S-ar putea să vă placă și
- NNNNNDocument31 paginiNNNNNJesus Miguel Pana0% (2)
- Informe (Generacion de Variables Aleatorias)Document13 paginiInforme (Generacion de Variables Aleatorias)David J. Guzman0% (1)
- Distribución de PoissonDocument3 paginiDistribución de PoissonJezz JonasÎncă nu există evaluări
- Apuntes de Matemáticas para La Economía IDocument31 paginiApuntes de Matemáticas para La Economía IAsociación de Estudiantes Chinos de la Universidad Carlos III de Madrid100% (4)
- No Me Hagas Pensar PDFDocument196 paginiNo Me Hagas Pensar PDFChristian Camilo Parra100% (11)
- Lineas de EsperaDocument43 paginiLineas de EsperairmabaezÎncă nu există evaluări
- Mapa Mental Simulacion GDocument2 paginiMapa Mental Simulacion GDanielaÎncă nu există evaluări
- Test ProbabilidadDocument62 paginiTest ProbabilidadomarÎncă nu există evaluări
- Otras Distribuciones ContinuasDocument12 paginiOtras Distribuciones ContinuasJimmy JaramilloÎncă nu există evaluări
- Tema 9. Distribuciones de Probabilidad de Variable Discreta. Ejercicios Planteados. SolucionesDocument18 paginiTema 9. Distribuciones de Probabilidad de Variable Discreta. Ejercicios Planteados. SolucionesGarmin196Încă nu există evaluări
- Generacion de Variables AleatoriasDocument23 paginiGeneracion de Variables AleatoriasCesar Bernal Rocha100% (1)
- Método de Generación de Variables Aleatorias ContinuasDocument29 paginiMétodo de Generación de Variables Aleatorias ContinuasRenato Requena CárdenasÎncă nu există evaluări
- Variables AleatoriasDocument7 paginiVariables AleatoriasKrito HdezÎncă nu există evaluări
- Clase Numero 3Document14 paginiClase Numero 3jesusÎncă nu există evaluări
- Matematica Aplicada 3 Usac IngenieriaDocument21 paginiMatematica Aplicada 3 Usac IngenieriaFrancis MonroyÎncă nu există evaluări
- Sesión - Inecuaciones PolinómicasDocument4 paginiSesión - Inecuaciones PolinómicasFrank Gomez bernillaÎncă nu există evaluări
- Sesión - Inecuaciones PolinómicasDocument4 paginiSesión - Inecuaciones PolinómicasFrank Gomez bernillaÎncă nu există evaluări
- Sesión - Inecuaciones PolinómicasDocument4 paginiSesión - Inecuaciones PolinómicasFrank Gomez bernillaÎncă nu există evaluări
- Metodo de NewtonDocument11 paginiMetodo de NewtonErnesto RodriguezÎncă nu există evaluări
- Derivada de Una Función - Ciencias GerencialesDocument14 paginiDerivada de Una Función - Ciencias GerencialesDaniel Uno MásÎncă nu există evaluări
- Generación variables aleatorias no-uniformesDocument12 paginiGeneración variables aleatorias no-uniformesEvangelina Mariscal EsquivelÎncă nu există evaluări
- Análisis de conceptos matemáticosDocument18 paginiAnálisis de conceptos matemáticosLeandro Ubrí LorenzoÎncă nu există evaluări
- ¿Cómo Resolver Inecuaciones Trigonométricas?Document6 pagini¿Cómo Resolver Inecuaciones Trigonométricas?wilsonÎncă nu există evaluări
- Semana 6 SimulaciónDocument41 paginiSemana 6 SimulaciónFranco Trujillo CayllahuaÎncă nu există evaluări
- 2 SoluciÓn de Ecuaciones AlgebraicasDocument17 pagini2 SoluciÓn de Ecuaciones AlgebraicaskchuchakÎncă nu există evaluări
- Interpolacion y Ajuste de Curvas PDFDocument5 paginiInterpolacion y Ajuste de Curvas PDFJesse MauricioÎncă nu există evaluări
- Metodo de Newton-RaphsonDocument5 paginiMetodo de Newton-RaphsonRodrigo chavez mendozaÎncă nu există evaluări
- Métodos de Solución de EcuacionesDocument13 paginiMétodos de Solución de EcuacionesvanesitaÎncă nu există evaluări
