S-ar putea să vă placă și
- Disenos Experimentales Todo PDFDocument27 paginiDisenos Experimentales Todo PDFjearjearÎncă nu există evaluări
- Ppt16-Estadistica Aplicada A La EcologiaDocument26 paginiPpt16-Estadistica Aplicada A La EcologiaCRISTHIAN ALEXIS GOMEZ ARANIBARÎncă nu există evaluări
- Clase 06 - Estadistica 3 - Diseño de BloquesDocument3 paginiClase 06 - Estadistica 3 - Diseño de BloquesJesus CfÎncă nu există evaluări
- Analisis de VarianzaDocument15 paginiAnalisis de VarianzaElianaSotoÎncă nu există evaluări
- Disenos Experimentales TodoDocument27 paginiDisenos Experimentales TodoSARAHI FLores GuzmanÎncă nu există evaluări
- Clase 11 - Prueba de Hipotesis de Mas Tres Muestras o MediasDocument28 paginiClase 11 - Prueba de Hipotesis de Mas Tres Muestras o MediasSaeny E Soto AvilaÎncă nu există evaluări
- Sesiones de 15-17 - Diseños Experimentales PDFDocument22 paginiSesiones de 15-17 - Diseños Experimentales PDFEma Robles CastilloÎncă nu există evaluări
- Ova Sem 13 Analisis de Varianza de Un Solo FactorDocument9 paginiOva Sem 13 Analisis de Varianza de Un Solo FactorCarlos Oroya OjedaÎncă nu există evaluări
- Agro 6600Document98 paginiAgro 6600defrtyuhjÎncă nu există evaluări
- Diseño Por Bloques. Estadistica Inferencial IIDocument12 paginiDiseño Por Bloques. Estadistica Inferencial IIArath Sobrevilla100% (1)
- Diseño Completamente AleatorioDocument11 paginiDiseño Completamente AleatorioYHUREMA DEL CARMEN GELDRES TORRESÎncă nu există evaluări
- Unidad Ii Diseno de Experimentos de Un FDocument24 paginiUnidad Ii Diseno de Experimentos de Un FGladys BejaranoÎncă nu există evaluări
- Diseño de BloquesDocument28 paginiDiseño de BloquesGustavo Antonio Muñiz MorenoÎncă nu există evaluări
- Primer Trabajo Encargado Del Curso de Bioestadística ExperimentalDocument12 paginiPrimer Trabajo Encargado Del Curso de Bioestadística ExperimentalAli Mayta QuispeÎncă nu există evaluări
- Minitab 17 Ava Sesion 6 ManualDocument22 paginiMinitab 17 Ava Sesion 6 ManualmexalurgiaÎncă nu există evaluări
- Anova-Analisis de Varianza-Semana 16Document32 paginiAnova-Analisis de Varianza-Semana 16ÉstaMate Prof. Hender Noé Llauce ChapoñanÎncă nu există evaluări
- Diseño de Experimentos PDFDocument27 paginiDiseño de Experimentos PDFLuisa Jaramillo0% (1)
- Cap 07. Analisi de La Varianza.Document15 paginiCap 07. Analisi de La Varianza.Jorge Rojas GeldresÎncă nu există evaluări
- Flores Cuevas Cristian Julian PDFDocument11 paginiFlores Cuevas Cristian Julian PDFQueila Heras RÎncă nu există evaluări
- Semana 11 Diseños ExpDocument9 paginiSemana 11 Diseños ExpJames RCÎncă nu există evaluări
- Clase 3 Analisis de VarianzaDocument53 paginiClase 3 Analisis de VarianzaKenia GPÎncă nu există evaluări
- Diseño Completamente Al Azar - Diseños y Análisis ExperimentalesDocument53 paginiDiseño Completamente Al Azar - Diseños y Análisis ExperimentalesLourdes GómezÎncă nu există evaluări
- Clase 07 - Estadistica 3 - Diseño de Cuadrado LatinooDocument2 paginiClase 07 - Estadistica 3 - Diseño de Cuadrado LatinooJesus CfÎncă nu există evaluări
- Biometría Avanzada 2015 MacchiavelliDocument98 paginiBiometría Avanzada 2015 MacchiavelliByron FuentesÎncă nu există evaluări
- Diseño Bloques Al Azar COVID 2020Document5 paginiDiseño Bloques Al Azar COVID 2020mafersitasanchezÎncă nu există evaluări
