S-ar putea să vă placă și
- Juegos Estáticos Con Información Incompleta (Teoría)Document54 paginiJuegos Estáticos Con Información Incompleta (Teoría)Bruno MarchettiÎncă nu există evaluări
- 1er Examen Parcial Est 1 11oct2021Document2 pagini1er Examen Parcial Est 1 11oct2021Gustavo DanielÎncă nu există evaluări
- Caso Practico 1Document5 paginiCaso Practico 1cristina montealegre eÎncă nu există evaluări
- Aplicaciones de MuestreoDocument17 paginiAplicaciones de MuestreoNEO300Încă nu există evaluări
- Sesión 03 PDFDocument38 paginiSesión 03 PDFHermanos Julcamoro CortezÎncă nu există evaluări
- Formulas para El Muestreo Aleatorio SimpleDocument7 paginiFormulas para El Muestreo Aleatorio SimpleAnabel RuizÎncă nu există evaluări
- C-115 TP1 McoDocument12 paginiC-115 TP1 McoMary Nina MamaniÎncă nu există evaluări
- Gómez Baggethun EspañolDocument10 paginiGómez Baggethun EspañolPablo PodettiÎncă nu există evaluări
- Capitulo 7 EconometriaDocument5 paginiCapitulo 7 EconometriaCriss MorillasÎncă nu există evaluări
- Cap 8Document24 paginiCap 8camila fernandezÎncă nu există evaluări
- Ejercicios de Estadistica DescriptivaDocument5 paginiEjercicios de Estadistica DescriptivaFerchoMGÎncă nu există evaluări
- Ejercicio 1Document1 paginăEjercicio 1Hans KnigthÎncă nu există evaluări
- Distribuciones Muestrales - IC - PruebaHipotesis (ESTADISTICA)Document18 paginiDistribuciones Muestrales - IC - PruebaHipotesis (ESTADISTICA)Vladimir Gonzales TaipeÎncă nu există evaluări
- Variables EconomicasDocument21 paginiVariables EconomicasNando Cueva CarlosÎncă nu există evaluări
- Demo Formulario 104 Iva y 103 Retenciones SociedadesDocument37 paginiDemo Formulario 104 Iva y 103 Retenciones SociedadesVictor GomezÎncă nu există evaluări
- Informe Análisis EconométricoDocument12 paginiInforme Análisis EconométricoastridÎncă nu există evaluări
- Modelos GARCHDocument36 paginiModelos GARCHStuard GomezÎncă nu există evaluări
- Trabajo Econometria 3Document5 paginiTrabajo Econometria 3Gerardo OroscoÎncă nu există evaluări
- Guía de Estadística Descriptiva 2020Document18 paginiGuía de Estadística Descriptiva 2020Valentina BalladaresÎncă nu există evaluări
- Presentacion Estadistica AplicadaDocument7 paginiPresentacion Estadistica AplicadaALEXISÎncă nu există evaluări
- Formato ArticuloDocument3 paginiFormato ArticuloNohora Iriarte GarciaÎncă nu există evaluări
- Oferta y Demanda Agregada Del Ecuador Desde 2007Document14 paginiOferta y Demanda Agregada Del Ecuador Desde 2007KevinSamaniegoÎncă nu există evaluări
- Diccionario de Funciones Excel Ingles Español EstadisticaDocument7 paginiDiccionario de Funciones Excel Ingles Español Estadisticaverónica marquezÎncă nu există evaluări
- Práctica Guiada 5 StataDocument12 paginiPráctica Guiada 5 StataMarcela MorilloÎncă nu există evaluări
- Detección de Autocorrelación y Medidas CorrectivasDocument39 paginiDetección de Autocorrelación y Medidas CorrectivasYeison LondoñoÎncă nu există evaluări
- Diapositivas HistogramaDocument5 paginiDiapositivas Histogramaitalo leyner chavez zavalaÎncă nu există evaluări
- Tarea Ensayo Sobre Correlación y Regresión Lineal. Ebelio SalomónDocument6 paginiTarea Ensayo Sobre Correlación y Regresión Lineal. Ebelio Salomónjuan luis ibarra floresÎncă nu există evaluări
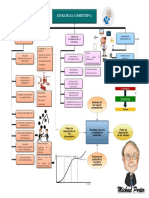
- Mapa Conceptual Estrategias CompetitivasDocument1 paginăMapa Conceptual Estrategias CompetitivasHasbeidy Andrea Sandoval CardenasÎncă nu există evaluări
- Caso Madurez de ValoresDocument4 paginiCaso Madurez de Valoresbyron pinargoteÎncă nu există evaluări