- Generacion de Variables AleatoriasDocument13 paginiGeneracion de Variables AleatoriasDulce EstrellaÎncă nu există evaluări
- Tema Inv. Operaciones II Sesión 06Document6 paginiTema Inv. Operaciones II Sesión 06MOSTACHOU'S GAMER “BARBAS”Încă nu există evaluări
- Ecuaciones DiferencialesDocument113 paginiEcuaciones DiferencialesNathalie Ortiz100% (1)
- Consolidado Borrador Tarea 3Document12 paginiConsolidado Borrador Tarea 3Raul Andres CastañedaÎncă nu există evaluări
- Formulas Ecuaciones Diferenciales (By Carrascal)Document11 paginiFormulas Ecuaciones Diferenciales (By Carrascal)Iñaki100% (5)
- Guia de Polinomios. - 2021Document20 paginiGuia de Polinomios. - 2021HansAcevedoÎncă nu există evaluări
- Examen Calculo 1 SupereriorDocument4 paginiExamen Calculo 1 SupereriorKevin ValdezÎncă nu există evaluări
- Metodo de Newton RaphsonDocument11 paginiMetodo de Newton RaphsonDR. JUAN JESÚS SORIA QUIJAITE50% (2)
- Funciones y AplicacionesDocument7 paginiFunciones y AplicacionesAntonio Chumpitaz JulcaÎncă nu există evaluări
- Simulación variables aleatoriasDocument10 paginiSimulación variables aleatoriasMarco HAÎncă nu există evaluări
- Métodos numéricos raíces ecuacionesDocument34 paginiMétodos numéricos raíces ecuacionesThomas Romero100% (1)
- Derivadas Parciales TeoriaDocument5 paginiDerivadas Parciales Teoriarefrigeracion10Încă nu există evaluări
- Analisis Matematico Resumen Segundo ParcialDocument2 paginiAnalisis Matematico Resumen Segundo ParcialkevinÎncă nu există evaluări
- Resolución de ecuaciones no lineales mediante métodos numéricosDocument31 paginiResolución de ecuaciones no lineales mediante métodos numéricosBruno Martín MatoÎncă nu există evaluări
- Analisis Numerico Tema 2Document16 paginiAnalisis Numerico Tema 2Nicolás MéndezÎncă nu există evaluări
- Multiplicadores de LagrangeDocument23 paginiMultiplicadores de LagrangeANDY RODRIGO NOLE DUCOSÎncă nu există evaluări
- Polinomios Hermite y sus propiedadesDocument14 paginiPolinomios Hermite y sus propiedadesFabrico Alexander Guevara ArcoÎncă nu există evaluări
- Derivadas CombinadasDocument10 paginiDerivadas CombinadasDaniel CedeñoÎncă nu există evaluări
- Metodos para Generar Variables AleatoriasDocument24 paginiMetodos para Generar Variables AleatoriasYusz Morales100% (1)
- Función y sus elementosDocument5 paginiFunción y sus elementosdeisyÎncă nu există evaluări
- Pauta Examen Cálculo Diferencial 2021-2Document3 paginiPauta Examen Cálculo Diferencial 2021-2Guillermo Eduardo RiverosÎncă nu există evaluări
- Introduccion Variable Aleatorias PDFDocument23 paginiIntroduccion Variable Aleatorias PDFJavi GalleguillosÎncă nu există evaluări
- Métodos NuméricosDocument3 paginiMétodos NuméricosConstanza AliciaÎncă nu există evaluări
- Tema 8 - Variable Aleatoria. Modelos de DistribucionesDocument15 paginiTema 8 - Variable Aleatoria. Modelos de DistribucionesCarlos BorjaÎncă nu există evaluări
- Simulación de variables aleatoriasDocument8 paginiSimulación de variables aleatoriasCarlos Gianni MedelÎncă nu există evaluări
- Cálculo DiferencialDocument11 paginiCálculo Diferencialalejandro pulidoÎncă nu există evaluări
- Ecuaciones Lineales de Primer Orden PDFDocument7 paginiEcuaciones Lineales de Primer Orden PDFEzequiel EspitiaÎncă nu există evaluări
- Guia Aprendizaje Aplicaciones Calculo DiferencialDocument19 paginiGuia Aprendizaje Aplicaciones Calculo DiferencialJeissonArturoNuñezVeraÎncă nu există evaluări
