S-ar putea să vă placă și
- Speed Up Your Queries With Hive LLAP Engine On Hadoop or in The CloudDocument29 paginiSpeed Up Your Queries With Hive LLAP Engine On Hadoop or in The CloudSomasekhar GantiÎncă nu există evaluări
- Hadoop Introduction FinalDocument13 paginiHadoop Introduction FinalAcharya KandalaÎncă nu există evaluări
- Hadoop Tutorials: Daniel Lanza Zbigniew BaranowskiDocument49 paginiHadoop Tutorials: Daniel Lanza Zbigniew BaranowskiRavi KumarÎncă nu există evaluări
- Hadoop - HiveDocument190 paginiHadoop - HiveJhumri TalaiyaÎncă nu există evaluări
- BigData HadoopDocument87 paginiBigData HadoopSivaprasad Reddy100% (1)
- Hadoop IntroductionDocument29 paginiHadoop IntroductiondebmatraÎncă nu există evaluări
- Presto: Sql-On-Anything: Dataworks Summit, San Jose 2017Document31 paginiPresto: Sql-On-Anything: Dataworks Summit, San Jose 2017DheepikaÎncă nu există evaluări
- Exam 70-445 PrepDocument56 paginiExam 70-445 PrepShivÎncă nu există evaluări
- BigData Unit 2Document15 paginiBigData Unit 2Sreedhar ArikatlaÎncă nu există evaluări
- Hadoop Course Outline UPDATED SURESHDocument5 paginiHadoop Course Outline UPDATED SURESHRenu PareekÎncă nu există evaluări
- Hadoop Vs Apache SparkDocument6 paginiHadoop Vs Apache Sparkindolent56Încă nu există evaluări
- Data Sources: Databases File System Website Object StorageDocument4 paginiData Sources: Databases File System Website Object StorageNishant BannikoppaÎncă nu există evaluări
- StoreOnce Deepdive ISV IntegrationDocument77 paginiStoreOnce Deepdive ISV IntegrationGuillermo García GándaraÎncă nu există evaluări
- BigData OSFY NovDocument6 paginiBigData OSFY NovSid MehtaÎncă nu există evaluări
- 02-dw ArchitectureDocument31 pagini02-dw ArchitectureGiri SaranuÎncă nu există evaluări
- Intro To Apache SparkDocument66 paginiIntro To Apache SparkYohanes Eka WibawaÎncă nu există evaluări
- 2021 WebinarSeries BW4HANA V1Document18 pagini2021 WebinarSeries BW4HANA V1k84242000Încă nu există evaluări
- Cloudera Kudu DatasheetDocument2 paginiCloudera Kudu DatasheetMahrizal JafarÎncă nu există evaluări
- Training On Oracle Hyperion Products Suite: Amit SharmaDocument35 paginiTraining On Oracle Hyperion Products Suite: Amit SharmabispsolutionsÎncă nu există evaluări
- 2 Hadoop (Uploaded)Document82 pagini2 Hadoop (Uploaded)Prateek PoleÎncă nu există evaluări
- Katta - Distributed Lucene Index in ProductionDocument22 paginiKatta - Distributed Lucene Index in Productionvsodera100% (2)
- Bigdata Engineer Complete Syllabus: Presented byDocument21 paginiBigdata Engineer Complete Syllabus: Presented byChepuri Sravan KumarÎncă nu există evaluări
- Big Data Cheat SheetDocument1 paginăBig Data Cheat SheetShivam P SrivastavaÎncă nu există evaluări
- Berkeley Data Analytics Stack BDAS Overview Ion Stoica Strata 2013Document28 paginiBerkeley Data Analytics Stack BDAS Overview Ion Stoica Strata 2013dineshgomberÎncă nu există evaluări
- Hadoop PigDocument111 paginiHadoop PigJhumri TalaiyaÎncă nu există evaluări
- BDA Module2 Hadoop EcosystemDocument41 paginiBDA Module2 Hadoop EcosystemPrarthana Manavi100% (1)
- Big Data System: Prepared For: Dell Financial Services August 10, 2017Document12 paginiBig Data System: Prepared For: Dell Financial Services August 10, 2017sanjiv.sureshbabuÎncă nu există evaluări
- Hadoop Ecosystem: Data Is Mainly Categorized in 3 Types Under Big Data PlatformDocument12 paginiHadoop Ecosystem: Data Is Mainly Categorized in 3 Types Under Big Data PlatformDoubt broÎncă nu există evaluări
- Putting Apache Kafka To Use!: Building A Real-Time Data Platform For Event Streams!Document48 paginiPutting Apache Kafka To Use!: Building A Real-Time Data Platform For Event Streams!Bernd SandmannÎncă nu există evaluări