- Ejercicio de Desviacion Estandar y VarianzaDocument10 paginiEjercicio de Desviacion Estandar y VarianzaCAROÎncă nu există evaluări
- Clase 03 GAPDocument5 paginiClase 03 GAPLuis Amaya CedrónÎncă nu există evaluări
- Matrices EspecialesDocument10 paginiMatrices EspecialesBismar TarquiÎncă nu există evaluări
- MA311 201702 Laboratorio 3Document33 paginiMA311 201702 Laboratorio 3RobinsonÎncă nu există evaluări
- Estadistica 1Document2 paginiEstadistica 1Xuly ErmuÎncă nu există evaluări
- TP1Document11 paginiTP1LucioÎncă nu există evaluări
- Trabajo GrupalDocument6 paginiTrabajo GrupalMario CobosÎncă nu există evaluări
- Roca (2019) Macroeconomía GlobalDocument290 paginiRoca (2019) Macroeconomía GlobalAnonymous WyZwSz100% (1)
- 23) Desilgualdad, Intervalos, Notacion de Conjuntos e Intervalos, EjerciciosDocument3 pagini23) Desilgualdad, Intervalos, Notacion de Conjuntos e Intervalos, EjerciciosRolando GomezÎncă nu există evaluări
- La Determinación de La OfertaDocument8 paginiLa Determinación de La OfertaEva JihaadÎncă nu există evaluări
- Modulo de Analisis Estadistico Multivariado 2020Document59 paginiModulo de Analisis Estadistico Multivariado 2020Carmen RangelÎncă nu există evaluări
- Metodos Cuantitativos de PronosticosDocument52 paginiMetodos Cuantitativos de PronosticosErika Joanna Miramontes NietoÎncă nu există evaluări
- La Caja de EdgeworthDocument2 paginiLa Caja de EdgeworthCarlos PedrozaÎncă nu există evaluări
- Econometria Test 3y4Document17 paginiEconometria Test 3y4EduÎncă nu există evaluări
- Exposicion 5 Medicion Del Ingreso de Una Nacion Cap #23Document24 paginiExposicion 5 Medicion Del Ingreso de Una Nacion Cap #23Astrid HernándezÎncă nu există evaluări
- Guia de EstadísticaDocument70 paginiGuia de EstadísticaAristidesÎncă nu există evaluări
- 6.1 Tema - Distribuciones BidimensionalesDocument16 pagini6.1 Tema - Distribuciones Bidimensionalesyobarin4178 lizaraso damiano0% (1)
- Formato de Marco Logico Union EuropeaDocument1 paginăFormato de Marco Logico Union EuropeaOb Ro MillyshÎncă nu există evaluări
- Vectores AutoregresivoDocument2 paginiVectores AutoregresivoYamir Ortiz CabelloÎncă nu există evaluări
- ABSORBIDASDocument281 paginiABSORBIDASMrmmMrmm0% (1)
- REFLEXIONES SOBRE LA RELACION ENTRE ECONOMIA, ECONOMETRIA Y Epistemologia PDFDocument52 paginiREFLEXIONES SOBRE LA RELACION ENTRE ECONOMIA, ECONOMETRIA Y Epistemologia PDFJovi GriegoÎncă nu există evaluări
- El Chumal Sus Diferencias Con La Humita...Document3 paginiEl Chumal Sus Diferencias Con La Humita...Alfonsito ReinosoÎncă nu există evaluări
- Ejercicio de Heterocedasticidad y AutocorrelaciónDocument4 paginiEjercicio de Heterocedasticidad y Autocorrelaciónichaveza4058Încă nu există evaluări
- Series de Tiempo IDocument51 paginiSeries de Tiempo IIvi DownhamÎncă nu există evaluări
- Taller Clasificación ArancelariaDocument3 paginiTaller Clasificación ArancelariaAshly RuizÎncă nu există evaluări
- ReseñaDocument9 paginiReseñaDiana Alvis100% (1)
- Esquema Logico Metodos y Tecnicas de Investigacion CuantitativaDocument1 paginăEsquema Logico Metodos y Tecnicas de Investigacion CuantitativaMelany AmayaÎncă nu există evaluări
- 4 - Práctico 1 Variables y FrecuenciasDocument3 pagini4 - Práctico 1 Variables y FrecuenciascardozoanÎncă nu există evaluări
- Guia 1 Dominical Estadistica Introductoria 8 de AgostoDocument3 paginiGuia 1 Dominical Estadistica Introductoria 8 de Agostobertha gabriela juarez salinas100% (1)
- Correlacion Con SpssDocument6 paginiCorrelacion Con SpssSergio Villaseñor MorfinÎncă nu există evaluări
