S-ar putea să vă placă și
- EViews WorkshopDocument26 paginiEViews WorkshopIsuru WijerathneÎncă nu există evaluări
- Supply, Demand, and Equilibrium Excel Lab1Document2 paginiSupply, Demand, and Equilibrium Excel Lab1satish sÎncă nu există evaluări
- EViewsDocument9 paginiEViewsroger02Încă nu există evaluări
- Midterm PracticeDocument7 paginiMidterm PracticeDoshi VaibhavÎncă nu există evaluări
- Homework 3: Pine Street Capital (Part I) : I Introduction and InstructionsDocument4 paginiHomework 3: Pine Street Capital (Part I) : I Introduction and Instructionslevan1225Încă nu există evaluări
- LakshmiY 12110035 SolutionsDocument10 paginiLakshmiY 12110035 SolutionsLakshmi Harshitha YechuriÎncă nu există evaluări
- Group 05 - TiVo SegmentationDocument8 paginiGroup 05 - TiVo SegmentationManav AgarwalÎncă nu există evaluări
- Mattel Case PresentationDocument61 paginiMattel Case PresentationKristine Joy Razo100% (1)
- MADM In-Class QuizDocument11 paginiMADM In-Class QuizPiyush SharmaÎncă nu există evaluări
- Nucor CorporationDocument16 paginiNucor CorporationNicole Chenper ChengÎncă nu există evaluări
- Case 11-3Document5 paginiCase 11-3herrajohnÎncă nu există evaluări
- Sealed Air Case CommentsDocument5 paginiSealed Air Case CommentsChristopher Ward100% (1)
- EViews GuideDocument14 paginiEViews GuideAnisha Jaiswal100% (1)
- Eviews PDFDocument18 paginiEviews PDFaftab20Încă nu există evaluări
- EVIEWS Data LoadingDocument3 paginiEVIEWS Data LoadingYAHYA BIN SAINIÎncă nu există evaluări
- A Demonstration To Regression in EviewsDocument11 paginiA Demonstration To Regression in EviewsDANHOUNDO RÉMIÎncă nu există evaluări
- Eviews HandoutDocument16 paginiEviews HandoutNhut PhamÎncă nu există evaluări
- Introduction To Using SAS Enterprise Guide For Statistical AnalysisDocument19 paginiIntroduction To Using SAS Enterprise Guide For Statistical Analysislee7717Încă nu există evaluări
- 03 Statistik Deskriptif - EViewsDocument24 pagini03 Statistik Deskriptif - EViewssondakh.edu2Încă nu există evaluări
- Grafana Guide: Getting Started Dashboards ComponentsDocument20 paginiGrafana Guide: Getting Started Dashboards ComponentsBui Hoang GiangÎncă nu există evaluări
- EXCESS PROJECT RazaDocument9 paginiEXCESS PROJECT RazaHome PhoneÎncă nu există evaluări
- Read Me: Errata and Updated DocumentationDocument22 paginiRead Me: Errata and Updated DocumentationCesar MonterrosoÎncă nu există evaluări
- Working With Origin 7aDocument11 paginiWorking With Origin 7aSupolÎncă nu există evaluări
- Assignment - ACCESSDocument19 paginiAssignment - ACCESSTeyhaÎncă nu există evaluări
- Eviews - IntroductionDocument66 paginiEviews - IntroductionRon JasonÎncă nu există evaluări
- Reportmill Tutorial: Template Design BasicsDocument12 paginiReportmill Tutorial: Template Design BasicspalowanÎncă nu există evaluări
- Crunchit! 2.0 Quick Start Guide: Texas A&M UniversityDocument26 paginiCrunchit! 2.0 Quick Start Guide: Texas A&M UniversityJim KimÎncă nu există evaluări
- SPSS Step-by-Step Tutorial: Part 1Document50 paginiSPSS Step-by-Step Tutorial: Part 1Ram Krishn PandeyÎncă nu există evaluări
- Using Excell in SpssDocument14 paginiUsing Excell in SpssZaraQartikaÎncă nu există evaluări
- Exel 2016Document68 paginiExel 2016sowjanya100% (1)
- Power PivotDocument20 paginiPower PivotBrajeshÎncă nu există evaluări
- Basic Data Handling of EViewsDocument51 paginiBasic Data Handling of EViewsDANHOUNDO RÉMIÎncă nu există evaluări
- Marksheet & Database MakingDocument6 paginiMarksheet & Database MakingAbhijeet UpadhyayÎncă nu există evaluări