- Devops RoadmapDocument1 paginăDevops RoadmapsÎncă nu există evaluări
- Hadoop Ecosystem PDFDocument6 paginiHadoop Ecosystem PDFKittuÎncă nu există evaluări
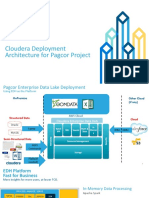
- Pagcor EDH Deployment ArchitectureDocument11 paginiPagcor EDH Deployment ArchitectureVener GuevarraÎncă nu există evaluări
- A Glimpse of The Hadoop EchosystemDocument16 paginiA Glimpse of The Hadoop EchosystemKhAn ZainabÎncă nu există evaluări
- Technical Specifications MysqlDocument2 paginiTechnical Specifications MysqlTanaka M KaririÎncă nu există evaluări
- Module 2.2Document32 paginiModule 2.2Priyanka BandagaleÎncă nu există evaluări
- Big Data & Hadoop Class Syllabus: Hdfs ClientsDocument2 paginiBig Data & Hadoop Class Syllabus: Hdfs Clientspunitha.jagan536Încă nu există evaluări
- Hadoop HBase Notes-Abhijit-NagargojeDocument24 paginiHadoop HBase Notes-Abhijit-NagargojeSanket PatilÎncă nu există evaluări
- QAware BigDataLandscape 2018 PDFDocument1 paginăQAware BigDataLandscape 2018 PDFValentina OrtegoÎncă nu există evaluări
- Xenstack Fullstack 03 PDFDocument1 paginăXenstack Fullstack 03 PDFPrashant SreedharanÎncă nu există evaluări
- Xenstack Fullstack 03 PDFDocument1 paginăXenstack Fullstack 03 PDFPrashant SreedharanÎncă nu există evaluări
- Xenstack Fullstack 03 PDFDocument1 paginăXenstack Fullstack 03 PDFPrashant SreedharanÎncă nu există evaluări
- Adoop Cosystem: S W S A, T L at 68Document22 paginiAdoop Cosystem: S W S A, T L at 68AnwarÎncă nu există evaluări
- Bigdata Hadoop: Fundamentals HiveDocument3 paginiBigdata Hadoop: Fundamentals HiveQuantico SmithÎncă nu există evaluări
- Cloud Native London HopsworksDocument33 paginiCloud Native London HopsworksJim DowlingÎncă nu există evaluări
- Big Data Landscape 2017Document1 paginăBig Data Landscape 2017ramÎncă nu există evaluări
- Apache Hadoop and Spark:: and Use Cases For Data AnalysisDocument48 paginiApache Hadoop and Spark:: and Use Cases For Data Analysissatish.sathya.a2012Încă nu există evaluări
- Technologies For Handling Big Data: Prepared By: Saidatul Rahah HamidiDocument49 paginiTechnologies For Handling Big Data: Prepared By: Saidatul Rahah HamidisyahminaÎncă nu există evaluări
- Assignment 4-Gcc: Hive Is NotDocument3 paginiAssignment 4-Gcc: Hive Is Notmini vÎncă nu există evaluări
- Data Warehousing & Analytics On Hadoop: Joydeep Sen Sarma, Ashish Thusoo Facebook Data TeamDocument19 paginiData Warehousing & Analytics On Hadoop: Joydeep Sen Sarma, Ashish Thusoo Facebook Data TeamChris HarrisÎncă nu există evaluări
- Introduc) On To BigdataDocument103 paginiIntroduc) On To BigdataSivaÎncă nu există evaluări
- 1DA17CS167 cs812 A5Document16 pagini1DA17CS167 cs812 A5Durastiti samayaÎncă nu există evaluări
- Hadoop EcosystemDocument56 paginiHadoop EcosystemRUGAL NEEMA MBA 2021-23 (Delhi)Încă nu există evaluări
- Hortonworks Data Platform (HDP)Document56 paginiHortonworks Data Platform (HDP)Harshit Bansal100% (1)
- Apache HIVEDocument105 paginiApache HIVEhemanth kumar p100% (1)
- Lesson 1 - Introduction To Big Data and HadoopDocument46 paginiLesson 1 - Introduction To Big Data and HadoopPoojaSampathÎncă nu există evaluări
- New World Hadoop Architectures (& What Problems They Really Solve) For DbasDocument44 paginiNew World Hadoop Architectures (& What Problems They Really Solve) For DbasAnonymous VVSLkDOAC1Încă nu există evaluări
- The Big Data Technology LandscapeDocument36 paginiThe Big Data Technology LandscapePonnusamy S PichaimuthuÎncă nu există evaluări
- Dataengineering - v2.0 - PDF - 2 - Batch Processing of Data With Spark and Hadoop On GCP - M2 - Executing Spark On Cloud DataprocDocument67 paginiDataengineering - v2.0 - PDF - 2 - Batch Processing of Data With Spark and Hadoop On GCP - M2 - Executing Spark On Cloud DataprocEdgar SanchezÎncă nu există evaluări