- Unidad IIIDocument90 paginiUnidad IIILuis BS83% (6)
- Heber DbibDocument6 paginiHeber DbiblorenaÎncă nu există evaluări
- Analisis de CovarianzaDocument25 paginiAnalisis de CovarianzaMontserrat ChavesÎncă nu există evaluări
- Diseño Experimental: Curso: Estadística AplicadaDocument4 paginiDiseño Experimental: Curso: Estadística Aplicadacesar tineoÎncă nu există evaluări
- Disenos BasicosDocument15 paginiDisenos BasicosAndre SantillanaÎncă nu există evaluări
- Análisis Covarianza - DCADocument9 paginiAnálisis Covarianza - DCADenise Rosalyn Chalan LlajarunaÎncă nu există evaluări
- Diseño Completamente AleatorizadoDocument24 paginiDiseño Completamente AleatorizadoBrenda Vasquez ChungÎncă nu există evaluări
- Separata DBCA MEDocument5 paginiSeparata DBCA MEPercy GRÎncă nu există evaluări
- Trabajo Diseño de Bloques Al Azar Corregido 13-11-19Document21 paginiTrabajo Diseño de Bloques Al Azar Corregido 13-11-19Gilberto GilÎncă nu există evaluări
- Mat Est Inf II U V IgeDocument15 paginiMat Est Inf II U V IgeRichiie ZarateÎncă nu există evaluări
- Estadistica+general Sem-13 2022-2Document42 paginiEstadistica+general Sem-13 2022-2Rocio Huallpatuero SuicaÎncă nu există evaluări
- Tema 3Document24 paginiTema 3mariestrano97100% (1)
- Análisis de La Varianza en Dos Direcciones y N ObservacionesDocument7 paginiAnálisis de La Varianza en Dos Direcciones y N Observacionesjtanis68100% (1)
- Cuadros LatinosDocument19 paginiCuadros LatinosTatiana GuzmánÎncă nu există evaluări
- Anova TallerDocument100 paginiAnova Tallerjeisson leonardo rodriguez castilloÎncă nu există evaluări
- Analisis de Varianza en Un SentidoDocument9 paginiAnalisis de Varianza en Un SentidoJavier LucioÎncă nu există evaluări
- Analisis VarianzaDocument11 paginiAnalisis VarianzaColate Valverde CanoÎncă nu există evaluări
- G2 2 Lab03 Doe EquilibradoDocument4 paginiG2 2 Lab03 Doe EquilibradoEl Paisa21Încă nu există evaluări
- Diseño de Experimentos - Unidad IIIDocument15 paginiDiseño de Experimentos - Unidad IIILuisOrtiz9519Încă nu există evaluări
- Diseño de BloquesDocument17 paginiDiseño de BloquesLisset HernandezÎncă nu există evaluări
- Diseño Completamente Al AzarDocument9 paginiDiseño Completamente Al AzarJuan Miranda RamosÎncă nu există evaluări
- DCA DulcesDocument10 paginiDCA DulcesArturo VelascoÎncă nu există evaluări
- MA461 - 202001 - Semana 05 - Sesión 1 - DCADocument12 paginiMA461 - 202001 - Semana 05 - Sesión 1 - DCAYhurema D'l Carmen Geldres TorresÎncă nu există evaluări
- Ancova A3Document14 paginiAncova A3Alfredo RoblesÎncă nu există evaluări
- Análisis de Varianza de Dos FactoresDocument16 paginiAnálisis de Varianza de Dos FactoresPaola López SolorzanoÎncă nu există evaluări
- DBCA (Autoguardado)Document30 paginiDBCA (Autoguardado)Michael Zevallos RamosÎncă nu există evaluări
- ESTADISTICADocument9 paginiESTADISTICAtimacaruÎncă nu există evaluări
- Unidad Iv DbcaDocument17 paginiUnidad Iv DbcaCristopher Jisahac Chaves MontañoÎncă nu există evaluări
- Clase 16 AnovasDocument5 paginiClase 16 AnovasHans Heredia (Beto)Încă nu există evaluări
- Inferencia Con Dos MuestrasDocument7 paginiInferencia Con Dos MuestrasMar QuisarÎncă nu există evaluări
- DBCA (Autoguardado)Document24 paginiDBCA (Autoguardado)Michael Zevallos RamosÎncă nu există evaluări
