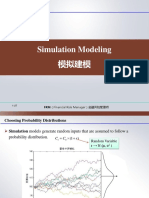
- 2.15 Simulation+Modeling+模拟建模Document27 pagini2.15 Simulation+Modeling+模拟建模James JiangÎncă nu există evaluări
- Measuement and ScalingDocument31 paginiMeasuement and Scalingagga1111Încă nu există evaluări
- SPSS T-Test Analyze Gender DifferencesDocument24 paginiSPSS T-Test Analyze Gender DifferencesRahman SurkhyÎncă nu există evaluări
- Combining Scores Multi Item ScalesDocument41 paginiCombining Scores Multi Item ScalesKevin CannonÎncă nu există evaluări
- Normal DistributionDocument19 paginiNormal DistributionreiÎncă nu există evaluări
- Threats To Construct ValidityDocument5 paginiThreats To Construct ValidityRiyan SetiawanÎncă nu există evaluări
- Predictor Variables of Cyberloafing and Perceived Organizational Acceptance (UnpublishedDocument5 paginiPredictor Variables of Cyberloafing and Perceived Organizational Acceptance (Unpublishedleksey24Încă nu există evaluări
- Correlation and Depression ScoresDocument9 paginiCorrelation and Depression ScoresARPITA DUTTAÎncă nu există evaluări
- Chi-Square Goodness of Fit TestDocument38 paginiChi-Square Goodness of Fit TestMadanish KannaÎncă nu există evaluări
- 4 Chap - Job Anal MPDQDocument6 pagini4 Chap - Job Anal MPDQsubash03Încă nu există evaluări
- Sampling Techniques ExplainedDocument53 paginiSampling Techniques ExplainedKent TongloyÎncă nu există evaluări
- Question 1Document18 paginiQuestion 1Mark Adrian FalcutilaÎncă nu există evaluări
- Hypothesis Testing: Ms. Anna Marie T. Ensano, MME CASTEDSWM Faculty Universidad de Sta. Isabel, Naga CityDocument25 paginiHypothesis Testing: Ms. Anna Marie T. Ensano, MME CASTEDSWM Faculty Universidad de Sta. Isabel, Naga Cityshane cansancioÎncă nu există evaluări
- Types of SamplingDocument3 paginiTypes of SamplingAwneesh Pratap Singh ChauhanÎncă nu există evaluări
- Chi-Square Test: by Dr. M.Supriya Moderator:Dr.B.Aruna, M.D. (H)Document75 paginiChi-Square Test: by Dr. M.Supriya Moderator:Dr.B.Aruna, M.D. (H)Nic OleÎncă nu există evaluări
- ValidityDocument17 paginiValidityifatimanaqvi1472100% (1)
- An Intro to SPSS - Statistical Analysis Software ExplainedDocument87 paginiAn Intro to SPSS - Statistical Analysis Software ExplainedAkshay PoplyÎncă nu există evaluări
- Module 5 - Ordinal RegressionDocument55 paginiModule 5 - Ordinal RegressionMy Hanh DoÎncă nu există evaluări
- Introduction To Multivariate Analysis: Dr. Ibrahim Awad IbrahimDocument36 paginiIntroduction To Multivariate Analysis: Dr. Ibrahim Awad IbrahimRohit kumarÎncă nu există evaluări
- PWJohnDocument378 paginiPWJohnmaleticj100% (1)
- Tests for Cognitive Impairment in Epilepsy PatientsDocument27 paginiTests for Cognitive Impairment in Epilepsy PatientsFiza JahanzebÎncă nu există evaluări
- X-Bar and R ChartsDocument13 paginiX-Bar and R ChartspraveenÎncă nu există evaluări
- Impact Teacher Questioning Strategy Student Motivation AchievementDocument6 paginiImpact Teacher Questioning Strategy Student Motivation AchievementBanu PriyaÎncă nu există evaluări
- BM105 Quantitative Methods AppendixDocument6 paginiBM105 Quantitative Methods AppendixEverboleh ChowÎncă nu există evaluări
- Quantitative Methods Mid QDocument3 paginiQuantitative Methods Mid Qsap6370Încă nu există evaluări
- Multiple Positions at Ministry of Health - BotswanaDocument38 paginiMultiple Positions at Ministry of Health - BotswanaRICKSON KAWINAÎncă nu există evaluări
- Non Parametric TestDocument3 paginiNon Parametric TestPankaj2cÎncă nu există evaluări
- DOE Report XinliShaDocument16 paginiDOE Report XinliShaXinli ShaÎncă nu există evaluări
