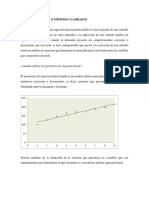
S-ar putea să vă placă și
- Microeconomía. Ideas fundamentales y Talleres de aplicaciónDe la EverandMicroeconomía. Ideas fundamentales y Talleres de aplicaciónEvaluare: 1.5 din 5 stele1.5/5 (2)
- Caso 01Document20 paginiCaso 01Brigitte Huaman Guevara0% (1)
- Metodos CausalesDocument18 paginiMetodos CausalesJuanCarlosVegaCharrisÎncă nu există evaluări
- CESIA - LANZA - U4T2a16Document6 paginiCESIA - LANZA - U4T2a16Juliany LanzaÎncă nu există evaluări
- Evidencia 3 Informe Análisis de Pertenencia de Técnicas ProyectivasDocument12 paginiEvidencia 3 Informe Análisis de Pertenencia de Técnicas ProyectivasLaura OrtizÎncă nu există evaluări
- 0 - Analisis Financiero Con RegresiónDocument14 pagini0 - Analisis Financiero Con RegresiónLuke SkywalkerÎncă nu există evaluări
- Tarea 2 - EconometríaDocument10 paginiTarea 2 - EconometríaFatima LuyandoÎncă nu există evaluări
- Gale Ebooks - Documento - Análisis de Correlación y de Regresión SimpleDocument23 paginiGale Ebooks - Documento - Análisis de Correlación y de Regresión SimpleArturo VelasquezÎncă nu există evaluări
- Regresión LinealDocument24 paginiRegresión LinealVEGA HUITRÓN ROMANÎncă nu există evaluări
- ESTADÍSTICA U2_20240313_185550_0000Document82 paginiESTADÍSTICA U2_20240313_185550_0000Clausen EspinosaÎncă nu există evaluări
- Análisis de Regresión MúltipleDocument16 paginiAnálisis de Regresión MúltipleJhonatan RomeroÎncă nu există evaluări
- Ejercicios para Parcial CompiladosDocument5 paginiEjercicios para Parcial CompiladosMis Cuatro MariasÎncă nu există evaluări
- 3ra Práctica CalificadaDocument9 pagini3ra Práctica CalificadaJoel ParcoÎncă nu există evaluări
- Trabajo EconometriaDocument7 paginiTrabajo EconometriaEvelyn Barril OyarzúnÎncă nu există evaluări
- Ma143 201501 Cuaderno de TrabajoDocument251 paginiMa143 201501 Cuaderno de TrabajoAna Tito NorabuenaÎncă nu există evaluări
- Sesión 4 - Laboratorio IVDocument34 paginiSesión 4 - Laboratorio IVBrenda LeonÎncă nu există evaluări
- Taller 4Document9 paginiTaller 4Carla Maria GOMEZ DOMINGUEZÎncă nu există evaluări
- TEORIADocument15 paginiTEORIAJäger CejaÎncă nu există evaluări
- Ejemplos Mixtos de Regresion LinealDocument35 paginiEjemplos Mixtos de Regresion LinealLuis Alejo HernandezÎncă nu există evaluări
- Clase Nº5 Regresion LinealDocument12 paginiClase Nº5 Regresion LinealBelen PizarroÎncă nu există evaluări
- Tema 3 CDocument19 paginiTema 3 CCindy VenturaÎncă nu există evaluări
- Regresión MúltipleDocument34 paginiRegresión MúltipleLuigi ItaloÎncă nu există evaluări
- Análisis de indicadores de accidentalidad mediante estadística descriptivaDocument14 paginiAnálisis de indicadores de accidentalidad mediante estadística descriptivaJhonatan Fernández RodríguezÎncă nu există evaluări
- PDF 11 Perbandingan Perhitungani Reaktor Isotermal Dan Non Isotermal Contoh Soal CompressDocument17 paginiPDF 11 Perbandingan Perhitungani Reaktor Isotermal Dan Non Isotermal Contoh Soal CompressMus D TaqimÎncă nu există evaluări
- Problem As Re Sueltos Stat Graphics CenturionDocument23 paginiProblem As Re Sueltos Stat Graphics CenturionPedro Walter Gamarra LeivaÎncă nu există evaluări
- Descubre Cómo Pronosticar La Demanda Con La Regresión LinealDocument1 paginăDescubre Cómo Pronosticar La Demanda Con La Regresión LinealJORGE MICHAEL MENDEZ FERNANDEZÎncă nu există evaluări
- Optimización MatemáticaDocument13 paginiOptimización MatemáticaEsteban HernándezÎncă nu există evaluări
- EstimacionDocument24 paginiEstimacionFRANK ALVIN GAMBOA YUCRAÎncă nu există evaluări