- 02_Semana 02 - 2022-IDocument25 pagini02_Semana 02 - 2022-IMariluz Alexandra Vega QuispeÎncă nu există evaluări
- Distribuciones de Prob. en SimulaciónDocument58 paginiDistribuciones de Prob. en SimulaciónSebastiÁn NavarroÎncă nu există evaluări
- 6. Modelos de variable no lineales (Varias variable)Document17 pagini6. Modelos de variable no lineales (Varias variable)Walberto CantilloÎncă nu există evaluări
- Resumen 2Document14 paginiResumen 2Claudia GuillenÎncă nu există evaluări
- AlgebraDocument208 paginiAlgebraTatiana Sofia Hernandez TovarÎncă nu există evaluări
- Clase 13 2021BDocument9 paginiClase 13 2021Bjustin alejandro avila vivancoÎncă nu există evaluări
- Tema 2 Teoria VariableDocument8 paginiTema 2 Teoria VariableIvan OstaÎncă nu există evaluări
- Taller de MatemáticasDocument24 paginiTaller de MatemáticasSantiago garcia pinedaÎncă nu există evaluări
- Teoria de Derivada 1 PDFDocument4 paginiTeoria de Derivada 1 PDFBarbara VieiraÎncă nu există evaluări
- InfinitesimalDocument3 paginiInfinitesimalAnthony PrestonÎncă nu există evaluări
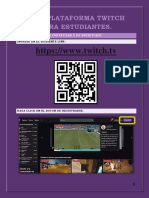
- Guía Twitch estudiantes 40cDocument10 paginiGuía Twitch estudiantes 40cKevin ArroyoÎncă nu există evaluări
- Tarea 8 Kevin Arroyo MontañoDocument1 paginăTarea 8 Kevin Arroyo MontañoKevin ArroyoÎncă nu există evaluări
- El Aprendizaje Del Dibujo Como Herramienta Del ConocimientoDocument244 paginiEl Aprendizaje Del Dibujo Como Herramienta Del Conocimientocarloscopio100% (1)
- Sistema de Numeración BinarioDocument2 paginiSistema de Numeración BinarioKevin ArroyoÎncă nu există evaluări
- Ilovepdf MergedDocument2 paginiIlovepdf MergedKevin ArroyoÎncă nu există evaluări
- ApkDocument2 paginiApkKevin ArroyoÎncă nu există evaluări
- E A7S OnboardingDocument1 paginăE A7S OnboardingKevin ArroyoÎncă nu există evaluări
- Tutorial de ReactJS PDFDocument14 paginiTutorial de ReactJS PDFJC KaiserÎncă nu există evaluări
- Guión Audiovisual Google DriveDocument2 paginiGuión Audiovisual Google DriveCRISTHIAN CAMILO MONROY UNIVIOÎncă nu există evaluări
- ListaGanadores DestapaDocument1 paginăListaGanadores DestapaKevin ArroyoÎncă nu există evaluări
- Redactando El Marco Teórico-25-09-2020Document9 paginiRedactando El Marco Teórico-25-09-2020Kevin ArroyoÎncă nu există evaluări
- Aplicación Delivery!Document1 paginăAplicación Delivery!Kevin ArroyoÎncă nu există evaluări
- PDA Informal Julio 2021Document1 paginăPDA Informal Julio 2021Kevin ArroyoÎncă nu există evaluări
- 43ji1-10 - MODELO DE BRIEFDocument2 pagini43ji1-10 - MODELO DE BRIEFKevin ArroyoÎncă nu există evaluări
- UcI2V-20210724100159 PCA CINEMA 4DDocument6 paginiUcI2V-20210724100159 PCA CINEMA 4DKevin ArroyoÎncă nu există evaluări
- Animación y postproducción audiovisual UCATECDocument6 paginiAnimación y postproducción audiovisual UCATECKevin ArroyoÎncă nu există evaluări
- Auxiliares 2-2020 Sis-InfDocument2 paginiAuxiliares 2-2020 Sis-InfKevin ArroyoÎncă nu există evaluări
- PDA Formal Julio 2021Document1 paginăPDA Formal Julio 2021Kevin ArroyoÎncă nu există evaluări
- InstalaciónDocument2 paginiInstalaciónKevin ArroyoÎncă nu există evaluări
- InstalaciónDocument2 paginiInstalaciónKevin ArroyoÎncă nu există evaluări
- Plan de Trabajo Tendencias Pedagogicas ContemporaneasDocument7 paginiPlan de Trabajo Tendencias Pedagogicas ContemporaneasKevin ArroyoÎncă nu există evaluări
- Practica1 2-2020Document2 paginiPractica1 2-2020Kevin ArroyoÎncă nu există evaluări