- Measurement and Scaling Fundamentals for ResearchDocument28 paginiMeasurement and Scaling Fundamentals for ResearchSavya JaiswalÎncă nu există evaluări
- Museum Entrance: Welcome To The Museum of Managing E-Learning - Group 3 ToolsDocument31 paginiMuseum Entrance: Welcome To The Museum of Managing E-Learning - Group 3 ToolsRebeccaKylieHallÎncă nu există evaluări
- RELIABILITYDocument11 paginiRELIABILITYYogi Saputra MahmudÎncă nu există evaluări
- Chapter 2 of One - Theory of Control ChartDocument36 paginiChapter 2 of One - Theory of Control ChartAmsalu SeteyÎncă nu există evaluări
- Mann Whitney ExampleDocument30 paginiMann Whitney ExampleRohaila RohaniÎncă nu există evaluări
- Edu6950 Multiple RegressionDocument24 paginiEdu6950 Multiple RegressionSa'adah JamaluddinÎncă nu există evaluări
- 2 Way AnovaDocument20 pagini2 Way Anovachawlavishnu100% (1)
- Kolmogorov-Smirnov Two Sample Test AnalysisDocument17 paginiKolmogorov-Smirnov Two Sample Test AnalysisRIGIL KENT CALANTOCÎncă nu există evaluări
- How To Do Xtabond2: An Introduction To "Difference" and "System" GMM in Stata by David RoodmanDocument45 paginiHow To Do Xtabond2: An Introduction To "Difference" and "System" GMM in Stata by David RoodmanAnwar AanÎncă nu există evaluări
- Data AnalysisDocument55 paginiData AnalysisSwati PowarÎncă nu există evaluări
- Tests For One Poisson MeanDocument9 paginiTests For One Poisson MeanJulyAntoÎncă nu există evaluări
- This Content Downloaded From 193.227.169.41 On Mon, 05 Oct 2020 10:59:36 UTCDocument7 paginiThis Content Downloaded From 193.227.169.41 On Mon, 05 Oct 2020 10:59:36 UTCChristianÎncă nu există evaluări
- Motivation Notes LuthansDocument14 paginiMotivation Notes LuthansPAWANÎncă nu există evaluări
- Some Important Questions For The Paper Managerial Economics'Document3 paginiSome Important Questions For The Paper Managerial Economics'Amit VshneyarÎncă nu există evaluări
- Confirmatory Factor Analysis (CFA) of First Order Factor Measurement Model-ICT Empowerment in NigeriaDocument8 paginiConfirmatory Factor Analysis (CFA) of First Order Factor Measurement Model-ICT Empowerment in NigeriazainidaÎncă nu există evaluări
- Experimental Designs PDFDocument2 paginiExperimental Designs PDFGiovanneÎncă nu există evaluări
- Analyze Variance with One-Way and Two-Way ANOVADocument19 paginiAnalyze Variance with One-Way and Two-Way ANOVALabiz Saroni Zida0% (1)
- Sem With Amos I PDFDocument68 paginiSem With Amos I PDFgunturean100% (1)
- FactorAnalysis - APA - Varied DataDocument19 paginiFactorAnalysis - APA - Varied DataAbdulaziz FarhanÎncă nu există evaluări
- Multiple Regression AnalysisDocument77 paginiMultiple Regression Analysishayati5823Încă nu există evaluări
- Continuous Improvement A Complete Guide - 2019 EditionDe la EverandContinuous Improvement A Complete Guide - 2019 EditionÎncă nu există evaluări
- Chapter 2 Simple Linear Regression - Jan2023Document66 paginiChapter 2 Simple Linear Regression - Jan2023Lachyn SeidovaÎncă nu există evaluări
- Statistical Analysis: Linear RegressionDocument36 paginiStatistical Analysis: Linear RegressionDafter KhemboÎncă nu există evaluări
- Analysis of Credit Card Fraud Detection Methods: January 2009Document4 paginiAnalysis of Credit Card Fraud Detection Methods: January 2009saya ravi12Încă nu există evaluări
- Topic 19 Identifying The Appropriate Rejection Region For A Given Level of SignificanceDocument8 paginiTopic 19 Identifying The Appropriate Rejection Region For A Given Level of SignificancePrincess VernieceÎncă nu există evaluări
- What Is Hypothesis Testing Procedure - Business JargonsDocument8 paginiWhat Is Hypothesis Testing Procedure - Business JargonsSivaÎncă nu există evaluări
