S-ar putea să vă placă și
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- ABSTRACTDocument4 paginiABSTRACTsulthan_81Încă nu există evaluări
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- Distributed Technologies-Cycle Test 1 QuestionsDocument1 paginăDistributed Technologies-Cycle Test 1 Questionssulthan_81Încă nu există evaluări
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- Distributed Technologies-Cycle Test 1 QuestionsDocument1 paginăDistributed Technologies-Cycle Test 1 Questionssulthan_81Încă nu există evaluări
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Microsoft Word: Instructors: Connie Hutchison & Christopher MccoyDocument29 paginiMicrosoft Word: Instructors: Connie Hutchison & Christopher MccoystefanyÎncă nu există evaluări
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (894)
- Servlet - Returning Information Received From The ClientDocument7 paginiServlet - Returning Information Received From The Clientsulthan_81Încă nu există evaluări
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (399)
- Operating Systems For BcaDocument5 paginiOperating Systems For Bcasulthan_81Încă nu există evaluări
- ABSTRACTDocument4 paginiABSTRACTsulthan_81Încă nu există evaluări
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Servlet - Returning Information Received From The ClientDocument7 paginiServlet - Returning Information Received From The Clientsulthan_81Încă nu există evaluări
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Operating Systems For BcaDocument5 paginiOperating Systems For Bcasulthan_81Încă nu există evaluări
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (587)
- Server-Side Programming: Java ServletsDocument116 paginiServer-Side Programming: Java ServletsANMOL CHAUHANÎncă nu există evaluări
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (265)
- P16MCAE10Document2 paginiP16MCAE10sulthan_81Încă nu există evaluări
- Gridview ExerciseDocument6 paginiGridview Exercisesulthan_81Încă nu există evaluări
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (73)
- Gridview ExerciseDocument6 paginiGridview Exercisesulthan_81Încă nu există evaluări
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- HTML TutorialDocument41 paginiHTML Tutorialsulthan_81Încă nu există evaluări
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (344)
- Assessing the Impact of User Convergence Generalization on Telecom RecruitmentDocument21 paginiAssessing the Impact of User Convergence Generalization on Telecom Recruitmentsulthan_81Încă nu există evaluări
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- Configuration Verbunden Effort Conception With Autoevalution of Intellectual Running ON Data Processor of The Sun TrackerDocument23 paginiConfiguration Verbunden Effort Conception With Autoevalution of Intellectual Running ON Data Processor of The Sun Trackersulthan_81Încă nu există evaluări
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
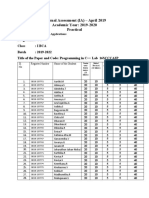
- Internal Assessment (IA) - April 2019 Academic Year: 2019-2020 PracticalDocument2 paginiInternal Assessment (IA) - April 2019 Academic Year: 2019-2020 Practicalsulthan_81Încă nu există evaluări
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2219)
- 4.gaussain MixtureDocument6 pagini4.gaussain Mixturesulthan_81Încă nu există evaluări
- HTML TutorialDocument39 paginiHTML Tutorialsulthan_81Încă nu există evaluări
- HTML TutorialDocument39 paginiHTML Tutorialsulthan_81Încă nu există evaluări
- Server-Side Programming: Java ServletsDocument116 paginiServer-Side Programming: Java ServletsANMOL CHAUHANÎncă nu există evaluări
- HTML NotesDocument56 paginiHTML NotesDhanasri0% (1)
- R.Punitha Research ScholarDocument18 paginiR.Punitha Research Scholarsulthan_81Încă nu există evaluări
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- HTML NotesDocument56 paginiHTML NotesDhanasri0% (1)
- 4.instance Based LearningDocument6 pagini4.instance Based Learningsulthan_81Încă nu există evaluări
- An Adaptive Framework For Recommended Based Learning Management SystemDocument23 paginiAn Adaptive Framework For Recommended Based Learning Management Systemsulthan_81Încă nu există evaluări
- 4.gaussain MixtureDocument6 pagini4.gaussain Mixturesulthan_81Încă nu există evaluări
- Ts 102690v010201pDocument279 paginiTs 102690v010201psulthan_81Încă nu există evaluări
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (119)
- ETSI M2M (Mamppt)Document33 paginiETSI M2M (Mamppt)sulthan_81Încă nu există evaluări
- Final Demo ICT Semi-Detailed Lesson PlanDocument6 paginiFinal Demo ICT Semi-Detailed Lesson PlanJo Stream80% (45)