- Analisis Bivariado PDFDocument19 paginiAnalisis Bivariado PDFsucy asto fabianÎncă nu există evaluări
- Test Inteligencia EmocionalDocument3 paginiTest Inteligencia EmocionalDaniela AlvaradoÎncă nu există evaluări
- Actividad de DesempeñoDocument15 paginiActividad de Desempeñojuana barros100% (1)
- Evaluación de ActitudinalesDocument5 paginiEvaluación de ActitudinalesmariaÎncă nu există evaluări
- Componentes Del Proceso de EvaluaciónDocument1 paginăComponentes Del Proceso de EvaluaciónGonzalo Salvador100% (2)
- Módulo 2 Parte 1. Evaluaciones de DiagnósticoDocument16 paginiMódulo 2 Parte 1. Evaluaciones de Diagnósticoaitziber garciaÎncă nu există evaluări
- Curso de Estrategias para Aprender en Línea EfectivamenteDocument9 paginiCurso de Estrategias para Aprender en Línea EfectivamenteBrian GómezÎncă nu există evaluări
- Programa Investigación en IngenieríaDocument4 paginiPrograma Investigación en IngenieríaBrewichs Díaz H100% (1)
- Palacios Nahely U3T1a1Document5 paginiPalacios Nahely U3T1a1Nahely PalaciosÎncă nu există evaluări
- CETPRO EvaluaciónDocument10 paginiCETPRO EvaluaciónAlberto Julio Córdova Ricaldi100% (1)
- Certificado Aula FácilDocument2 paginiCertificado Aula FácilEdgar CogollosÎncă nu există evaluări
- Tema Estadistica A TratarDocument7 paginiTema Estadistica A Tratarhames yeyser cordoba BÎncă nu există evaluări
- Literatura NorteamericanaDocument7 paginiLiteratura Norteamericanacefyl2011Încă nu există evaluări
- I. HABITOS DE ESTUDIO CASM 85 (2) (1) .XLSX - INTRODocument32 paginiI. HABITOS DE ESTUDIO CASM 85 (2) (1) .XLSX - INTROChristel CarrilloÎncă nu există evaluări
- AUDITORIA INTERNA (Plan)Document6 paginiAUDITORIA INTERNA (Plan)Héctor David Escobar EstradaÎncă nu există evaluări
- Quiz 1Document7 paginiQuiz 1VIVIANA67% (3)
- El Reclutamiento y La Selección Del Personal Es Un Proceso Sumamente Importante Cuando Se Busca Un Talento NuevoDocument2 paginiEl Reclutamiento y La Selección Del Personal Es Un Proceso Sumamente Importante Cuando Se Busca Un Talento NuevoByron TitiÎncă nu există evaluări
- El Concepto de Costo Muerto o Costo IrrelevanteDocument3 paginiEl Concepto de Costo Muerto o Costo IrrelevanteAnonymous TNFrFX7Încă nu există evaluări
- Normas Concurso ConocimientosDocument2 paginiNormas Concurso ConocimientosCarlos Andrés Ramirez HinostrozaÎncă nu există evaluări
- Planeación Didáctica U1 Comport. OrganizDocument3 paginiPlaneación Didáctica U1 Comport. OrganizjorgeÎncă nu există evaluări
- Monografia Instrumentos de MediciónDocument15 paginiMonografia Instrumentos de MediciónPaola Funes BaldarragoÎncă nu există evaluări
- DX PedagógicoDocument8 paginiDX PedagógicoFernanda MonroyÎncă nu există evaluări
- Creacion Del SIELEDocument15 paginiCreacion Del SIELEjlforneoÎncă nu există evaluări
- Assessment CenterDocument69 paginiAssessment CenterCarlos Eduardo Gil Vargas100% (2)
- Cuaderno Tercer GradoDocument160 paginiCuaderno Tercer GradoAnonymous OHqMFrÎncă nu există evaluări
- Iso 15189Document12 paginiIso 15189Yaritza Borges100% (1)
- Ficha de Análisis - Anexo 1Document2 paginiFicha de Análisis - Anexo 1alejandra doradoÎncă nu există evaluări
- Crearcion de Examenes Con MoodleDocument29 paginiCrearcion de Examenes Con MoodlemadronitaÎncă nu există evaluări
- STAI IdareDocument14 paginiSTAI IdareIE del Prado100% (1)
- Escenarios - ABE 1Document11 paginiEscenarios - ABE 1Mariel Dayana Barrios BarriosÎncă nu există evaluări
- Tesis-IEBE. VERSIOìN FINAL-240921Document355 paginiTesis-IEBE. VERSIOìN FINAL-240921Mariela BorgesÎncă nu există evaluări