- Presentation On The Martingale TheoryDocument31 paginiPresentation On The Martingale TheoryRitankar MandalÎncă nu există evaluări
- Exploratory Data Analysis For Machine LearningDocument3 paginiExploratory Data Analysis For Machine LearningGabriel PessineÎncă nu există evaluări
- Econ140 Spring2016 Section07 Handout SolutionsDocument6 paginiEcon140 Spring2016 Section07 Handout SolutionsFatemeh IglinskyÎncă nu există evaluări
- Introduction To Seaborn: Chris MoDocument18 paginiIntroduction To Seaborn: Chris MovrhdzvÎncă nu există evaluări
- Solomon Press S1JDocument4 paginiSolomon Press S1JnmanÎncă nu există evaluări
- CustomerChurn AssignmentDocument15 paginiCustomerChurn AssignmentMalavika R Kumar100% (3)
- Erlang Loss Table PDFDocument2 paginiErlang Loss Table PDFKathrynÎncă nu există evaluări
- FMOLS ModelDocument8 paginiFMOLS Modelsaeed meoÎncă nu există evaluări
- RHandbookProgramEvaluation PDFDocument759 paginiRHandbookProgramEvaluation PDFflorin100% (1)
- Lesson 2: Hypothesis Testing What Is A Hypothesis?Document3 paginiLesson 2: Hypothesis Testing What Is A Hypothesis?Mina MyouiÎncă nu există evaluări
- Advanced Statistics Manual PDFDocument258 paginiAdvanced Statistics Manual PDFhamartinez100% (3)
- Classes Tutor: Syllabus Statistics For Economics and Business 3 Credit SemesterDocument6 paginiClasses Tutor: Syllabus Statistics For Economics and Business 3 Credit SemesterAnida LalaÎncă nu există evaluări
- Statistical Evaluations in Exploration For Mineral Deposits - Prof. Dr. Friedrich-Wilhelm Wellmer PDFDocument387 paginiStatistical Evaluations in Exploration For Mineral Deposits - Prof. Dr. Friedrich-Wilhelm Wellmer PDFShofi Hawan100% (2)
- Assessing Measurement Model Quality in PLS-SEM Using Confirmatory Composite AnalysisDocument10 paginiAssessing Measurement Model Quality in PLS-SEM Using Confirmatory Composite AnalysisKin ZackÎncă nu există evaluări
- MIT18 650F16 PSet1Document4 paginiMIT18 650F16 PSet1Mithilesh KumarÎncă nu există evaluări
- Random VariablesDocument82 paginiRandom VariablesJuncar TomeÎncă nu există evaluări
- AP Statistics SyllabusDocument4 paginiAP Statistics SyllabusdarshÎncă nu există evaluări
- Lapres Olah Data DBP - Prasdira Ayu Maithsa Hasna - 26040121120033 - Kel1Document9 paginiLapres Olah Data DBP - Prasdira Ayu Maithsa Hasna - 26040121120033 - Kel1Yusuf RPÎncă nu există evaluări
- III Sem. B.SC Mathematics-Complementary Course - Statistical Inference On10Dec2015Document47 paginiIII Sem. B.SC Mathematics-Complementary Course - Statistical Inference On10Dec2015லட்சுமணன் சு0% (4)
- Session 9Document23 paginiSession 9eframil landuanÎncă nu există evaluări
- Standard Deviation Grouped DataDocument5 paginiStandard Deviation Grouped DataArielle T. TanÎncă nu există evaluări
- Confidence Interval ReviewDocument13 paginiConfidence Interval ReviewJenny HuynhÎncă nu există evaluări
- Normal Probability Curve: By: Keerthi Samuel.K, Lecturer Vijay Marie College of NursingDocument22 paginiNormal Probability Curve: By: Keerthi Samuel.K, Lecturer Vijay Marie College of NursingSree LathaÎncă nu există evaluări
- ANOVA TABLEDocument5 paginiANOVA TABLEMohd Farhan MakhlisÎncă nu există evaluări
- 18.1 The Central Limit Theorem (Again) : Chapter 18 - Inference About MeansDocument5 pagini18.1 The Central Limit Theorem (Again) : Chapter 18 - Inference About MeansRizal IlhamÎncă nu există evaluări
- Spearman's Rank-Order CorrelationDocument10 paginiSpearman's Rank-Order CorrelationBubblesÎncă nu există evaluări
- Praktikum Adk 3Document6 paginiPraktikum Adk 3Arlinda Amalia DewayantiÎncă nu există evaluări