- Banking Data Analysis On HadoopDocument21 paginiBanking Data Analysis On HadoopShantanuÎncă nu există evaluări
- How To Choose The Color of Your CarDocument1 paginăHow To Choose The Color of Your CarshivasudhakarÎncă nu există evaluări
- Month Approx Dates Sanskrit Name English Name Tamil NameDocument2 paginiMonth Approx Dates Sanskrit Name English Name Tamil NameshivasudhakarÎncă nu există evaluări
- OC HUG 2014-10-4x3 Apache PhoenixDocument58 paginiOC HUG 2014-10-4x3 Apache PhoenixshivasudhakarÎncă nu există evaluări
- Numerology Number 33Document1 paginăNumerology Number 33shivasudhakarÎncă nu există evaluări
- Foods To Prefer After Childbirth PDFDocument4 paginiFoods To Prefer After Childbirth PDFshivasudhakarÎncă nu există evaluări
- Tamil Rasi Nakshatra Calculator TableDocument2 paginiTamil Rasi Nakshatra Calculator Tableshivasudhakar100% (1)
- Maha Mrtyunjaya MantraDocument3 paginiMaha Mrtyunjaya MantrashivasudhakarÎncă nu există evaluări
- HabitDocument1 paginăHabitTim BurtÎncă nu există evaluări
- Rubik 4 X 4 X 4 SolutionDocument47 paginiRubik 4 X 4 X 4 SolutionBMS_SOFTGUY100% (1)
- Chandrashtama Nakshatra MapDocument2 paginiChandrashtama Nakshatra MapshivasudhakarÎncă nu există evaluări
- 10 Essential Windows 10 Keyboard ShortcutsDocument1 pagină10 Essential Windows 10 Keyboard ShortcutsshivasudhakarÎncă nu există evaluări
- PowerPoint QSDocument4 paginiPowerPoint QSshivasudhakarÎncă nu există evaluări
- DG Citizen Watch Manual Model BL8030-53ADocument28 paginiDG Citizen Watch Manual Model BL8030-53A51f1Încă nu există evaluări
- Chandrashtama NakshatrasDocument3 paginiChandrashtama NakshatrasshivasudhakarÎncă nu există evaluări
- Agile Project Management EventsDocument1 paginăAgile Project Management EventsshivasudhakarÎncă nu există evaluări
- Star Rasi MapDocument1 paginăStar Rasi MapshivasudhakarÎncă nu există evaluări
- Resume 206352020Document1 paginăResume 206352020shivasudhakarÎncă nu există evaluări
- 17 Types of Verbs EnglishDocument2 pagini17 Types of Verbs Englishhasnat2004Încă nu există evaluări
- Numerology Number 66Document1 paginăNumerology Number 66shivasudhakarÎncă nu există evaluări
- Resume Temp 2063520Document1 paginăResume Temp 2063520shivasudhakarÎncă nu există evaluări
- 17 Types of Verbs EnglishDocument2 pagini17 Types of Verbs Englishhasnat2004Încă nu există evaluări
- White Paper SAFeDocument32 paginiWhite Paper SAFeNicolae Simina100% (2)
- Appendix A - Exercise BacklogDocument1 paginăAppendix A - Exercise BacklogshivasudhakarÎncă nu există evaluări
- Car Number SelectionDocument3 paginiCar Number SelectionshivasudhakarÎncă nu există evaluări
- Rubik 4 X 4 X 4 SolutionDocument47 paginiRubik 4 X 4 X 4 SolutionBMS_SOFTGUY100% (1)
- SSRN-id2681909 - DevOps Performance MeasuresDocument15 paginiSSRN-id2681909 - DevOps Performance MeasuresshivasudhakarÎncă nu există evaluări
- DG Citizen Watch Manual Model BL8030-53ADocument28 paginiDG Citizen Watch Manual Model BL8030-53A51f1Încă nu există evaluări
- Numerology Number 33Document1 paginăNumerology Number 33shivasudhakarÎncă nu există evaluări
- RRD Special Report - Advanced Analytics - Dec 2015Document14 paginiRRD Special Report - Advanced Analytics - Dec 2015shivasudhakarÎncă nu există evaluări
- CICDDocument1 paginăCICDshivasudhakarÎncă nu există evaluări
- Managing The Digital Firm: Chapter (6) CNT'D Introduction To BIDocument21 paginiManaging The Digital Firm: Chapter (6) CNT'D Introduction To BIAhmad YasserÎncă nu există evaluări