- Grocery Inventory Management ProgramDocument16 paginiGrocery Inventory Management ProgramDeepakKattimaniÎncă nu există evaluări
- Lab 8 - PWMDocument4 paginiLab 8 - PWMlol100% (1)
- RBE2 ExerciseDocument24 paginiRBE2 Exercisejvo917Încă nu există evaluări
- MediNotes Conversion Steps For VARsDocument9 paginiMediNotes Conversion Steps For VARsMikeÎncă nu există evaluări
- EE 2310 Homework #3 Solutions - Flip Flops and Flip-Flop CircuitsDocument4 paginiEE 2310 Homework #3 Solutions - Flip Flops and Flip-Flop CircuitsJaffer RazaÎncă nu există evaluări
- ENUS211-078 IBM Print Transform From AFPDocument13 paginiENUS211-078 IBM Print Transform From AFPAnonymous c1oc6LeRÎncă nu există evaluări
- Why ADO.NET Addresses Database ProblemsDocument2 paginiWhy ADO.NET Addresses Database ProblemssandysirÎncă nu există evaluări
- Create Project Records in NetSuite with 40 StepsDocument5 paginiCreate Project Records in NetSuite with 40 StepsSatish Prabhakar DokeÎncă nu există evaluări
- Texto de Algebra Lineal U de Harvard PDFDocument47 paginiTexto de Algebra Lineal U de Harvard PDFJohn J Gomes EsquivelÎncă nu există evaluări
- ME9F DocumentDocument8 paginiME9F DocumentSagnik ChakravartyÎncă nu există evaluări
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- Basic Model Behavior With StellaDocument5 paginiBasic Model Behavior With StellaLenin Bullon VillanesÎncă nu există evaluări
- Content:: Galileo Reissue/ExchangeDocument10 paginiContent:: Galileo Reissue/ExchangeNeomi SaneÎncă nu există evaluări
- "Customer Relationship Management in ICICI Bank": A Study OnDocument6 pagini"Customer Relationship Management in ICICI Bank": A Study OnMubeenÎncă nu există evaluări
- MicroLog and MicroLog PRO User Guide 1E 1PDocument145 paginiMicroLog and MicroLog PRO User Guide 1E 1PDaniel Taiti KimathiÎncă nu există evaluări
- Computer Science-Class-Xii-Sample Question Paper-1Document12 paginiComputer Science-Class-Xii-Sample Question Paper-1rajeshÎncă nu există evaluări
- PLSQL Schema ERD and Table DesignsDocument8 paginiPLSQL Schema ERD and Table DesignsSoham GholapÎncă nu există evaluări
- QA Lead Interview QuestionsDocument11 paginiQA Lead Interview Questionsemail2raiÎncă nu există evaluări
- Referral and Record Keeping: Beringuel, Christian JosephDocument5 paginiReferral and Record Keeping: Beringuel, Christian JosephChristian Joseph Beringuel NietesÎncă nu există evaluări
- AG Robert HambrightDocument2 paginiAG Robert Hambrightrhambright2Încă nu există evaluări
- Transactional Licensing Comparison ChartDocument3 paginiTransactional Licensing Comparison Chartjonder2000Încă nu există evaluări
- Automotive Fuel Tank Sloshing AnalysisDocument34 paginiAutomotive Fuel Tank Sloshing AnalysisEdwin SpencerÎncă nu există evaluări
- TolAnalyst TutorialDocument15 paginiTolAnalyst TutorialAnton Nanchev100% (1)
- Linked List: Lab No. 3Document24 paginiLinked List: Lab No. 3Junaid SaleemÎncă nu există evaluări
- FEA Code in Matlab For A Truss StructureADocument33 paginiFEA Code in Matlab For A Truss StructureAiScribdRÎncă nu există evaluări
- Design-Patterns Cheat SheetDocument36 paginiDesign-Patterns Cheat SheetcesarmarinhorjÎncă nu există evaluări
- New Imsl ConfigurationDocument5 paginiNew Imsl Configurationsujayan2005Încă nu există evaluări
- Keypoints Algebra 1 ADocument3 paginiKeypoints Algebra 1 AtnezkiÎncă nu există evaluări
- Storage Classes in PL1Document12 paginiStorage Classes in PL1Shaswata Choudhury100% (1)
- Geometric SeriesDocument21 paginiGeometric SeriesRoszelan Majid50% (2)
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceDe la EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceEvaluare: 4 din 5 stele4/5 (2)
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldDe la EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldEvaluare: 4.5 din 5 stele4.5/5 (54)
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessDe la EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessÎncă nu există evaluări
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveDe la EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveÎncă nu există evaluări
- Generative AI: The Insights You Need from Harvard Business ReviewDe la EverandGenerative AI: The Insights You Need from Harvard Business ReviewEvaluare: 4.5 din 5 stele4.5/5 (2)
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)De la EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)Încă nu există evaluări
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesDe la EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesEvaluare: 4.5 din 5 stele4.5/5 (12)