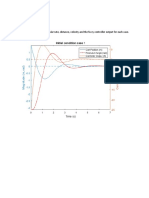
S-ar putea să vă placă și
- Power BIDocument32 paginiPower BIDeepak Arya100% (4)
- Employees Mod DB PDFDocument1 paginăEmployees Mod DB PDFJoe1Încă nu există evaluări
- Knn1 MinMaxScalarDocument13 paginiKnn1 MinMaxScalarJoe1Încă nu există evaluări
- Adler and Towne Comunication ModelDocument2 paginiAdler and Towne Comunication ModelSonam PhuntshoÎncă nu există evaluări
- Eda6 - Sklearn - neighbors.KNeighborsClassifierDocument6 paginiEda6 - Sklearn - neighbors.KNeighborsClassifierAngelito alneg CarYu MendelÎncă nu există evaluări
- KMEANSDocument9 paginiKMEANSjohnzenbano120Încă nu există evaluări
- KNN VS KmeansDocument3 paginiKNN VS KmeansSoubhagya Kumar SahooÎncă nu există evaluări
- Sklearn - neighbors.KNeighborsClassifier - Scikit-Learn 1.4.1 DocumentationDocument6 paginiSklearn - neighbors.KNeighborsClassifier - Scikit-Learn 1.4.1 DocumentationjefferyleclercÎncă nu există evaluări
- SVM Classifier For Multi Class Image ClassificationDocument2 paginiSVM Classifier For Multi Class Image ClassificationthumarushikÎncă nu există evaluări
- IOT DA 21bee0309Document3 paginiIOT DA 21bee0309Sparsh SinghÎncă nu există evaluări
- Machine LearningDocument7 paginiMachine LearningAli HiadrÎncă nu există evaluări
- ML Mid2 AnsDocument24 paginiML Mid2 Ansrayudu shivaÎncă nu există evaluări
- K-Nearest Neighbor by DNDocument10 paginiK-Nearest Neighbor by DNDaanish NarangÎncă nu există evaluări
- Experiment 2.2 KNN ClassifierDocument7 paginiExperiment 2.2 KNN ClassifierArslan MansooriÎncă nu există evaluări
- RBF, KNN, SVM, DTDocument9 paginiRBF, KNN, SVM, DTQurrat Ul AinÎncă nu există evaluări
- Machine LearningDocument56 paginiMachine LearningMani Vrs100% (3)
- UNIT2SVMKNNDocument31 paginiUNIT2SVMKNNAditya SharmaÎncă nu există evaluări
- Pec-Cs 701eDocument4 paginiPec-Cs 701esuvamsarma67Încă nu există evaluări
- Assignment 3Document8 paginiAssignment 3mohamedmariam490Încă nu există evaluări
- Machine Learning Lab - Experiment 7 Implement Logistic Regression On Iris Data SetDocument3 paginiMachine Learning Lab - Experiment 7 Implement Logistic Regression On Iris Data SetRageingrayÎncă nu există evaluări
- PML KNNDocument9 paginiPML KNNJasmitha BÎncă nu există evaluări
- Survery of Nearest NeighborDocument4 paginiSurvery of Nearest NeighborGanesh ChandrasekaranÎncă nu există evaluări
- Learning With Python: Topic: KNNDocument14 paginiLearning With Python: Topic: KNNMukul SharmaÎncă nu există evaluări
- ML NotesDocument125 paginiML NotesAbhijit Das100% (2)
- Untitled 9Document17 paginiUntitled 9Vijayalakshmi GovindarajaluÎncă nu există evaluări
- Experiment 4: Aim/Overview of The Practical: Task To Be DoneDocument7 paginiExperiment 4: Aim/Overview of The Practical: Task To Be DoneMrsingh OfficialÎncă nu există evaluări
- K-Nearest Neighbor (KNN) Algorithm For Machine LearningDocument17 paginiK-Nearest Neighbor (KNN) Algorithm For Machine LearningVijayalakshmi GovindarajaluÎncă nu există evaluări
- Week 7 Part 1KNN K Nearest Neighbor ClassificationDocument47 paginiWeek 7 Part 1KNN K Nearest Neighbor ClassificationMichael ZewdieÎncă nu există evaluări
- Lab # 12 K-Nearest Neighbor (KNN) Algorithm: ObjectiveDocument5 paginiLab # 12 K-Nearest Neighbor (KNN) Algorithm: ObjectiveRana Arsalan AliÎncă nu există evaluări
- First ReportDocument14 paginiFirst Reportdnthrtm3Încă nu există evaluări
- Mathematical Foundations For Machine Learning and Data ScienceDocument25 paginiMathematical Foundations For Machine Learning and Data SciencechaimaeÎncă nu există evaluări
