S-ar putea să vă placă și
- Lectu RaDocument19 paginiLectu RafluxfluxorÎncă nu există evaluări
- Civallero, Edgardo (2015) - Libros Raros Paginas Extranas y Curiosas PDFDocument30 paginiCivallero, Edgardo (2015) - Libros Raros Paginas Extranas y Curiosas PDFClyo MendozaÎncă nu există evaluări
- html5 Cheatsheet EmezetaDocument2 paginihtml5 Cheatsheet EmezetaEdmundo CastilloÎncă nu există evaluări
- Las Arquitecturas Basadas en MicroserviciosDocument2 paginiLas Arquitecturas Basadas en MicroserviciosfluxfluxorÎncă nu există evaluări
- Criteria PatternDocument9 paginiCriteria PatternfluxfluxorÎncă nu există evaluări
- Metodos Formales 3Document7 paginiMetodos Formales 3fluxfluxorÎncă nu există evaluări
- Mis 3 Extensiones FavoritasDocument7 paginiMis 3 Extensiones FavoritasfluxfluxorÎncă nu există evaluări
- Introduccion Apis Rest PDFDocument162 paginiIntroduccion Apis Rest PDFPedro Fabián More83% (6)
- Informe Opssi Coyuntura 2018 PDFDocument16 paginiInforme Opssi Coyuntura 2018 PDFFer ZamoraÎncă nu există evaluări
- Actividad+2+M3 ConsignaDocument2 paginiActividad+2+M3 ConsignafluxfluxorÎncă nu există evaluări
- Admc07 - 4 IjkxDocument14 paginiAdmc07 - 4 Ijkxfanellex1Încă nu există evaluări
- Criptografía y Seguridad en ComputadoresDocument307 paginiCriptografía y Seguridad en ComputadoresDESCUDERO10% (1)
- CVCVCVDocument3 paginiCVCVCVfluxfluxorÎncă nu există evaluări
- Liz 110811143146 Phpapp01Document27 paginiLiz 110811143146 Phpapp01fluxfluxorÎncă nu există evaluări
- Gestion de Las ComunicacionesDocument22 paginiGestion de Las Comunicacionesfluxfluxor100% (1)
- Gestion de Rcursos Humanos Ues21Document6 paginiGestion de Rcursos Humanos Ues21fluxfluxorÎncă nu există evaluări
- Admin de Proyectos Ues212121Document10 paginiAdmin de Proyectos Ues212121fluxfluxorÎncă nu există evaluări
- Programadores Que No ProgramanDocument5 paginiProgramadores Que No ProgramanfluxfluxorÎncă nu există evaluări
- Unido M BD2Document7 paginiUnido M BD2fluxfluxorÎncă nu există evaluări
- CVDocument4 paginiCVfluxfluxorÎncă nu există evaluări
- Unido M BD2 PDFDocument162 paginiUnido M BD2 PDFfluxfluxorÎncă nu există evaluări
- UNIDO M AdminProyectos PDFDocument116 paginiUNIDO M AdminProyectos PDFfluxfluxorÎncă nu există evaluări
- El Concepto de EthosDocument8 paginiEl Concepto de Ethoscharly180683Încă nu există evaluări
- Manual Del Usuario StockFacilDocument36 paginiManual Del Usuario StockFacilfluxfluxor100% (1)
- Análisis de AlgoritmosDocument2 paginiAnálisis de AlgoritmosfluxfluxorÎncă nu există evaluări
- El Concepto de EthosDocument3 paginiEl Concepto de EthosfluxfluxorÎncă nu există evaluări
- Screencapture Blog Rootnite Opinion Sabes Realmente Que Es Devops 2018 08-03-14!12!41Document1 paginăScreencapture Blog Rootnite Opinion Sabes Realmente Que Es Devops 2018 08-03-14!12!41fluxfluxorÎncă nu există evaluări
- Lectura - Planificar La PruebaDocument19 paginiLectura - Planificar La PruebafluxfluxorÎncă nu există evaluări
- AnalisisDocument57 paginiAnalisisfluxfluxorÎncă nu există evaluări
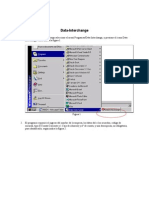
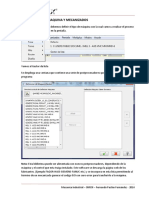
- Plan Sueldos Data-InterchangeDocument17 paginiPlan Sueldos Data-InterchangeHernan Martiniano RojasÎncă nu există evaluări
- S10.s1 - MaterialDocument21 paginiS10.s1 - MaterialAngnes aiÎncă nu există evaluări
- Interpolación Turistas España 1995Document5 paginiInterpolación Turistas España 1995Gabriela LópezÎncă nu există evaluări
