S-ar putea să vă placă și
- Ecology - Sampling TechniquesDocument25 paginiEcology - Sampling TechniquesRic Flamboyant FraserÎncă nu există evaluări
- Information On Mung BeansDocument7 paginiInformation On Mung BeansAuricio, Kent Margarrette B.Încă nu există evaluări
- ModeDocument18 paginiModeRishab Jain 2027203100% (1)
- Chi Squared TestDocument17 paginiChi Squared TestsanthiÎncă nu există evaluări
- Amylase A Sample EnzymeDocument10 paginiAmylase A Sample EnzymeJulioÎncă nu există evaluări
- Biostat Handouts Lesson 12 PDFDocument41 paginiBiostat Handouts Lesson 12 PDFheyyymeeeÎncă nu există evaluări
- Edexcel IAL Biology A Level 11: Core PracticalDocument13 paginiEdexcel IAL Biology A Level 11: Core PracticalSadika AkhterÎncă nu există evaluări
- Types of Research QuestionsDocument34 paginiTypes of Research QuestionsMuaz ShukorÎncă nu există evaluări
- Probability and Prob. DistributionDocument61 paginiProbability and Prob. DistributionAnonymous 2UXdOsq100% (1)
- StatisticsDocument10 paginiStatisticsSimone WeillÎncă nu există evaluări
- Grouping StudentsDocument13 paginiGrouping StudentsInggy Yuliani P , MPd.100% (4)
- Key Criteria For Medical AdmissionsDocument2 paginiKey Criteria For Medical Admissionsan7li721Încă nu există evaluări
- How Body Response To ExerciseDocument21 paginiHow Body Response To ExerciseTan SittanÎncă nu există evaluări
- Multiple Choice QuestionsDocument2 paginiMultiple Choice QuestionsJamie BirdÎncă nu există evaluări
- DILSHAD - Study DesignsDocument48 paginiDILSHAD - Study DesignsAamir IjazÎncă nu există evaluări
- Corelation and RegressionDocument5 paginiCorelation and RegressionN RamÎncă nu există evaluări
- The Evolution of Antibiotic Resistance in BacteriaDocument2 paginiThe Evolution of Antibiotic Resistance in Bacteriazz0% (1)
- Health DefinationDocument9 paginiHealth DefinationybadetiÎncă nu există evaluări
- Tests of Significance Notes PDFDocument12 paginiTests of Significance Notes PDFManish KÎncă nu există evaluări
- 8) Multilevel AnalysisDocument41 pagini8) Multilevel AnalysisMulusewÎncă nu există evaluări
- Yr 11 Renin Enzyme Practical Report - AbouDocument5 paginiYr 11 Renin Enzyme Practical Report - AbouAbou Sesay0% (1)
- CH 14Document13 paginiCH 14Manish MalikÎncă nu există evaluări
- QuestionnaireDocument31 paginiQuestionnairechanchalÎncă nu există evaluări
- Conventional Views of ReliabilityDocument43 paginiConventional Views of ReliabilityCART11Încă nu există evaluări
- Tabu Ran NormalDocument14 paginiTabu Ran NormalSylvia100% (1)
- Non Parametric TestDocument3 paginiNon Parametric TestPankaj2cÎncă nu există evaluări
- Correlational Research: Elisha Gay C. Hidalgo, RNDDocument14 paginiCorrelational Research: Elisha Gay C. Hidalgo, RNDinkpen56789Încă nu există evaluări
- Lab Report EnzymesDocument7 paginiLab Report Enzymesapi-254664546Încă nu există evaluări
- Measure of DispersionDocument64 paginiMeasure of DispersionMuhammad Atif SheikhÎncă nu există evaluări
- Answer Key To Sample AP-ExamDocument7 paginiAnswer Key To Sample AP-ExamldlewisÎncă nu există evaluări
- AddMath ProjectDocument28 paginiAddMath ProjectFirdaus Maligan67% (3)
- 2002 Multiple Choice SolutionsDocument25 pagini2002 Multiple Choice Solutionssmemisovski22Încă nu există evaluări
- Guidelines For Multiple Choice Questions MCQ S 4426Document19 paginiGuidelines For Multiple Choice Questions MCQ S 4426R RatheeshÎncă nu există evaluări
- Wilcoxon Signed-Ranks TestDocument16 paginiWilcoxon Signed-Ranks TestLayan MohammadÎncă nu există evaluări
