S-ar putea să vă placă și
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe la EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeEvaluare: 4 din 5 stele4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe la EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreEvaluare: 4 din 5 stele4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe la EverandNever Split the Difference: Negotiating As If Your Life Depended On ItEvaluare: 4.5 din 5 stele4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe la EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceEvaluare: 4 din 5 stele4/5 (895)
- Grit: The Power of Passion and PerseveranceDe la EverandGrit: The Power of Passion and PerseveranceEvaluare: 4 din 5 stele4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDe la EverandShoe Dog: A Memoir by the Creator of NikeEvaluare: 4.5 din 5 stele4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe la EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersEvaluare: 4.5 din 5 stele4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe la EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureEvaluare: 4.5 din 5 stele4.5/5 (474)
- Her Body and Other Parties: StoriesDe la EverandHer Body and Other Parties: StoriesEvaluare: 4 din 5 stele4/5 (821)
- The Emperor of All Maladies: A Biography of CancerDe la EverandThe Emperor of All Maladies: A Biography of CancerEvaluare: 4.5 din 5 stele4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De la EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Evaluare: 4.5 din 5 stele4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe la EverandThe Little Book of Hygge: Danish Secrets to Happy LivingEvaluare: 3.5 din 5 stele3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe la EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyEvaluare: 3.5 din 5 stele3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)De la EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Evaluare: 4 din 5 stele4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe la EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaEvaluare: 4.5 din 5 stele4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe la EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryEvaluare: 3.5 din 5 stele3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDe la EverandTeam of Rivals: The Political Genius of Abraham LincolnEvaluare: 4.5 din 5 stele4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDe la EverandOn Fire: The (Burning) Case for a Green New DealEvaluare: 4 din 5 stele4/5 (74)
- 200 Series Service Manual FLX200 & SCR200Document39 pagini200 Series Service Manual FLX200 & SCR200Carlos Gomez100% (3)
- The Unwinding: An Inner History of the New AmericaDe la EverandThe Unwinding: An Inner History of the New AmericaEvaluare: 4 din 5 stele4/5 (45)
- 01 Cone Winding Study (Calculation)Document4 pagini01 Cone Winding Study (Calculation)Hasan Istiaque Ahmed60% (5)
- Tags Are Markers To Highlight Notable Revisions in TheDocument1 paginăTags Are Markers To Highlight Notable Revisions in TheMadan R HonnalagereÎncă nu există evaluări
- Certificate For True ForDocument1 paginăCertificate For True ForMadan R HonnalagereÎncă nu există evaluări
- ISO Awareness: Make It EasyDocument17 paginiISO Awareness: Make It EasyMadan R HonnalagereÎncă nu există evaluări
- Partnership Deed - AbcDocument7 paginiPartnership Deed - AbcMadan R HonnalagereÎncă nu există evaluări
- IETE-Journal of Research Template PDFDocument7 paginiIETE-Journal of Research Template PDFMadan R HonnalagereÎncă nu există evaluări
- Quality Manual Tarento - V2.2Document36 paginiQuality Manual Tarento - V2.2Madan R Honnalagere100% (1)
- Operational Manual: Operational Steps Involved To Fill Institute's Registration Form For AY 2019-20Document9 paginiOperational Manual: Operational Steps Involved To Fill Institute's Registration Form For AY 2019-20Madan R HonnalagereÎncă nu există evaluări
- Control of Management Reviews Procedure Sample PDFDocument4 paginiControl of Management Reviews Procedure Sample PDFMadan R HonnalagereÎncă nu există evaluări
- Certificate For Madan HR For - Check Your Awareness On PayscaleDocument1 paginăCertificate For Madan HR For - Check Your Awareness On PayscaleMadan R HonnalagereÎncă nu există evaluări