- Eviews Tutorial: Economic ForecastingDocument20 paginiEviews Tutorial: Economic ForecastingNgọcBỉÎncă nu există evaluări
- Tutorial - Microsoft Office Excel 2003: Contact Barclay Barrios (Barclay - Barrios@rutgers - Edu)Document11 paginiTutorial - Microsoft Office Excel 2003: Contact Barclay Barrios (Barclay - Barrios@rutgers - Edu)Athienz AndheezzÎncă nu există evaluări
- ExcelDocument11 paginiExcelSanjay KumarÎncă nu există evaluări
- SQL DeveloperDocument56 paginiSQL DeveloperDavid Donovan100% (1)
- Pivot Table: Organize The DataDocument2 paginiPivot Table: Organize The Datanikita bajpaiÎncă nu există evaluări
- Mba Unit5Document19 paginiMba Unit5balrampal500Încă nu există evaluări
- Introduction To Tableau - Pre-ReadDocument12 paginiIntroduction To Tableau - Pre-ReadBadazz doodÎncă nu există evaluări
- Microsoft Access 2010 HandoutDocument11 paginiMicrosoft Access 2010 HandoutElzein Amir ElzeinÎncă nu există evaluări
- Universidad Autónoma de Nuevo León Cideb: Microsoft ExcelDocument11 paginiUniversidad Autónoma de Nuevo León Cideb: Microsoft ExcelRubén NavarroÎncă nu există evaluări
- Getting Started With SPSSDocument8 paginiGetting Started With SPSSMoosa MuhammadhÎncă nu există evaluări
- Working With Origin 8.6Document11 paginiWorking With Origin 8.6Lakis TriantafillouÎncă nu există evaluări
- Tutorial Del Programa SciDAVisDocument35 paginiTutorial Del Programa SciDAVisHect FariÎncă nu există evaluări
- Access 2007: Queries and Reports: Learning GuideDocument28 paginiAccess 2007: Queries and Reports: Learning GuideMegha JainÎncă nu există evaluări
- Sum Data by Using A QueryDocument18 paginiSum Data by Using A Querytelecomstuffs7931Încă nu există evaluări
- Introduction To Microsoft AccessDocument20 paginiIntroduction To Microsoft AccessArnav BarmanÎncă nu există evaluări
- KogeoDocument9 paginiKogeoRamdan YassinÎncă nu există evaluări
- Comprehensive Meta Analysis Version 2 (Beta)Document68 paginiComprehensive Meta Analysis Version 2 (Beta)surbhi.meshramÎncă nu există evaluări
- Access Versus Excel: Official MS Access WebsiteDocument26 paginiAccess Versus Excel: Official MS Access WebsiteMihaela EllaÎncă nu există evaluări
- Spreadsheet (Excel) PDFDocument35 paginiSpreadsheet (Excel) PDFpooja guptaÎncă nu există evaluări
- DbSchema Forms and Reports TutorialDocument10 paginiDbSchema Forms and Reports TutorialAdmin PSC-119Încă nu există evaluări
- What Is Calc?: Computer & Internet Literacy Course Electronic SpreadsheetDocument33 paginiWhat Is Calc?: Computer & Internet Literacy Course Electronic SpreadsheetJohn Ryan Otacan MoralesÎncă nu există evaluări
- To Start Oracle FormsDocument39 paginiTo Start Oracle FormsDenfilÎncă nu există evaluări
- Exercise: 1 SPSS (Statistical Package For Social Sciences)Document43 paginiExercise: 1 SPSS (Statistical Package For Social Sciences)Karthi Keyan100% (1)
- PPD Pract-3Document8 paginiPPD Pract-3jayÎncă nu există evaluări
- Note - SPSS For Customer AnalysisDocument18 paginiNote - SPSS For Customer Analysisصالح الشبحيÎncă nu există evaluări
- Getting Started With Tableau PrepDocument3 paginiGetting Started With Tableau PrepmajujmathewÎncă nu există evaluări
- Lecture Sheet-Power QueryDocument17 paginiLecture Sheet-Power QueryRas AltÎncă nu există evaluări
- What Is Cultural HeritageDocument2 paginiWhat Is Cultural HeritagekistlerÎncă nu există evaluări
- The Non-Performing Loans: Some Bank-Level EvidencesDocument34 paginiThe Non-Performing Loans: Some Bank-Level EvidencesJORKOS1Încă nu există evaluări
- SPISANIJADocument1 paginăSPISANIJAJORKOS1Încă nu există evaluări