- Different Types of Sampling DesignsDocument12 paginiDifferent Types of Sampling Designsshincepeterms100% (5)
- National 5 Biology TextbookDocument217 paginiNational 5 Biology Textbooks9dijdjiÎncă nu există evaluări
- Statistics Project Second SemesterDocument7 paginiStatistics Project Second SemesterTaegh S. SokheyÎncă nu există evaluări
- Measure of Dispersion StatisticsDocument24 paginiMeasure of Dispersion Statisticszeebee17Încă nu există evaluări
- 01 - 1probability of Simple EventsDocument20 pagini01 - 1probability of Simple EventsLaysa PalomarÎncă nu există evaluări
- Introduction To Multivariate Analysis: Dr. Ibrahim Awad IbrahimDocument36 paginiIntroduction To Multivariate Analysis: Dr. Ibrahim Awad IbrahimRohit kumarÎncă nu există evaluări
- Ch. 7 - Sampling and Infrential StatisticsDocument27 paginiCh. 7 - Sampling and Infrential StatisticsNour MohamedÎncă nu există evaluări
- Planning An Investigation Model Answers Five Complete Plans New RepairedDocument40 paginiPlanning An Investigation Model Answers Five Complete Plans New Repairedsafachy100% (2)
- MCQDocument70 paginiMCQJerry OktovaÎncă nu există evaluări
- Biases in Randomized Trials A Conversation Between Trialists and Epidemiologists.Document25 paginiBiases in Randomized Trials A Conversation Between Trialists and Epidemiologists.Oscar Alexander Gutiérrez-LesmesÎncă nu există evaluări
- Lectures On Biostatistics-Ocr4Document446 paginiLectures On Biostatistics-Ocr4Kostas GemenisÎncă nu există evaluări
- Thesis and Dissertation Evaluation Rubric FinalDocument9 paginiThesis and Dissertation Evaluation Rubric FinalHarry Lord M. BolinaÎncă nu există evaluări
- The Normal CurveDocument33 paginiThe Normal CurveRohan JambhulkarÎncă nu există evaluări
- File - Request For Approval - Ivy Skillern Elementary SchoolDocument12 paginiFile - Request For Approval - Ivy Skillern Elementary SchoolWTVCÎncă nu există evaluări
- Unit 1 Measurement and ErrorDocument41 paginiUnit 1 Measurement and Erroraini norÎncă nu există evaluări
- STAT Module 4Document10 paginiSTAT Module 4Jayson CabreraÎncă nu există evaluări
- The Interdependence of Philosophy and EducationDocument2 paginiThe Interdependence of Philosophy and EducationWella InfanteÎncă nu există evaluări
- NMAT Sample Paper PDFDocument28 paginiNMAT Sample Paper PDFFahad SiddiqueeÎncă nu există evaluări
- Stat Chapter 5-9Document32 paginiStat Chapter 5-9asratÎncă nu există evaluări
- Jmet Sample PaperDocument13 paginiJmet Sample PaperGaurang GroverÎncă nu există evaluări
- "Cannabinoids in The Treatment of Epilepsy" - New England Journal of MedicineDocument11 pagini"Cannabinoids in The Treatment of Epilepsy" - New England Journal of MedicineloomcÎncă nu există evaluări
- Effect of Salinity On Seed Germination, Growth and Organic Compounds of Mungbean Plant Vigna RadiataDocument10 paginiEffect of Salinity On Seed Germination, Growth and Organic Compounds of Mungbean Plant Vigna RadiatahunarsandhuÎncă nu există evaluări
- Norm - Referenced Tests & Criterion-Referenced TestsDocument13 paginiNorm - Referenced Tests & Criterion-Referenced TestsNeil Ang100% (2)
- Student's T-Test: History Uses Assumptions Unpaired and Paired Two-Sample T-TestsDocument13 paginiStudent's T-Test: History Uses Assumptions Unpaired and Paired Two-Sample T-TestsNTA UGC-NET100% (1)
- Student's T TestDocument56 paginiStudent's T TestmelprvnÎncă nu există evaluări
- Student's T-TestDocument11 paginiStudent's T-TestSanjay Lakhtariya100% (1)
