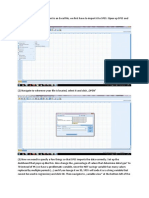
S-ar putea să vă placă și
- SPSS For PsychologistsDocument339 paginiSPSS For Psychologistsambiguous44100% (1)
- Econometrics For Dummies Cheat SheetDocument5 paginiEconometrics For Dummies Cheat SheetelhoumamyÎncă nu există evaluări
- Swift-Hackathon-2023 Briefing-Pack Vfinal 1707Document25 paginiSwift-Hackathon-2023 Briefing-Pack Vfinal 1707Navodye GunathilakaÎncă nu există evaluări
- Module 4 - Logistic Regression PDFDocument79 paginiModule 4 - Logistic Regression PDFKio ChopperÎncă nu există evaluări
- Let's Get Healthy! Statistics LessonDocument10 paginiLet's Get Healthy! Statistics LessonXeriosÎncă nu există evaluări
- BU1007 Report RoddyDocument19 paginiBU1007 Report Roddy陈文轩Încă nu există evaluări
- 301 ProjectDocument12 pagini301 ProjectGarrett KnappÎncă nu există evaluări
- Logit Model PDFDocument50 paginiLogit Model PDFNeha KumariÎncă nu există evaluări
- Econometrics Assignment.Document0 paginiEconometrics Assignment.Naveen BharathiÎncă nu există evaluări
- Rquestions Sol PDFDocument6 paginiRquestions Sol PDFDwi Sagitta100% (1)
- Effect Size GuideDocument7 paginiEffect Size GuideLucio GutierrezÎncă nu există evaluări
- Computing The Pearson Correlation CoefficientDocument38 paginiComputing The Pearson Correlation CoefficientJen ApinadoÎncă nu există evaluări
- Correlation and Regression Feb2014Document50 paginiCorrelation and Regression Feb2014Zeinab Goda100% (1)
- SPSS ProjectDocument12 paginiSPSS ProjectRishabh Sethi0% (1)
- On Final Requirement (Ten Statistical Techniques) - Donnie Marie PlazaDocument19 paginiOn Final Requirement (Ten Statistical Techniques) - Donnie Marie PlazaDonnie Marie PlazaÎncă nu există evaluări
- Hello JudyDocument3 paginiHello Judyapi-305512799Încă nu există evaluări
- OLS RegressionDocument24 paginiOLS RegressionMarkWeberÎncă nu există evaluări
- Knight y Sabot (1983) Educational Expansion and The Kuznets EffectDocument6 paginiKnight y Sabot (1983) Educational Expansion and The Kuznets EffectMargalida MLÎncă nu există evaluări
- Applied Econometrics For Managers (MBAA-II, AY: 2023-24) IIM KashipurDocument3 paginiApplied Econometrics For Managers (MBAA-II, AY: 2023-24) IIM KashipurSHAMBHAVI GUPTAÎncă nu există evaluări
- SSRN Id3719762Document92 paginiSSRN Id3719762Aldemar RacedoÎncă nu există evaluări
- Correlations - QuizDocument7 paginiCorrelations - QuizChinmayee ParchureÎncă nu există evaluări
- PN 24833 SolutionsDocument12 paginiPN 24833 SolutionsSastry75Încă nu există evaluări
- Encyclopedia of Research Design-Multiple RegressionDocument13 paginiEncyclopedia of Research Design-Multiple RegressionscottleeyÎncă nu există evaluări
- Bayesian Estimation ThesisDocument6 paginiBayesian Estimation Thesiskarenwashingtonbuffalo100% (2)
- Unit 3 FodDocument18 paginiUnit 3 FodkarthickamsecÎncă nu există evaluări
- Correlation and RegressionDocument11 paginiCorrelation and RegressiongdayanandamÎncă nu există evaluări
- Intermediate AnalysisDocument97 paginiIntermediate Analysislakshminivas PingaliÎncă nu există evaluări
- Chapter 7 Part 3Document18 paginiChapter 7 Part 3api-232613595Încă nu există evaluări
- Lab 4 Does More Money Result in Better SAT Scores?: The DataDocument8 paginiLab 4 Does More Money Result in Better SAT Scores?: The DataAdalberto Vladímir Palomares RamosÎncă nu există evaluări
- Statistics SPSS ProjectDocument12 paginiStatistics SPSS Projectrishabhsethi1990Încă nu există evaluări
- Quantitative Analysis in Social Sciences: An Brief Introduction For Non-EconomistsDocument26 paginiQuantitative Analysis in Social Sciences: An Brief Introduction For Non-EconomistsMiguel Nino-ZarazuaÎncă nu există evaluări
- Branches of Statistics, Data Types, and GraphsDocument6 paginiBranches of Statistics, Data Types, and Graphsmusicoustic1Încă nu există evaluări