- Resume Dr. Sandeep MalikDocument1 paginăResume Dr. Sandeep MalikMadan R HonnalagereÎncă nu există evaluări
- How To Write An Author Bio & Why (With Examples)Document21 paginiHow To Write An Author Bio & Why (With Examples)Madan R HonnalagereÎncă nu există evaluări
- Project Plan For Implementation of The Quality Management SystemDocument4 paginiProject Plan For Implementation of The Quality Management SystemMadan R HonnalagereÎncă nu există evaluări
- Management Review: ISO 9001:2015 GuidanceDocument3 paginiManagement Review: ISO 9001:2015 GuidanceMadan R HonnalagereÎncă nu există evaluări
- ISO 9001-2015 V 2008 Correlation MatrixDocument10 paginiISO 9001-2015 V 2008 Correlation MatrixMadan R HonnalagereÎncă nu există evaluări
- Viewnet Diy PricelistDocument2 paginiViewnet Diy PricelistKhay SaadÎncă nu există evaluări
- Simple and Compound Gear TrainDocument2 paginiSimple and Compound Gear TrainHendri Yoga SaputraÎncă nu există evaluări
- RTE Online Application Form For Admission Year 2018 19Document6 paginiRTE Online Application Form For Admission Year 2018 19sudheer singhÎncă nu există evaluări
- F4 Search Help To Select More Than One Column ValueDocument4 paginiF4 Search Help To Select More Than One Column ValueRicky DasÎncă nu există evaluări
- Winter Internship Report (23/09/2016 - 31/01/2017)Document56 paginiWinter Internship Report (23/09/2016 - 31/01/2017)AyushÎncă nu există evaluări
- Qualcast 46cm Petrol Self Propelled Lawnmower: Assembly Manual XSZ46D-SDDocument28 paginiQualcast 46cm Petrol Self Propelled Lawnmower: Assembly Manual XSZ46D-SDmark simpsonÎncă nu există evaluări
- APP157 CoP For Site Supervision 2009 202109Document92 paginiAPP157 CoP For Site Supervision 2009 202109Alex LeungÎncă nu există evaluări
- .Preliminary PagesDocument12 pagini.Preliminary PagesKimBabÎncă nu există evaluări
- Cinegy User ManualDocument253 paginiCinegy User ManualNizamuddin KaziÎncă nu există evaluări
- Mitsubishi Electric Product OverviewDocument116 paginiMitsubishi Electric Product OverviewPepes HiuuÎncă nu există evaluări
- Owners Manuel SupplementDocument6 paginiOwners Manuel SupplementJohn HansenÎncă nu există evaluări
- Cooling Water BasicsDocument163 paginiCooling Water BasicsEduardo Castillo100% (1)
- CE 411 Lecture 03 - Moment AreaDocument27 paginiCE 411 Lecture 03 - Moment AreaNophiÎncă nu există evaluări
- Jun SMSDocument43 paginiJun SMSgallardo0121Încă nu există evaluări
- Cane - Sugar - Manufacture - in - India Datos Sobre Producción de AzucarDocument525 paginiCane - Sugar - Manufacture - in - India Datos Sobre Producción de AzucarEnrique Lucero100% (1)
- AK Carbon Steel PB 201307Document70 paginiAK Carbon Steel PB 201307SilveradoÎncă nu există evaluări
- University of Mumbai: Syllabus For Sem V & VI Program: B.Sc. Course: PhysicsDocument18 paginiUniversity of Mumbai: Syllabus For Sem V & VI Program: B.Sc. Course: Physicsdbhansali57Încă nu există evaluări
- Building 16 PrintDocument112 paginiBuilding 16 PrintNALEEMÎncă nu există evaluări
- ANSYS Mechanical Basic Structural NonlinearitiesDocument41 paginiANSYS Mechanical Basic Structural NonlinearitiesalexÎncă nu există evaluări
- JLG 600A 660AJ From Serial 0300177361 Service Manual (1) (1) Gabriel DSDDocument4 paginiJLG 600A 660AJ From Serial 0300177361 Service Manual (1) (1) Gabriel DSDCASAQUI LVAÎncă nu există evaluări
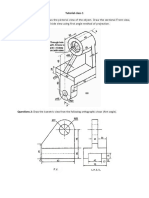
- Tutorial Class 1 Questions 1Document2 paginiTutorial Class 1 Questions 1Bố Quỳnh ChiÎncă nu există evaluări
- QAP For Conical StrainerDocument2 paginiQAP For Conical StrainersatishchidrewarÎncă nu există evaluări
- Exterity g44 Serie 1.2 ManualDocument87 paginiExterity g44 Serie 1.2 Manualruslan20851Încă nu există evaluări
- Bomba FlightDocument2 paginiBomba FlightGustavo HRÎncă nu există evaluări
- 1SDA066479R1 Rhe xt1 xt3 F P Stand ReturnedDocument3 pagini1SDA066479R1 Rhe xt1 xt3 F P Stand ReturnedAndrés Muñoz PeraltaÎncă nu există evaluări
- VX-1700 Owners ManualDocument32 paginiVX-1700 Owners ManualVan ThaoÎncă nu există evaluări
- GL 314Document2 paginiGL 314Vinayak SinghÎncă nu există evaluări
- Tectubi Raccordi Nuclear Ref ListDocument8 paginiTectubi Raccordi Nuclear Ref Listpomabe13Încă nu există evaluări