- The Non-Performing Loans: Some Bank-Level EvidencesDocument34 paginiThe Non-Performing Loans: Some Bank-Level EvidencesJORKOS1Încă nu există evaluări
- What Is Financial LeverageDocument2 paginiWhat Is Financial LeverageJORKOS1Încă nu există evaluări
- whc12 36com 19eDocument246 paginiwhc12 36com 19eJORKOS1Încă nu există evaluări
- 1 Da Se ProveritDocument14 pagini1 Da Se ProveritJORKOS1Încă nu există evaluări
- DESRIPCIJADocument1 paginăDESRIPCIJAJORKOS1Încă nu există evaluări
- HJHJHKNDocument49 paginiHJHJHKNJORKOS1Încă nu există evaluări
- 15 Godisnik 2019Document9 pagini15 Godisnik 2019JORKOS1Încă nu există evaluări
- SHADOW BANKINGsporedba Na Trudovi ElenaDocument1 paginăSHADOW BANKINGsporedba Na Trudovi ElenaJORKOS1Încă nu există evaluări
- GGGGGDocument6 paginiGGGGGJORKOS1Încă nu există evaluări
- Ofi GDPG Money Bankgdp Penetra Penzija Short Stock Spread Fdi Dum Dum1Document2 paginiOfi GDPG Money Bankgdp Penetra Penzija Short Stock Spread Fdi Dum Dum1JORKOS1Încă nu există evaluări
- TtatataDocument1 paginăTtatataJORKOS1Încă nu există evaluări
- IJCEE5 Paper 3Document21 paginiIJCEE5 Paper 3JORKOS1Încă nu există evaluări
- GGGDocument28 paginiGGGJORKOS1Încă nu există evaluări
- Bulletin of Economic ResearchDocument1 paginăBulletin of Economic ResearchJORKOS1Încă nu există evaluări
- Bulletin of Economic ResearchDocument1 paginăBulletin of Economic ResearchJORKOS1Încă nu există evaluări
- 2Document1 pagină2JORKOS1Încă nu există evaluări
- StatementDocument1 paginăStatementJORKOS1Încă nu există evaluări
- 15 Godisnik 2019Document9 pagini15 Godisnik 2019JORKOS1Încă nu există evaluări
- KosovoDocument5 paginiKosovoJORKOS1Încă nu există evaluări
- GDPG CGD Trade PG Inf FdiDocument7 paginiGDPG CGD Trade PG Inf FdiJORKOS1Încă nu există evaluări
- For Peer Review Only: Macroeconomic and Bank-Specific Determinants of Non-Performing Loans: The Case of Baltic StatesDocument29 paginiFor Peer Review Only: Macroeconomic and Bank-Specific Determinants of Non-Performing Loans: The Case of Baltic StatesJORKOS1Încă nu există evaluări
- Non Performing Loans in Baltic States Determinants and Macroeconomic EffectsDocument21 paginiNon Performing Loans in Baltic States Determinants and Macroeconomic EffectsJORKOS1Încă nu există evaluări
- The Stability of Long-Run Money Demand in WesternDocument10 paginiThe Stability of Long-Run Money Demand in WesternJORKOS1Încă nu există evaluări
- Determinants of Nonperforming Loans in Central, Eastern and Southeastern EuropeDocument19 paginiDeterminants of Nonperforming Loans in Central, Eastern and Southeastern EuropeSonal TiwariÎncă nu există evaluări
- Makroekonomski VarijabliDocument8 paginiMakroekonomski VarijabliJORKOS1Încă nu există evaluări
- Urnek Za EmpirijaDocument191 paginiUrnek Za EmpirijaJORKOS1Încă nu există evaluări
- STAT1008 AssignmentDocument10 paginiSTAT1008 AssignmentTerence ChiemÎncă nu există evaluări
- Rouder2016 Article ModelComparisonInANOVADocument8 paginiRouder2016 Article ModelComparisonInANOVASpeachel RexxÎncă nu există evaluări
- BSC-301 - Probability - Distribution 3Document8 paginiBSC-301 - Probability - Distribution 3Precisive OneÎncă nu există evaluări
- Practical Research 2 Quarter 4 Module 7Document3 paginiPractical Research 2 Quarter 4 Module 7alexis balmoresÎncă nu există evaluări
- LESSON 2 - Testing Difference of Two MeansDocument56 paginiLESSON 2 - Testing Difference of Two MeansIzzy Dynielle SolamilloÎncă nu există evaluări
- CNHP 6000 Final Exam Study GuideDocument1 paginăCNHP 6000 Final Exam Study Guideulka07Încă nu există evaluări