- Correlacion Series de Tiempo Distribucion Normal y ANOVA en Minitab 15Document76 paginiCorrelacion Series de Tiempo Distribucion Normal y ANOVA en Minitab 15ivanuntÎncă nu există evaluări
- Análisis Económico de Gastos y FactoresDocument14 paginiAnálisis Económico de Gastos y FactoresJavita ÁlvarezÎncă nu există evaluări
- Intervalos de ConfianzaDocument14 paginiIntervalos de ConfianzaKenin DominguezÎncă nu există evaluări
- Caso Practico EstadisticaDocument7 paginiCaso Practico EstadisticaLiceth GarciaÎncă nu există evaluări
- PC 120182 SolDocument7 paginiPC 120182 SolDante Víctor García MenesesÎncă nu există evaluări
- Aplicaciones de Vectores en La ContabilidadDocument10 paginiAplicaciones de Vectores en La ContabilidadCARLA100% (4)
- T1 - Act1 - Investigacion - German Jared Moreno BalamDocument10 paginiT1 - Act1 - Investigacion - German Jared Moreno Balamjared morenoÎncă nu există evaluări
- Reegresión LinealDocument6 paginiReegresión LinealjorgeejÎncă nu există evaluări
- Material de Estudio. Teoría de EstimaciónDocument11 paginiMaterial de Estudio. Teoría de EstimaciónNIETO ORTIZ DIEGO JOSUE ING. CIVILÎncă nu există evaluări
- Estimacion Puntual y Por Intervalo de ConfianzaDocument28 paginiEstimacion Puntual y Por Intervalo de ConfianzaJuan Jose SosaÎncă nu există evaluări
- Evaluación de Estadística UrpDocument4 paginiEvaluación de Estadística Urpcesar vasquez trejoÎncă nu există evaluări
- ROE EconometríaDocument14 paginiROE EconometríaJuanGuillermo Plaza SantibáñezÎncă nu există evaluări
- Taller VI Módulo ADocument22 paginiTaller VI Módulo AyamilevmdÎncă nu există evaluări
- TF EconometriaDocument12 paginiTF EconometriaNicole Urrutia RosazzaÎncă nu există evaluări
- Regresión Lineal: Un Modelo Estadístico Útil para Predecir Variables CuantitativasDocument63 paginiRegresión Lineal: Un Modelo Estadístico Útil para Predecir Variables CuantitativasCarlos LopezÎncă nu există evaluări
- EconometriaDocument8 paginiEconometriaCatalina Peralta RuizÎncă nu există evaluări
- Taller Teorico Regresion Lineal Demanda de PapaDocument12 paginiTaller Teorico Regresion Lineal Demanda de PapaAndres Felipe Mola PrensÎncă nu există evaluări
- Tarea de ProbabilidadDocument11 paginiTarea de ProbabilidadH. Albert ruizÎncă nu există evaluări
- PPDocument42 paginiPPKolya MayoÎncă nu există evaluări
- Parciales 2_removedDocument5 paginiParciales 2_removedLucia BofillÎncă nu există evaluări
- Practica Sobre Correlación y Regresión PDFDocument7 paginiPractica Sobre Correlación y Regresión PDFWinnyfer SanchezÎncă nu există evaluări
- Inferencia EstadisticaDocument7 paginiInferencia Estadisticaabra_jo100% (2)
- Hipótesis en El Modelo de Regresión Lineal Por Mínimos Cuadrados OrdinariosDocument8 paginiHipótesis en El Modelo de Regresión Lineal Por Mínimos Cuadrados OrdinariosLINA MONTEROÎncă nu există evaluări
- Proyección de La DemandaDocument6 paginiProyección de La DemandaLeonard Abella100% (1)
- Regresion Lineal RDocument10 paginiRegresion Lineal RjjÎncă nu există evaluări
- Finanzas Ii MetodosDocument19 paginiFinanzas Ii Metodosmaria joseÎncă nu există evaluări
- LapaDocument14 paginiLapaROCIO NATALY CARTOLIN PUREÎncă nu există evaluări
- Trabajo Practico Real FinalDocument6 paginiTrabajo Practico Real Final202204225Încă nu există evaluări
- Modelo regresión evaluar hospital AcapulcoDocument13 paginiModelo regresión evaluar hospital AcapulcoRafaelSalazarÎncă nu există evaluări
- Costos para gerenciar organizaciones manufactureras, comerciales y de servicios. Segunda EdiciónDe la EverandCostos para gerenciar organizaciones manufactureras, comerciales y de servicios. Segunda EdiciónEvaluare: 1 din 5 stele1/5 (1)