- La Educación Virtual en BoliviaDocument2 paginiLa Educación Virtual en BoliviaKevin ArroyoÎncă nu există evaluări
- Barra de NavegacionDocument4 paginiBarra de NavegacionKevin ArroyoÎncă nu există evaluări
- Practica3 2-2020Document1 paginăPractica3 2-2020Kevin ArroyoÎncă nu există evaluări
- La Educación Virtual en BoliviaDocument2 paginiLa Educación Virtual en BoliviaKevin ArroyoÎncă nu există evaluări
- Reglamento Del Examen de MesaDocument33 paginiReglamento Del Examen de MesaRonald Huanca CalleÎncă nu există evaluări
- Respuesta Tercer ParcialDocument2 paginiRespuesta Tercer ParcialKevin ArroyoÎncă nu există evaluări
- RespuestaTercerParcial PDFDocument2 paginiRespuestaTercerParcial PDFKevin ArroyoÎncă nu există evaluări
- Interaprendizaje de Probabilidades y Estadística Inferencial Con Excel, Winstats y Graph PDFDocument228 paginiInteraprendizaje de Probabilidades y Estadística Inferencial Con Excel, Winstats y Graph PDFInocencioÎncă nu există evaluări
- Distribucion BinomialDocument26 paginiDistribucion Binomial00Horacio7537100% (1)
- Taller Normal Binomial Noviembre 26Document16 paginiTaller Normal Binomial Noviembre 26Silvana MariaÎncă nu există evaluări
- Fase 3 - Grupo 1Document44 paginiFase 3 - Grupo 1Nathaly AvilaÎncă nu există evaluări
- Prácticas LABORATORIO simulación eventos discretosDocument55 paginiPrácticas LABORATORIO simulación eventos discretosMarco AntonioÎncă nu există evaluări
- Tutorial MatLabDocument33 paginiTutorial MatLabEduardoÎncă nu există evaluări
- Distribución Normal en Estadística InferencialDocument4 paginiDistribución Normal en Estadística InferencialMelvin Loaypardo VilchezÎncă nu există evaluări
- Estadística UNMSM 2014Document3 paginiEstadística UNMSM 2014Dilan AseretoÎncă nu există evaluări
- Planes Anuales de Estudios Matemáticos para Bachillerato InternacionalDocument11 paginiPlanes Anuales de Estudios Matemáticos para Bachillerato InternacionalMario Orlando Suárez Ibujés75% (4)
- Foro 3.3Document9 paginiForo 3.3Patricia SilvaÎncă nu există evaluări
- Estadística I: Parcial II 03/07/19Document16 paginiEstadística I: Parcial II 03/07/19Agustin BruzzichelliÎncă nu există evaluări
- Modelos estocásticos: Proceso de PoissonDocument26 paginiModelos estocásticos: Proceso de PoissonValencia Hdi DennicksÎncă nu există evaluări
- Bolo 1 EstadisticaDocument22 paginiBolo 1 EstadisticaCynthiaRojasMendivilÎncă nu există evaluări
- TALLER 1 2 3 ProbabilidadesDocument3 paginiTALLER 1 2 3 ProbabilidadesRR886Încă nu există evaluări
- Distribucion NormalDocument6 paginiDistribucion NormalgeckozzÎncă nu există evaluări
- Consulta Estadistica 16.03.2022Document29 paginiConsulta Estadistica 16.03.2022Luz Marina LeónÎncă nu există evaluări
- Tipos de Distribucion en Estadistica InferencialDocument4 paginiTipos de Distribucion en Estadistica InferencialRaúl Anibal0% (1)
- Actividad 4, Cuadro ComparativoDocument9 paginiActividad 4, Cuadro ComparativoOskar DussanÎncă nu există evaluări
- 1.3 EJERCICIOS Distribucion de Probabilidades de Una Variable Aleatoria DiscretaDocument5 pagini1.3 EJERCICIOS Distribucion de Probabilidades de Una Variable Aleatoria DiscretaMike Rivera yahoo 07 y 2010Încă nu există evaluări
- Distribución ExponencialDocument9 paginiDistribución ExponencialMaria Jose Muro MedinaÎncă nu există evaluări
- Proyecto Estadistica IIDocument21 paginiProyecto Estadistica IINicole MoralesÎncă nu există evaluări