- AP Statistics - Chapter 7 Notes: Sampling Distributions 7.1 - What Is A Sampling Distribution?Document1 paginăAP Statistics - Chapter 7 Notes: Sampling Distributions 7.1 - What Is A Sampling Distribution?kunichiwaÎncă nu există evaluări
- Effects of A Neurodevelopmental Treatment Based.3Document13 paginiEffects of A Neurodevelopmental Treatment Based.3ivairmatiasÎncă nu există evaluări
- Housing Prices Observation Price ($000) Square Feet Price ($000) Error Bedrooms Bathrooms Actual Forecasted (Residual)Document31 paginiHousing Prices Observation Price ($000) Square Feet Price ($000) Error Bedrooms Bathrooms Actual Forecasted (Residual)jodi setya pratamaÎncă nu există evaluări
- Unit-17 IGNOU STATISTICSDocument15 paginiUnit-17 IGNOU STATISTICSCarbidemanÎncă nu există evaluări
- Assignment QuestionsDocument5 paginiAssignment QuestionsAmitabh Bhattacharjee0% (2)
- Stat Chapter 5-9Document32 paginiStat Chapter 5-9asratÎncă nu există evaluări
- Keys To Successful Project Selection: Inputs OutputsDocument1 paginăKeys To Successful Project Selection: Inputs OutputsOscar D LeónÎncă nu există evaluări
- MAST20005/MAST90058: Assignment 1Document2 paginiMAST20005/MAST90058: Assignment 1Adam MasterÎncă nu există evaluări
- Perhitungan Regresi Dengan Excell Secara ManualDocument7 paginiPerhitungan Regresi Dengan Excell Secara Manualnaning mekawatiÎncă nu există evaluări
- Methods For Identifying Out-of-Trend Results in Ongoing Stability DataDocument5 paginiMethods For Identifying Out-of-Trend Results in Ongoing Stability DataBlueSagaÎncă nu există evaluări
- Segundo Examen - 172564Document22 paginiSegundo Examen - 172564Tere JUÁREZÎncă nu există evaluări
- Biostatistics Take Home ExaminationDocument9 paginiBiostatistics Take Home ExaminationUsran Ali BubinÎncă nu există evaluări
- Omitted Variable Bias: The Simple CaseDocument8 paginiOmitted Variable Bias: The Simple CasecjÎncă nu există evaluări
- Test of Significance-The Chi-SquareDocument22 paginiTest of Significance-The Chi-SquareKolawole Adesina KehindeÎncă nu există evaluări
- GridDataReport-Surfer 13Document10 paginiGridDataReport-Surfer 13Pre SheetÎncă nu există evaluări
- Factorial Experiment Two-Way ANOVA: Data Layout: Simultaneous ConclusionsDocument6 paginiFactorial Experiment Two-Way ANOVA: Data Layout: Simultaneous ConclusionsMamtha KumarÎncă nu există evaluări
- Two-Way Anova InteractionDocument9 paginiTwo-Way Anova InteractionImane ChatouiÎncă nu există evaluări
- Prob-Stat - 222 FinalDocument41 paginiProb-Stat - 222 Finaluyen.ta1309Încă nu există evaluări
- Introduction To Statistical TheoryDocument5 paginiIntroduction To Statistical TheoryAhmad SattarÎncă nu există evaluări
- Emperical Measurement of PriceDocument5 paginiEmperical Measurement of PriceRica Joy CuraÎncă nu există evaluări
- Example of Powerpoint Presentation For Pre-Oral DefenseDocument9 paginiExample of Powerpoint Presentation For Pre-Oral Defenseapi-19424182588% (8)
- Shiela Marie Caña - Measures-Of-Variability - Nov.6, 2021Document3 paginiShiela Marie Caña - Measures-Of-Variability - Nov.6, 2021Shiela marie CanaÎncă nu există evaluări
- TRIAL STPM Mathematics M 2 (KEDAH) SMK KhirJohariDocument9 paginiTRIAL STPM Mathematics M 2 (KEDAH) SMK KhirJohariSKÎncă nu există evaluări
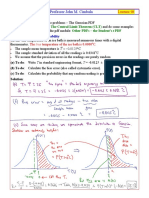
- ME345 Professor John M. Cimbala: The True Temperature of The Ice Bath Is 0.0000 CDocument4 paginiME345 Professor John M. Cimbala: The True Temperature of The Ice Bath Is 0.0000 Crahmid fareziÎncă nu există evaluări