- BFC: High-Performance Distributed Big-File Cloud Storage Based On Key-Value StoreDocument10 paginiBFC: High-Performance Distributed Big-File Cloud Storage Based On Key-Value StoredbpublicationsÎncă nu există evaluări
- Obiee 12CDocument6 paginiObiee 12CDilip Kumar AluguÎncă nu există evaluări
- C Program of Student Database SystemDocument4 paginiC Program of Student Database SystemGobinda Narayan Ghose100% (1)
- Oracle Data Guard With TSMDocument9 paginiOracle Data Guard With TSMDens Can't Be Perfect100% (1)
- ISAM (An Acronym For Indexed Sequential Access Method) Is A Method For Creating, Maintaining, andDocument4 paginiISAM (An Acronym For Indexed Sequential Access Method) Is A Method For Creating, Maintaining, andNopeNopeÎncă nu există evaluări
- Data WarehouseDocument169 paginiData WarehouseParihar BabitaÎncă nu există evaluări
- Market Basket Analysis For Data Mining Concepts and TechniquesDocument4 paginiMarket Basket Analysis For Data Mining Concepts and TechniquesEduardo TorresÎncă nu există evaluări
- Jagajit Roy Project12Document47 paginiJagajit Roy Project12Aman Kumar ThakurÎncă nu există evaluări
- 43-Article Text-209-1-10-20181215Document10 pagini43-Article Text-209-1-10-20181215Nguyễn QuyênÎncă nu există evaluări
- Mysql NotesDocument67 paginiMysql Notestwinntower.9.11Încă nu există evaluări
- PCA2 (40 Marks) Code 30 Marks Viva 10 MarksDocument3 paginiPCA2 (40 Marks) Code 30 Marks Viva 10 MarksMouri RoyÎncă nu există evaluări
- Individual InventoryDocument14 paginiIndividual InventorySpsmu MarikinaCityÎncă nu există evaluări
- Validation Tool 1Document2 paginiValidation Tool 1Charish Monarca Rosaldes100% (2)
- LastrecoverylogDocument19 paginiLastrecoverylogRizky AlfarizzaÎncă nu există evaluări
- 3 Data Link LayerDocument64 pagini3 Data Link LayerMalathi SankarÎncă nu există evaluări
- Lesson 05 Course Advanced StorageDocument36 paginiLesson 05 Course Advanced StorageKrish LeeÎncă nu există evaluări
- DGS-5 Documentation v007 PDFDocument42 paginiDGS-5 Documentation v007 PDFVictor Macedo AchancarayÎncă nu există evaluări
- "Everyone Wants To Do The Model Work, Not The Data Work": Data Cascades in High-Stakes AIDocument15 pagini"Everyone Wants To Do The Model Work, Not The Data Work": Data Cascades in High-Stakes AIM Zain Ul AbidinÎncă nu există evaluări
- Data Collection, Data Gathering Instrument,: Quarter 4-Week 3 Practical Research 1 and Analysis ProceduresDocument2 paginiData Collection, Data Gathering Instrument,: Quarter 4-Week 3 Practical Research 1 and Analysis ProceduresCatherine RodeoÎncă nu există evaluări
- Cloud Backup and RecoveryDocument66 paginiCloud Backup and RecoveryCRISTIANÎncă nu există evaluări
- Fraud Risk Reduction and Checkpoint Optimization For Mobile Financial Services in BangladeshDocument15 paginiFraud Risk Reduction and Checkpoint Optimization For Mobile Financial Services in Bangladeshindex PubÎncă nu există evaluări
- Matlab Project PDFDocument6 paginiMatlab Project PDFKHAIRUL ANWAR BIN HANAFIAH FKMÎncă nu există evaluări
- Chapter Four: The Research DesignDocument24 paginiChapter Four: The Research DesignAdonayt BezunehÎncă nu există evaluări
- MCQSDocument8 paginiMCQSAnkit Garg100% (1)
- Cloning Oracle Apps 11i With Rapid CloneDocument7 paginiCloning Oracle Apps 11i With Rapid ClonekrishnanaamdasÎncă nu există evaluări
- Qlikview, Data Analyst JDDocument2 paginiQlikview, Data Analyst JDMISS_ARORAÎncă nu există evaluări
- Competency Dictionary-PASSODocument2 paginiCompetency Dictionary-PASSOJaymark L. AgmataÎncă nu există evaluări
- TSM Server Instrumentation TraceDocument48 paginiTSM Server Instrumentation TraceLeeWangÎncă nu există evaluări
- Cisco Press - CCIE Routing and Switching Flash CardsDocument181 paginiCisco Press - CCIE Routing and Switching Flash CardsfreealexÎncă nu există evaluări