- 2009-Dispersion Analysis of Spinning ProjectileDocument13 pagini2009-Dispersion Analysis of Spinning ProjectileZvonko TÎncă nu există evaluări
- 2009-Worst-Case and Statistical Tolerance Analysis Monte CarloDocument12 pagini2009-Worst-Case and Statistical Tolerance Analysis Monte CarloZvonko TÎncă nu există evaluări
- Sustainability 16 00340Document26 paginiSustainability 16 00340Zvonko TÎncă nu există evaluări
- 1062748.defence Resources Management and Capabilities BuildingDocument9 pagini1062748.defence Resources Management and Capabilities BuildingZvonko TÎncă nu există evaluări
- 1996-National Security Strategy of Engagement and Enlargement ClintonDocument49 pagini1996-National Security Strategy of Engagement and Enlargement ClintonZvonko TÎncă nu există evaluări
- 2006-Control Authority of A Projectile Equipped With An Internal Unbalanced PartDocument8 pagini2006-Control Authority of A Projectile Equipped With An Internal Unbalanced PartZvonko TÎncă nu există evaluări
- 1999-National Security Strategy New Century US ClintonDocument54 pagini1999-National Security Strategy New Century US ClintonZvonko TÎncă nu există evaluări
- The Student T Distribution and Its Use: James H. SteigerDocument36 paginiThe Student T Distribution and Its Use: James H. SteigerZvonko TÎncă nu există evaluări
- Gears Design With Shape Uncertainties Using Monte Carlo SimulationsDocument14 paginiGears Design With Shape Uncertainties Using Monte Carlo SimulationsZvonko TÎncă nu există evaluări
- The Structure of Positional Tolerance EvaluationDocument30 paginiThe Structure of Positional Tolerance EvaluationZvonko TÎncă nu există evaluări
- Correction Mechanism Analysis For Spin Stabilized ProjectilesDocument8 paginiCorrection Mechanism Analysis For Spin Stabilized ProjectilesZvonko TÎncă nu există evaluări
- Tolerance Analysis of Mechanical Assemblies With Asymmetric TolerancesDocument12 paginiTolerance Analysis of Mechanical Assemblies With Asymmetric TolerancesZvonko TÎncă nu există evaluări
- Tolerance Synthesis of Fastened Metal-Composite Joints Based On Probabilistic and Worst-Case ApproachesDocument13 paginiTolerance Synthesis of Fastened Metal-Composite Joints Based On Probabilistic and Worst-Case ApproachesZvonko TÎncă nu există evaluări
- Comparison of Explicit and Implicit Forms of The MPMMDocument13 paginiComparison of Explicit and Implicit Forms of The MPMMZvonko TÎncă nu există evaluări
- Construction: Construction Is A General Term Meaning The Art and Science To FormDocument13 paginiConstruction: Construction Is A General Term Meaning The Art and Science To FormZvonko TÎncă nu există evaluări
- Shipyard: History Historic Shipyards Prominent Dockyards and ShipyardsDocument11 paginiShipyard: History Historic Shipyards Prominent Dockyards and ShipyardsZvonko TÎncă nu există evaluări
- Boat Building: Boat Building Is The Design and Construction of Boats and TheirDocument13 paginiBoat Building: Boat Building Is The Design and Construction of Boats and TheirZvonko TÎncă nu există evaluări
- Comparative Study of Tolerance Analysis MethodsDocument6 paginiComparative Study of Tolerance Analysis MethodsZvonko TÎncă nu există evaluări
- Coordiante Systems Flight MechanicsDocument4 paginiCoordiante Systems Flight MechanicsZvonko TÎncă nu există evaluări
- Nomenclature History: General CharacteristicsDocument26 paginiNomenclature History: General CharacteristicsZvonko TÎncă nu există evaluări