- Quantile RegressionDocument11 paginiQuantile RegressionOvidiu RotariuÎncă nu există evaluări
- Module 5 Ge 114Document15 paginiModule 5 Ge 114frederick liponÎncă nu există evaluări
- College of Economics and Social Sciences Tutorial 2Document4 paginiCollege of Economics and Social Sciences Tutorial 2khairul amirÎncă nu există evaluări
- Here Is The Table of The Sample of 24 Cases For Students, It Is Categorized According To Age, Exam Marks, Paper Marks, Sex, Years in College, and IQDocument5 paginiHere Is The Table of The Sample of 24 Cases For Students, It Is Categorized According To Age, Exam Marks, Paper Marks, Sex, Years in College, and IQAcua RioÎncă nu există evaluări
- Applied Econometrics - Compulsory Assignment Hand-INDocument7 paginiApplied Econometrics - Compulsory Assignment Hand-INLars TonnÎncă nu există evaluări
- Sample Questions: EXAM 2Document6 paginiSample Questions: EXAM 2Pulkit PrajapatiÎncă nu există evaluări
- Categorical Data AnalysisDocument20 paginiCategorical Data AnalysisWanChainkeinÎncă nu există evaluări
- Regression TutorialDocument5 paginiRegression TutorialBálint L'Obasso TóthÎncă nu există evaluări
- Logit Model For Binary DataDocument50 paginiLogit Model For Binary Datasoumitra2377Încă nu există evaluări
- Data Driven DecisionsDocument5 paginiData Driven DecisionsaÎncă nu există evaluări
- Does Eye Color Depend On Gender? It Might Depend On Who or How You AskDocument11 paginiDoes Eye Color Depend On Gender? It Might Depend On Who or How You AskAkhmadRidhoAshariansyahÎncă nu există evaluări
- hw2 Answer Econ120c Su05 PDFDocument4 paginihw2 Answer Econ120c Su05 PDF6doitÎncă nu există evaluări
- Econometrics LecturesDocument22 paginiEconometrics LecturesFarhan ShariarÎncă nu există evaluări
- Regression After Midterm 5Document80 paginiRegression After Midterm 5NataliAmiranashviliÎncă nu există evaluări
- Activity in Basic StatDocument5 paginiActivity in Basic StatJean LeysonÎncă nu există evaluări
- QQQDocument44 paginiQQQmkooty zabaryÎncă nu există evaluări
- Correlation and RegressionDocument100 paginiCorrelation and Regressionssckp86100% (1)
- QRM Assign 6Document4 paginiQRM Assign 6neverendingwatchlistÎncă nu există evaluări
- MariaLiza F224RegressionandCorrelationDocument51 paginiMariaLiza F224RegressionandCorrelationMaria Liza Toring-FarquerabaoÎncă nu există evaluări
- CU ASwR Lab12 SolDocument6 paginiCU ASwR Lab12 Soltabesadze23Încă nu există evaluări
- ECN224 Topic1Document20 paginiECN224 Topic1Bruno LanzerÎncă nu există evaluări
- The Cost of College Tuition in The U.S. For The 2018-2019 School YearDocument11 paginiThe Cost of College Tuition in The U.S. For The 2018-2019 School Yearapi-706911799Încă nu există evaluări
- STD, Mean, Median, ModeDocument4 paginiSTD, Mean, Median, ModeMohamed AdelÎncă nu există evaluări
- MMM15 Part 3 - Moderation PDFDocument20 paginiMMM15 Part 3 - Moderation PDFSana JavaidÎncă nu există evaluări
- 7 Logistic Mark Tranmer, M.elliotDocument43 pagini7 Logistic Mark Tranmer, M.elliotkenzimahfiÎncă nu există evaluări
- Research Paper Using Correlational MethodDocument6 paginiResearch Paper Using Correlational Methodgatewivojez3100% (1)
- Chapter 3Document14 paginiChapter 3uzznÎncă nu există evaluări
- Flight Price Prediction ReportDocument18 paginiFlight Price Prediction ReportYashvardhanÎncă nu există evaluări
- 2018 Text Mining For Plagiarism Detection - Multivariate Pattern Detection For Recognition of Text Similarities PDFDocument8 pagini2018 Text Mining For Plagiarism Detection - Multivariate Pattern Detection For Recognition of Text Similarities PDFSagar KulkarniÎncă nu există evaluări