- Planificación anual educación tecnológica 6o básico Colegio KalemDocument2 paginiPlanificación anual educación tecnológica 6o básico Colegio KalemPaulypola Opazo100% (5)
- Trabajo Viernes 15 SistemasDocument5 paginiTrabajo Viernes 15 SistemasJhõršhîtö ÄÏönêÎncă nu există evaluări
- Identidades trigonométricasDocument7 paginiIdentidades trigonométricasRicardoÎncă nu există evaluări
- EXAMEN DE CORRECCIÓN DE ERRORES Y ARQUITECTURA DE PROCESADORESDocument9 paginiEXAMEN DE CORRECCIÓN DE ERRORES Y ARQUITECTURA DE PROCESADORESBrian Meoño CalderónÎncă nu există evaluări
- Ejercicios Propuestos - Fase 3 - Programación y PruebasDocument9 paginiEjercicios Propuestos - Fase 3 - Programación y PruebasReneÎncă nu există evaluări
- Distribuciones de probabilidad continuas para modelado de datosDocument15 paginiDistribuciones de probabilidad continuas para modelado de datosAlonso MedinazÎncă nu există evaluări
- Microsoft Excel 2013 Guia Básica para UsuariosDocument87 paginiMicrosoft Excel 2013 Guia Básica para Usuariosalbrodz100% (1)
- Elza Carmen - Contabilidad III - Ejercicios Intervalos de Confianza - Estadistica Aplicada IDocument29 paginiElza Carmen - Contabilidad III - Ejercicios Intervalos de Confianza - Estadistica Aplicada Imersysc20% (1)
- Laboratorio 6.4.5Document10 paginiLaboratorio 6.4.5Chava GarciaÎncă nu există evaluări
- Guia para El Alumno. Introduccion A La Plataforma de CambridgeDocument7 paginiGuia para El Alumno. Introduccion A La Plataforma de CambridgeAlba Julieta Caballero PeñaÎncă nu există evaluări
- Reseña Histórica Del ComputadorDocument37 paginiReseña Histórica Del ComputadorVirginia MejiaÎncă nu există evaluări
- Tema - Configuración Inicial Firewall PIXDocument7 paginiTema - Configuración Inicial Firewall PIXYonathan SerranoÎncă nu există evaluări
- El Empowerment Es Un Baluarte de La Administración ModernaDocument2 paginiEl Empowerment Es Un Baluarte de La Administración ModernaHéctor BañolÎncă nu există evaluări
- TN - Eltek Flatpack v0.1 20181116Document23 paginiTN - Eltek Flatpack v0.1 20181116Alcides QuijadaÎncă nu există evaluări
- Técnicas para La Toma de Decisiones en GrupoDocument2 paginiTécnicas para La Toma de Decisiones en GrupoKevin RiveraÎncă nu există evaluări
- Tema 1Document5 paginiTema 1Purple pirriÎncă nu există evaluări
- Espinosa Luis Act3Document11 paginiEspinosa Luis Act3Anonymous 6mqqa5TC60% (5)
- Tutorial Mastercam X5Document60 paginiTutorial Mastercam X5Daniel Alejandro Gomez75% (4)
- Plan de estudios de la carrera de SoftwareDocument3 paginiPlan de estudios de la carrera de Softwaremathewdj95100% (1)
- Norma de Competencia Laboral: ExpiraDocument4 paginiNorma de Competencia Laboral: ExpiraSysdatec Centro De Desarrollo Integral100% (1)
- Registro IndustrialDocument8 paginiRegistro Industrialhurona555Încă nu există evaluări
- Protocolo - Elaboración Del PEIDocument59 paginiProtocolo - Elaboración Del PEIManuel Ramos Ccuno0% (1)
- Plan de Leccion Programacion de Obra Utilizando Ms Project Linea Base Del ProyectoDocument3 paginiPlan de Leccion Programacion de Obra Utilizando Ms Project Linea Base Del ProyectoJohn Alexánder Rodríguez FontechaÎncă nu există evaluări
- Librerías C ++Document16 paginiLibrerías C ++Eric Joel Perez GuevaraÎncă nu există evaluări
- Inventario vial Variante Condina km 6-7Document32 paginiInventario vial Variante Condina km 6-7David Esteban Serna RestrepoÎncă nu există evaluări
- Ejercicio para Proyecto Final BDDocument3 paginiEjercicio para Proyecto Final BDYeison0% (1)
- Base de Datos FinalDocument30 paginiBase de Datos Finalisabela gonzalesÎncă nu există evaluări