- Grupo N 4 Ratón Ergonómico Informe 1Document8 paginiGrupo N 4 Ratón Ergonómico Informe 1Milagros Sosa PurisacaÎncă nu există evaluări
- Layout 1 - Casas Neciosup Emerson Brayan PDFDocument1 paginăLayout 1 - Casas Neciosup Emerson Brayan PDFMilagros Sosa PurisacaÎncă nu există evaluări
- 1 Introduccion PDFDocument55 pagini1 Introduccion PDFMilagros Sosa PurisacaÎncă nu există evaluări
- Los Costes de Los Materiales y La Valoración de Los StockDocument28 paginiLos Costes de Los Materiales y La Valoración de Los StockDeibbys RamosÎncă nu există evaluări
- Sylabus de Sistemas Electricos y Electronicos 2019-IDocument11 paginiSylabus de Sistemas Electricos y Electronicos 2019-IMilagros Sosa PurisacaÎncă nu există evaluări
- Variable ComplejaDocument202 paginiVariable ComplejafinselnÎncă nu există evaluări
- Portada 1Document1 paginăPortada 1luis fernando llontop lluenÎncă nu există evaluări
- HKJDocument1 paginăHKJMilagros Sosa PurisacaÎncă nu există evaluări
- CorreoDocument12 paginiCorreoMilagros Sosa PurisacaÎncă nu există evaluări
- Los Costes de Los Materiales y La Valoración de Los StockDocument28 paginiLos Costes de Los Materiales y La Valoración de Los StockDeibbys RamosÎncă nu există evaluări
- Nuevo Documento de Microsoft WordDocument1 paginăNuevo Documento de Microsoft WordMilagros Sosa PurisacaÎncă nu există evaluări
- Branding GlosarioDocument1 paginăBranding GlosarioMilagros Sosa PurisacaÎncă nu există evaluări
- Métodos de Ordenamiento: Universidad Nacional Pedro Ruiz GalloDocument9 paginiMétodos de Ordenamiento: Universidad Nacional Pedro Ruiz GalloMilagros Sosa PurisacaÎncă nu există evaluări
- Modelo Caratula SistemasDocument1 paginăModelo Caratula SistemasMilagros Sosa PurisacaÎncă nu există evaluări
- Variable Compleja AcevedoDocument1 paginăVariable Compleja AcevedoMilagros Sosa PurisacaÎncă nu există evaluări
- Maximizar ganancias fabricando mueblesDocument33 paginiMaximizar ganancias fabricando mueblesjuanito_sexÎncă nu există evaluări
- Map 1Document3 paginiMap 1Milagros Sosa PurisacaÎncă nu există evaluări
- ContaDocument2 paginiContaMilagros Sosa PurisacaÎncă nu există evaluări
- Map 1Document7 paginiMap 1Milagros Sosa PurisacaÎncă nu există evaluări
- Algoritmos Díaz-Sandoval 2018 1Document5 paginiAlgoritmos Díaz-Sandoval 2018 1MJ JheimiÎncă nu există evaluări
- CARATULADocument1 paginăCARATULAMilagros Sosa PurisacaÎncă nu există evaluări
- Pérdida ContableDocument2 paginiPérdida ContableMilagros Sosa PurisacaÎncă nu există evaluări
- Map 1Document3 paginiMap 1Milagros Sosa PurisacaÎncă nu există evaluări
- NNDocument10 paginiNNMilagros Sosa PurisacaÎncă nu există evaluări
- Pérdida ContableDocument2 paginiPérdida ContableMilagros Sosa PurisacaÎncă nu există evaluări
- Ficha de SintesisDocument3 paginiFicha de SintesisMilagros Sosa PurisacaÎncă nu există evaluări
- Grupos EconomicosDocument40 paginiGrupos EconomicosMilagros Sosa PurisacaÎncă nu există evaluări
- Alg Lin Itig ApDocument203 paginiAlg Lin Itig Apmartin_rojas_97Încă nu există evaluări
- CarátulaDocument2 paginiCarátulaMilagros Sosa PurisacaÎncă nu există evaluări
- Guia 7 Regresion LinealDocument8 paginiGuia 7 Regresion LinealClaudioÎncă nu există evaluări
- REACTIVOSDocument8 paginiREACTIVOSSoy LessÎncă nu există evaluări
- Test de Comunicación OrganizacionalDocument2 paginiTest de Comunicación OrganizacionalNOELIA MILAGROS CONDO SILVA100% (1)
- Pruebas de HipóteisDocument1 paginăPruebas de Hipóteisjeani5508Încă nu există evaluări
- Norma Oficial Mexicana de ValuaciónDocument17 paginiNorma Oficial Mexicana de ValuaciónRita EscalanteÎncă nu există evaluări
- Informe de Flexión e ImpactoDocument8 paginiInforme de Flexión e ImpactoAlejandroÎncă nu există evaluări