- QTTM509 Research Methodology-I: Dr. Tawheed NabiDocument32 paginiQTTM509 Research Methodology-I: Dr. Tawheed Nabimalibabu .gembaliÎncă nu există evaluări
- 13.machine Learning Axioms-CompletedDocument8 pagini13.machine Learning Axioms-CompletedSakshi SinghÎncă nu există evaluări
- Balance ScorecardDocument21 paginiBalance Scorecardfixs2002100% (1)
- Outline For ASM2Document4 paginiOutline For ASM2Trần Thị Quỳnh NhưÎncă nu există evaluări
- Topic Modeling: Latent Semantic Analysis For The Social SciencesDocument15 paginiTopic Modeling: Latent Semantic Analysis For The Social SciencesDeep GhoseÎncă nu există evaluări
- Advanced Composition S4 G3Document10 paginiAdvanced Composition S4 G3Simo SimoÎncă nu există evaluări
- Introduction To Machine Learning - IITM - CourseDocument1 paginăIntroduction To Machine Learning - IITM - CourseMuthukumar Ramkumar MuthukumarÎncă nu există evaluări
- Machine Learning - An Algorithmic Perspective (2nd Ed.) (Marsland 2014-10-08)Document15 paginiMachine Learning - An Algorithmic Perspective (2nd Ed.) (Marsland 2014-10-08)Orwell HUxleyÎncă nu există evaluări
- The Observational Gait Scale Can Help Determine The GMFCS Level in Children With Cerebral PalsyDocument4 paginiThe Observational Gait Scale Can Help Determine The GMFCS Level in Children With Cerebral PalsyASD2019Încă nu există evaluări
- ReworkDocument3 paginiReworkMohammad Rayhan Kim Abdul SalamÎncă nu există evaluări
- Questions With AnswerDocument6 paginiQuestions With AnswerSadÎncă nu există evaluări
- Significant Affects of Internet Addiction To The Academic Performance of The First Year Bachelor of Science in Accountancy Students of Colegio de San Gabriel Arcangel First Semester 2019Document17 paginiSignificant Affects of Internet Addiction To The Academic Performance of The First Year Bachelor of Science in Accountancy Students of Colegio de San Gabriel Arcangel First Semester 2019hazel alvarezÎncă nu există evaluări
- Example of Presentation of Data in Research PaperDocument8 paginiExample of Presentation of Data in Research PaperoqphebaodÎncă nu există evaluări
- Synopsis PrintDocument4 paginiSynopsis PrintRuchika khekareÎncă nu există evaluări
- Humor and Camera View On Mobile Short-Form Video Apps Influence User Experience and Technology-Adoption Intent, ..Document10 paginiHumor and Camera View On Mobile Short-Form Video Apps Influence User Experience and Technology-Adoption Intent, ..Thanh VoÎncă nu există evaluări
- Spss Mba WiwikDocument17 paginiSpss Mba Wiwikanna carollineÎncă nu există evaluări
- Academic Performance Rating Scale PDFDocument17 paginiAcademic Performance Rating Scale PDFJoshua TuguinayÎncă nu există evaluări
- Sprocket Central Pty LTD: Data Analytics ApproachDocument2 paginiSprocket Central Pty LTD: Data Analytics ApproachPragya Singh BaghelÎncă nu există evaluări
- Module 1 - Introduction To Data ScienceDocument59 paginiModule 1 - Introduction To Data ScienceRaushan Kashyap100% (1)
- Clustering Menggunakan Metode K-Means Untuk Menentukan Status Gizi BalitaDocument18 paginiClustering Menggunakan Metode K-Means Untuk Menentukan Status Gizi BalitaAji LaksonoÎncă nu există evaluări
- Statistical Soup - ANOVA, ANCOVA, MANOVA, & MANCOVADocument1 paginăStatistical Soup - ANOVA, ANCOVA, MANOVA, & MANCOVAsapaÎncă nu există evaluări
- Masters Degree in Social EngineeringDocument9 paginiMasters Degree in Social Engineeringepthompson0% (1)
- Pearson's CorrelationDocument6 paginiPearson's Correlationanon_201933134Încă nu există evaluări
- A. Irimia Diéguez 2023 - TPBDocument23 paginiA. Irimia Diéguez 2023 - TPBakuntansi syariahÎncă nu există evaluări
- Measures of DispersionDocument28 paginiMeasures of DispersionMaria Jessa BruzaÎncă nu există evaluări
- Cpe 106 StatDocument5 paginiCpe 106 StatRiza PacaratÎncă nu există evaluări