- Comparative Tolerance Analysis ApproachesDocument11 paginiComparative Tolerance Analysis ApproachesZvonko TÎncă nu există evaluări
- Glider (Aircraft)Document10 paginiGlider (Aircraft)Zvonko TÎncă nu există evaluări
- Confidence IntervalDocument16 paginiConfidence IntervalZvonko TÎncă nu există evaluări
- Sussex Free Radius Case StudyDocument43 paginiSussex Free Radius Case StudyJosef RadingerÎncă nu există evaluări
- Sugar Industries of PakistanDocument19 paginiSugar Industries of Pakistanhelperforeu50% (2)
- CA39BDocument2 paginiCA39BWaheed Uddin Mohammed100% (2)
- Use Reuse and Salvage Guidelines For Measurements of Crankshafts (1202)Document7 paginiUse Reuse and Salvage Guidelines For Measurements of Crankshafts (1202)TASHKEELÎncă nu există evaluări
- The Bipolar Affective Disorder Dimension Scale (BADDS) - A Dimensional Scale For Rating Lifetime Psychopathology in Bipolar Spectrum DisordersDocument11 paginiThe Bipolar Affective Disorder Dimension Scale (BADDS) - A Dimensional Scale For Rating Lifetime Psychopathology in Bipolar Spectrum DisordersDM YazdaniÎncă nu există evaluări
- Channels of CommunicationDocument3 paginiChannels of CommunicationIrin ChhinchaniÎncă nu există evaluări
- Alankit Assignments LTD.: Project Report ONDocument84 paginiAlankit Assignments LTD.: Project Report ONmannuÎncă nu există evaluări
- Sauna Studies As An Academic Field: A New Agenda For International ResearchDocument42 paginiSauna Studies As An Academic Field: A New Agenda For International ResearchsedgehammerÎncă nu există evaluări
- CO-PO MappingDocument6 paginiCO-PO MappingArun Kumar100% (1)
- What Can Tesla Learn From Better Place's FailureDocument54 paginiWhat Can Tesla Learn From Better Place's Failuremail2jose_alex4293Încă nu există evaluări
- 6977 - Read and Answer The WorksheetDocument1 pagină6977 - Read and Answer The Worksheetmohamad aliÎncă nu există evaluări
- Knowledge, Attitude and Practice of Non-Allied Health Sciences Students of Southwestern University Phinma During The Covid-19 PandemicDocument81 paginiKnowledge, Attitude and Practice of Non-Allied Health Sciences Students of Southwestern University Phinma During The Covid-19 Pandemicgeorgemayhew1030Încă nu există evaluări
- Forensic BallisticsDocument23 paginiForensic BallisticsCristiana Jsu DandanÎncă nu există evaluări
- Isolated Foundation PDFDocument6 paginiIsolated Foundation PDFsoroware100% (1)
- Bimetallic ZN and HF On Silica Catalysts For The Conversion of Ethanol To 1,3-ButadieneDocument10 paginiBimetallic ZN and HF On Silica Catalysts For The Conversion of Ethanol To 1,3-ButadieneTalitha AdhyaksantiÎncă nu există evaluări
- Did Angels Have WingsDocument14 paginiDid Angels Have WingsArnaldo Esteves HofileñaÎncă nu există evaluări
- Sona Koyo Steering Systems Limited (SKSSL) Vendor ManagementDocument21 paginiSona Koyo Steering Systems Limited (SKSSL) Vendor ManagementSiddharth UpadhyayÎncă nu există evaluări
- Powerpoints 4 4up8Document9 paginiPowerpoints 4 4up8Ali KalyarÎncă nu există evaluări
- Exam Questions AZ-304: Microsoft Azure Architect Design (Beta)Document9 paginiExam Questions AZ-304: Microsoft Azure Architect Design (Beta)Deepa R NairÎncă nu există evaluări
- Narrative of John 4:7-30 (MSG) : "Would You Give Me A Drink of Water?"Document1 paginăNarrative of John 4:7-30 (MSG) : "Would You Give Me A Drink of Water?"AdrianÎncă nu există evaluări