- Algorithms For Concurrency Paper PDFDocument9 paginiAlgorithms For Concurrency Paper PDFranjith rÎncă nu există evaluări
- K-Nearest Neighbors: KNN Algorithm PseudocodeDocument2 paginiK-Nearest Neighbors: KNN Algorithm PseudocodeAnshika TyagiÎncă nu există evaluări
- K - Nearest NeighborDocument2 paginiK - Nearest NeighborAnshika TyagiÎncă nu există evaluări
- Scalable Neural NetworkDocument31 paginiScalable Neural Networkaryandeo2011Încă nu există evaluări
- Introduction To K-Nearest Neighbors: Simplified (With Implementation in Python)Document125 paginiIntroduction To K-Nearest Neighbors: Simplified (With Implementation in Python)Abhiraj Das100% (1)
- K - Nearest Neigbors Hyperparameter: and It'sDocument8 paginiK - Nearest Neigbors Hyperparameter: and It'smourad.zaiedÎncă nu există evaluări
- Project Report 2Document11 paginiProject Report 2seethamrajumukundÎncă nu există evaluări
- AlgorithmDocument27 paginiAlgorithmVipin RajputÎncă nu există evaluări
- CSL0777 L22Document35 paginiCSL0777 L22Konkobo Ulrich ArthurÎncă nu există evaluări
- Algo PaperDocument5 paginiAlgo PaperUzmanÎncă nu există evaluări
- Data Mining and Machine Learning PDFDocument10 paginiData Mining and Machine Learning PDFBidof VicÎncă nu există evaluări
- KNN - TheoryDocument17 paginiKNN - TheoryZarfa MasoodÎncă nu există evaluări
- KNN AlgorithmDocument3 paginiKNN Algorithmrr_adi94Încă nu există evaluări
- Distance Based ModelsDocument19 paginiDistance Based ModelsNidhiÎncă nu există evaluări
- K-Nearest Neighbor: General GistDocument14 paginiK-Nearest Neighbor: General GistSANPREET SINGH GILLÎncă nu există evaluări
- Exact Fuzzy K-Nearest Neighbor Classification For Big DatasetsDocument6 paginiExact Fuzzy K-Nearest Neighbor Classification For Big Datasetsachmad fauzanÎncă nu există evaluări
- Instance-Based Learning: K-Nearest Neighbour LearningDocument21 paginiInstance-Based Learning: K-Nearest Neighbour Learningfeathh1Încă nu există evaluări
- Week10 KNN PracticalDocument4 paginiWeek10 KNN Practicalseerungen jordiÎncă nu există evaluări
- KNN SVM Class Reading: October 31, 2017Document14 paginiKNN SVM Class Reading: October 31, 2017Ayush NagoriÎncă nu există evaluări
- Instance Based Learning: Artificial Intelligence and Machine Learning 18CS71Document19 paginiInstance Based Learning: Artificial Intelligence and Machine Learning 18CS71Suraj HSÎncă nu există evaluări
- IV Distance and Rule Based Models 4.1 Distance Based ModelsDocument45 paginiIV Distance and Rule Based Models 4.1 Distance Based ModelsRamÎncă nu există evaluări
- EE514 - CS535 KNN Algorithm: Overview, Analysis, Convergence and ExtensionsDocument53 paginiEE514 - CS535 KNN Algorithm: Overview, Analysis, Convergence and ExtensionsZubair KhalidÎncă nu există evaluări
- Doc@4Document15 paginiDoc@4morris gichuhiÎncă nu există evaluări
- K-Nearest Neighbor (KNN) Algorithm For Machine Learning - JavatpointDocument18 paginiK-Nearest Neighbor (KNN) Algorithm For Machine Learning - JavatpointAvdesh KumarÎncă nu există evaluări
- Discard The Examples That Contain The Missing ValuesDocument3 paginiDiscard The Examples That Contain The Missing ValuesnazishusmanÎncă nu există evaluări
- Unsupervised Learning - Clustering Cheatsheet - CodecademyDocument5 paginiUnsupervised Learning - Clustering Cheatsheet - CodecademyImane LoukiliÎncă nu există evaluări
- T20 Cricket Score Prediction.Document17 paginiT20 Cricket Score Prediction.AvinashÎncă nu există evaluări
- Dynamic Clustering in WSNDocument7 paginiDynamic Clustering in WSNakshaygoreÎncă nu există evaluări
- Conclusio 8Document2 paginiConclusio 8Piyush HoodÎncă nu există evaluări