- Cohen Octavus Roy - Paraiso en PeligroDocument196 paginiCohen Octavus Roy - Paraiso en PeligroMelissa LuTiÎncă nu există evaluări
- Exposicion BacteriologiaDocument26 paginiExposicion BacteriologiaMelissa LuTiÎncă nu există evaluări
- Parasitología Médica - Tay LaraDocument472 paginiParasitología Médica - Tay LaraNoemi Tavera81% (21)
- Cheyney Peter - Las Damas No EsperanDocument183 paginiCheyney Peter - Las Damas No EsperanMelissa LuTiÎncă nu există evaluări
- Características Virológicas Del VIHDocument8 paginiCaracterísticas Virológicas Del VIHRicardo Plascencia ValdezÎncă nu există evaluări
- Colestat Enzimatico AADocument3 paginiColestat Enzimatico AAMelissa LuTiÎncă nu există evaluări
- Hematología Manual Básico Razonado. Tercera EdiciónDocument17 paginiHematología Manual Básico Razonado. Tercera EdiciónMelissa LuTiÎncă nu există evaluări
- V 10 N 1 A 01Document2 paginiV 10 N 1 A 01GESTION HUMANAÎncă nu există evaluări
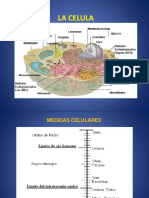
- Biologia Celular 3 (2016)Document15 paginiBiologia Celular 3 (2016)Melissa LuTiÎncă nu există evaluări
- BPM PDFDocument32 paginiBPM PDFJuan Carlos Valdera YslaÎncă nu există evaluări
- Ameghino, Florentino - Hallazgos CientificosDocument135 paginiAmeghino, Florentino - Hallazgos CientificosMelissa LuTiÎncă nu există evaluări
- Infectologia Kumate TruePDFDocument970 paginiInfectologia Kumate TruePDFEstefania Van der Vazcom90% (81)
- Biologia Celular 1 (2016)Document42 paginiBiologia Celular 1 (2016)Keila AyumiÎncă nu există evaluări
- Biologia Celular 2 (2016)Document39 paginiBiologia Celular 2 (2016)Melissa LuTiÎncă nu există evaluări
- 1139 6862 1 PBDocument7 pagini1139 6862 1 PBMelissa LuTiÎncă nu există evaluări
- The Midnight StarDocument202 paginiThe Midnight StarLuna RamirezÎncă nu există evaluări
- 10 Ciclo y División CelularesDocument7 pagini10 Ciclo y División CelularesjuanmezavillanuevaÎncă nu există evaluări
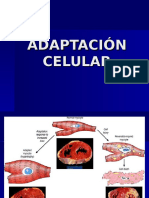
- Adapt Ac Ion CelularDocument80 paginiAdapt Ac Ion CelularDavicii Luque PacompiaÎncă nu există evaluări
- Ciclo Celular PDFDocument78 paginiCiclo Celular PDFGonzalo MunÎncă nu există evaluări
- Six of Crows The Dregs PDFDocument532 paginiSix of Crows The Dregs PDFShemihaza75% (8)
- 10-Procesos Genéticos de La Síntesis de Proteínas-La TraducciónDocument9 pagini10-Procesos Genéticos de La Síntesis de Proteínas-La TraducciónAlmudena MeiÎncă nu există evaluări
- (The Young Elites #1) - M LDocument232 pagini(The Young Elites #1) - M Lmarillo23100% (2)
- Procesos Genéticos de La Síntesis de Proteínas-La TraducciónDocument596 paginiProcesos Genéticos de La Síntesis de Proteínas-La TraducciónMelissa LuTiÎncă nu există evaluări
- 16 TraduccionDocument11 pagini16 TraduccionMaria FernandaÎncă nu există evaluări
- Ciencia - Atlas Tematico de Anatomia Humana PDFDocument48 paginiCiencia - Atlas Tematico de Anatomia Humana PDFkassan4791Încă nu există evaluări
- LibroBlanco PDFDocument110 paginiLibroBlanco PDFJacky OchoaÎncă nu există evaluări
- 113 Met de CarbohidratosDocument101 pagini113 Met de CarbohidratosJorge SánchezÎncă nu există evaluări
- Bioquimica Medica Tomo IV - Cardellá PDFDocument352 paginiBioquimica Medica Tomo IV - Cardellá PDFLuis Mari100% (1)
- Tabla de Distribucion Normal Estandar Z Cola InferiorDocument2 paginiTabla de Distribucion Normal Estandar Z Cola Inferiorarss1973Încă nu există evaluări