- Trainee'S Record Book: Technical Education and Skills Development Authority (Your Institution)Document17 paginiTrainee'S Record Book: Technical Education and Skills Development Authority (Your Institution)Ronald Dequilla PacolÎncă nu există evaluări
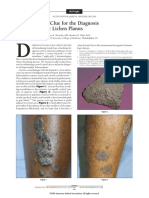
- A Novel Visual Clue For The Diagnosis of Hypertrophic Lichen PlanusDocument1 paginăA Novel Visual Clue For The Diagnosis of Hypertrophic Lichen Planus600WPMPOÎncă nu există evaluări
- Comparing ODS RTF in Batch Using VBA and SASDocument8 paginiComparing ODS RTF in Batch Using VBA and SASseafish1976Încă nu există evaluări
- Comparing Effect of Adding LDPE, PP, PMMA On The Mechanical Properties of Polystyrene (PS)Document12 paginiComparing Effect of Adding LDPE, PP, PMMA On The Mechanical Properties of Polystyrene (PS)Jawad K. OleiwiÎncă nu există evaluări
- Laws and Policies of Fertilizers SectorDocument12 paginiLaws and Policies of Fertilizers Sectorqry01327Încă nu există evaluări
- Statement 876xxxx299 19052022 113832Document2 paginiStatement 876xxxx299 19052022 113832vndurgararao angatiÎncă nu există evaluări
- Neolms Week 1-2,2Document21 paginiNeolms Week 1-2,2Kimberly Quin CanasÎncă nu există evaluări
- Facilities Strategic Asset Management Plan TemplateDocument85 paginiFacilities Strategic Asset Management Plan Templateoli mohamedÎncă nu există evaluări
- Bike Chasis DesignDocument7 paginiBike Chasis Designparth sarthyÎncă nu există evaluări
- Agrarian ReformDocument40 paginiAgrarian ReformYannel Villaber100% (2)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeDe la EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeEvaluare: 4 din 5 stele4/5 (2)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)De la EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Încă nu există evaluări
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsDe la EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsEvaluare: 4.5 din 5 stele4.5/5 (3)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormDe la EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormEvaluare: 5 din 5 stele5/5 (5)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.De la EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Evaluare: 5 din 5 stele5/5 (1)
- Images of Mathematics Viewed Through Number, Algebra, and GeometryDe la EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryÎncă nu există evaluări
- Interactive Math Notebook Resource Book, Grade 6De la EverandInteractive Math Notebook Resource Book, Grade 6Încă nu există evaluări
- Calculus Workbook For Dummies with Online PracticeDe la EverandCalculus Workbook For Dummies with Online PracticeEvaluare: 3.5 din 5 stele3.5/5 (8)
- Mental Math Secrets - How To Be a Human CalculatorDe la EverandMental Math Secrets - How To Be a Human CalculatorEvaluare: 5 din 5 stele5/5 (3)
- ParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)De la EverandParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)Încă nu există evaluări
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingDe la EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingEvaluare: 4.5 din 5 stele4.5/5 (21)
- A Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathDe la EverandA Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathEvaluare: 5 din 5 stele5/5 (1)
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsDe la EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsEvaluare: 3.5 din 5 stele3.5/5 (9)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldDe la EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldEvaluare: 3 din 5 stele3/5 (80)