- CS40003 (Data Analytics) : Term ProjectDocument10 paginiCS40003 (Data Analytics) : Term ProjectMirnesa SalihovićÎncă nu există evaluări
- B24 ML Exp-3Document10 paginiB24 ML Exp-3SAKSHI TUPSUNDARÎncă nu există evaluări
- Aplikasi KNNDocument5 paginiAplikasi KNNRifki Husnul KhulukÎncă nu există evaluări
- K Nearest Neighbor Algorithm: Fundamentals and ApplicationsDe la EverandK Nearest Neighbor Algorithm: Fundamentals and ApplicationsÎncă nu există evaluări
- Java For SeleniumDocument9 paginiJava For SeleniumJoe1Încă nu există evaluări
- Selenium Testing ProcessDocument9 paginiSelenium Testing ProcessJoe1Încă nu există evaluări
- MATHDocument52 paginiMATHJoe1Încă nu există evaluări
- Selenium 1: Introduction To SeleniumDocument7 paginiSelenium 1: Introduction To SeleniumpriyanshuÎncă nu există evaluări
- POMDocument8 paginiPOMJoe1Încă nu există evaluări
- Selenium Class 3 Selenium Testing Process Part 2 PDFDocument7 paginiSelenium Class 3 Selenium Testing Process Part 2 PDFJoe1Încă nu există evaluări
- Selenium Java Environment SetupDocument7 paginiSelenium Java Environment SetupJoe1Încă nu există evaluări
- Data Dictionary - Unsupervised Customers PDFDocument1 paginăData Dictionary - Unsupervised Customers PDFJoe1Încă nu există evaluări
- Troubleshooting TipsDocument3 paginiTroubleshooting TipsJoe1Încă nu există evaluări
- Windows Quickstart Instructions: Step 1: Download AnacondaDocument7 paginiWindows Quickstart Instructions: Step 1: Download AnacondaJoe1Încă nu există evaluări
- SQLDocument13 paginiSQLJoe1Încă nu există evaluări
- Worksheet 1Document3 paginiWorksheet 1Joe1Încă nu există evaluări
- SELECT From WORLD TutorialDocument13 paginiSELECT From WORLD TutorialJoe1Încă nu există evaluări
- Worksheet 2Document3 paginiWorksheet 2Joe1Încă nu există evaluări
- Hive and ImpalaDocument46 paginiHive and ImpalaJoe1Încă nu există evaluări
- HDFS and YARNDocument91 paginiHDFS and YARNJoe1Încă nu există evaluări
- Decision Tree and EDA With Functions: Import Pandas As PDDocument9 paginiDecision Tree and EDA With Functions: Import Pandas As PDJoe1Încă nu există evaluări
- Big Data Hadoop and Spark Developer: Hbase SupportDocument27 paginiBig Data Hadoop and Spark Developer: Hbase SupportJoe1Încă nu există evaluări
- PigDocument39 paginiPigJoe1Încă nu există evaluări
- Business ScenarioDocument1 paginăBusiness ScenarioJoe1Încă nu există evaluări
- SELECT From NobelDocument13 paginiSELECT From NobelJoe1Încă nu există evaluări
- Knn1 HouseVotesDocument2 paginiKnn1 HouseVotesJoe1Încă nu există evaluări
- Random Forest: Random Forest Has Classifier For Classification and Regressor For RegressionDocument9 paginiRandom Forest: Random Forest Has Classifier For Classification and Regressor For RegressionJoe1Încă nu există evaluări
- Regular Expressions in PythonDocument16 paginiRegular Expressions in PythonJoe1Încă nu există evaluări
- Beautiful Soup 4Document78 paginiBeautiful Soup 4Siva TarunÎncă nu există evaluări
- Random Forest/Roc&Auc - Hyperparamer Tuning With For Loop - TITANIC DBDocument17 paginiRandom Forest/Roc&Auc - Hyperparamer Tuning With For Loop - TITANIC DBJoe1Încă nu există evaluări
- NycDocument12 paginiNycJoe1Încă nu există evaluări
- Autonomous Drone Navigation With Deep Learning: Nikolai Smolyanskiy, Alexey Kamenev, Jeffrey SmithDocument35 paginiAutonomous Drone Navigation With Deep Learning: Nikolai Smolyanskiy, Alexey Kamenev, Jeffrey SmithsifouÎncă nu există evaluări
- Product Rating Engine: Guide: Mr. Uday Joshi Associate ProfessorDocument15 paginiProduct Rating Engine: Guide: Mr. Uday Joshi Associate ProfessorDHRITI SHAHÎncă nu există evaluări