- ¿Influyen Los Estilos Parentales y La de Los Padres en El Desarroollo de Los Hijos?Document15 pagini¿Influyen Los Estilos Parentales y La de Los Padres en El Desarroollo de Los Hijos?Diosinantzin García BucioÎncă nu există evaluări
- Comercialización y Ventas - General S4 TerceroDocument10 paginiComercialización y Ventas - General S4 TerceroLourdes VelezÎncă nu există evaluări
- Criminalistica - CuestionarioDocument3 paginiCriminalistica - CuestionarioArnold Juarez RoblesÎncă nu există evaluări
- Etapas de La Auditoria AdministrativaDocument19 paginiEtapas de La Auditoria Administrativacarmen100% (1)
- Estadistica Descriptiva Fase 4Document16 paginiEstadistica Descriptiva Fase 4johann roldan0% (1)
- Benchmarking y satisfacción del cliente en restaurante de AyacuchoDocument7 paginiBenchmarking y satisfacción del cliente en restaurante de AyacuchoKatherine Ivett Valdivia BendezuÎncă nu există evaluări
- Informe KPIDocument10 paginiInforme KPIMatias Ricardo Alarcon MolinaÎncă nu există evaluări
- Matos Jimenez Fanny e PDFDocument158 paginiMatos Jimenez Fanny e PDFalexis cuevasÎncă nu există evaluări
- Análisis técnicas e instrumentos evaluación procesos lecturaDocument7 paginiAnálisis técnicas e instrumentos evaluación procesos lecturabelyta23Încă nu există evaluări
- Tablas y Estadística. Introducción A Las EstadísticaDocument19 paginiTablas y Estadística. Introducción A Las EstadísticafernannmilenÎncă nu există evaluări
- El Empleo de Las Técnicas Proyectivas para El Estudio de La SubjetividadDocument2 paginiEl Empleo de Las Técnicas Proyectivas para El Estudio de La SubjetividadVictor Lizarme AllahuaÎncă nu există evaluări
- Guía Estadística DescriptivaDocument4 paginiGuía Estadística DescriptivaKarla P. ReyesÎncă nu există evaluări
- Sesión 05Document53 paginiSesión 05TatianaZambranoAlíÎncă nu există evaluări
- Proyecto de Investigación Tema 3 Estadística Inferencial I para IINDDocument3 paginiProyecto de Investigación Tema 3 Estadística Inferencial I para IINDalexÎncă nu există evaluări
- Medidas de seguridad y calidad en construcciónDocument4 paginiMedidas de seguridad y calidad en construcciónWilliams La TorreÎncă nu există evaluări
- Ejercicios ProbabilidadDocument7 paginiEjercicios ProbabilidadAlejandro MendozaÎncă nu există evaluări
- Riesgo Organizacional PDFDocument83 paginiRiesgo Organizacional PDFWalter Huayta ConisllaÎncă nu există evaluări
- Análisis de La Tenacidad A La Fractura y El Efecto Del Tamaño de Probeta para Un Acero Colado de Medio Carbono y Baja AleaciónDocument6 paginiAnálisis de La Tenacidad A La Fractura y El Efecto Del Tamaño de Probeta para Un Acero Colado de Medio Carbono y Baja AleaciónAlex AlcarazÎncă nu există evaluări
- 10.1 Gestión de No Conformidades, Acciones Correctivas y PreventivasDocument13 pagini10.1 Gestión de No Conformidades, Acciones Correctivas y PreventivasJulia100% (2)
- Muestreo de AlimentosDocument18 paginiMuestreo de AlimentosGerald EduardooÎncă nu există evaluări
- Auditoria de SistemasDocument10 paginiAuditoria de SistemasMaría Claudia RodriguezÎncă nu există evaluări
- Metodologías de investigación, tipos de estudio y recopilación de datosDocument11 paginiMetodologías de investigación, tipos de estudio y recopilación de datosApazacalle ApazacalleÎncă nu există evaluări
- Cuestionario Introducción A La Investigación Científica.Document21 paginiCuestionario Introducción A La Investigación Científica.Ana Karina Lima Garcia0% (1)
- Instrucciones Escala de Evitacion y Angustia SocialDocument4 paginiInstrucciones Escala de Evitacion y Angustia SocialMrToedeÎncă nu există evaluări