- VARIABLE ALEATORIA (Ejercicios)Document2 paginiVARIABLE ALEATORIA (Ejercicios)Omar DjarinÎncă nu există evaluări
- Estadística PCDocument2 paginiEstadística PCGianfranco LeonÎncă nu există evaluări
- Taller Distribucion Hipergeometrica y PoissonDocument8 paginiTaller Distribucion Hipergeometrica y PoissonNeider Yesid CabreraÎncă nu există evaluări
- Practica Parcial 3Document8 paginiPractica Parcial 3Dimar Villarroel R100% (1)
- Calculo Tpda Aforo Julio Moreno - Las JuntasDocument7 paginiCalculo Tpda Aforo Julio Moreno - Las JuntasVictorCristianoMuñozÎncă nu există evaluări
- Regresion Lineal Con Info CualitativaDocument36 paginiRegresion Lineal Con Info CualitativaRaziel Hernández OlivaresÎncă nu există evaluări
- 0.2458 LitrosDocument2 pagini0.2458 LitrosLUIS DAVID ZU�IGA SOLISÎncă nu există evaluări
- Actividad de Prenizaje Estadistica Unidad 4Document7 paginiActividad de Prenizaje Estadistica Unidad 4Valentina RestrepoÎncă nu există evaluări
- 1 Practica Clase Correlación 2021 JDocument38 pagini1 Practica Clase Correlación 2021 Jl221010050Încă nu există evaluări
- Suavizacion Exponencial DobleDocument20 paginiSuavizacion Exponencial DobleluceroÎncă nu există evaluări
- FASE 4 Discusión PlantillaDocument75 paginiFASE 4 Discusión PlantillaDiego QuiinteroÎncă nu există evaluări
- 4.desviacion Media, Varianza y Desviacion TipicaDocument5 pagini4.desviacion Media, Varianza y Desviacion TipicaEnrique JavierÎncă nu există evaluări
- Nec 3Document5 paginiNec 3AlexDarioÎncă nu există evaluări
- 1.cadenas de MarkovDocument54 pagini1.cadenas de MarkovJordy Portuguez0% (1)
- Tarea 2 20-II PDFDocument3 paginiTarea 2 20-II PDFJoel Rubalcava GonzalezÎncă nu există evaluări
- Tdistcontinuas 1Document2 paginiTdistcontinuas 1Brayan AcostaÎncă nu există evaluări
- Variable Aleatoria y Distribuciones de ProbabilidadDocument42 paginiVariable Aleatoria y Distribuciones de ProbabilidadKevin Steeven Delgado MarinÎncă nu există evaluări
- Separata de EjerciciosDocument9 paginiSeparata de EjerciciosRichard Montalban SanchezÎncă nu există evaluări
- Error CuadraticoDocument1 paginăError CuadraticosigifredosaroÎncă nu există evaluări
- Guia de Aprendizaje Intervalos de Confianza PDFDocument18 paginiGuia de Aprendizaje Intervalos de Confianza PDFLaura MontielÎncă nu există evaluări
- Manual Ioii 2Document72 paginiManual Ioii 2Marina MarroquinÎncă nu există evaluări
- Muestreo Con y Sin ReposiciónDocument13 paginiMuestreo Con y Sin ReposiciónIsabel Mallma LópezÎncă nu există evaluări
- Distribuciones de Muestreo Parte 2Document17 paginiDistribuciones de Muestreo Parte 2Rol XevierÎncă nu există evaluări
- Icoe1065 - Econometria Efj 2020 - VespertinoDocument5 paginiIcoe1065 - Econometria Efj 2020 - VespertinoCesar MendezÎncă nu există evaluări
- Prueba de TukeyDocument46 paginiPrueba de TukeyCarlos PinoÎncă nu există evaluări
- Solución Ejercicios 53 PDFDocument8 paginiSolución Ejercicios 53 PDFJuan Felipe Moreno RodriguezÎncă nu există evaluări
- Ejercicio Match Pala Cami NDocument12 paginiEjercicio Match Pala Cami N111sinpar111Încă nu există evaluări
- Guia de Laboratorio de CC 2019Document25 paginiGuia de Laboratorio de CC 2019Adam TejadaÎncă nu există evaluări
- Act 2 U6..Document9 paginiAct 2 U6..Amaury Hernandez Medina50% (2)