- Oral Communication Asigment (OUMH1303)Document13 paginiOral Communication Asigment (OUMH1303)zackjay72Încă nu există evaluări
- Supervised Learning 1 PDFDocument162 paginiSupervised Learning 1 PDFAlexanderÎncă nu există evaluări
- Lab3 NguyenQuocKhanh ITITIU18186Document7 paginiLab3 NguyenQuocKhanh ITITIU18186Kay NguyenÎncă nu există evaluări
- Clustering-Classification Based Prediction of Stock Market Future PredictionDocument4 paginiClustering-Classification Based Prediction of Stock Market Future PredictionAnkitÎncă nu există evaluări
- Sandy MachineLearning A ReviewDocument7 paginiSandy MachineLearning A ReviewsramukÎncă nu există evaluări
- S4F80 EN Col17 1Document1 paginăS4F80 EN Col17 1sapmaryÎncă nu există evaluări
- Art Integrated ProjectDocument18 paginiArt Integrated ProjectSlim ShadyÎncă nu există evaluări
- The Elements of CommunicationDocument3 paginiThe Elements of Communicationflb39100% (1)
- Intro To ML PDFDocument66 paginiIntro To ML PDFplplÎncă nu există evaluări
- Presentation ThesisDocument37 paginiPresentation ThesissachinÎncă nu există evaluări
- Knowledge Based Expert SystemsDocument4 paginiKnowledge Based Expert SystemsLOOPY GAMINGÎncă nu există evaluări
- Different Types of CommunicationDocument79 paginiDifferent Types of CommunicationMark225userÎncă nu există evaluări
- IJCV2023-SMG-A Micro-Gesture Dataset Towards Spontaneous Body Gestures For Emotional Stress State Analysis. International Journal of Computer VisionDocument21 paginiIJCV2023-SMG-A Micro-Gesture Dataset Towards Spontaneous Body Gestures For Emotional Stress State Analysis. International Journal of Computer Vision2110451818Încă nu există evaluări
- The UNDETECTABLE AI Writing Tool That Matches Your Brand VoiceDocument1 paginăThe UNDETECTABLE AI Writing Tool That Matches Your Brand VoiceghandielaawarÎncă nu există evaluări
- The Discipline of Watching: Detection, Risk, and Lateral Surveillance - Mark AndrejevicDocument18 paginiThe Discipline of Watching: Detection, Risk, and Lateral Surveillance - Mark AndrejevicAnnaBentesÎncă nu există evaluări
- Bio Inspired ComputingDocument4 paginiBio Inspired ComputingImran HossainÎncă nu există evaluări
- IOE Syllabus of Data MiningDocument2 paginiIOE Syllabus of Data MiningBulmi HilmeÎncă nu există evaluări
- What Is The KDD ProcessDocument2 paginiWhat Is The KDD ProcessUmesh MkÎncă nu există evaluări
- Cobot Programming For Collaborative Industrial Tasks: An OverviewDocument37 paginiCobot Programming For Collaborative Industrial Tasks: An OverviewSayantan RahaÎncă nu există evaluări
- A Review On Credit Card Fraud Detection Using Machine LearningDocument4 paginiA Review On Credit Card Fraud Detection Using Machine LearningPranshu SrivastavaÎncă nu există evaluări
- Character Segmentation and Recognition of Marathi LanguageDocument10 paginiCharacter Segmentation and Recognition of Marathi LanguageIJRASETPublicationsÎncă nu există evaluări
- Isb Aba BrochureDocument15 paginiIsb Aba Brochureswapnilpednekar842Încă nu există evaluări
- Machine LearningDocument7 paginiMachine LearningxyzÎncă nu există evaluări
- Criminal Face Recognition Using GANDocument3 paginiCriminal Face Recognition Using GANInternational Journal of Innovative Science and Research TechnologyÎncă nu există evaluări
- BookSellerFlyer 9781484241660Document1 paginăBookSellerFlyer 9781484241660超揚林Încă nu există evaluări
- Assignment 11 SolutionsDocument8 paginiAssignment 11 SolutionsVangipuram Badriramakrishnan100% (1)
- The Position Paper at IBM Research InternshipDocument2 paginiThe Position Paper at IBM Research InternshipdursaÎncă nu există evaluări