S-ar putea să vă placă și
- Elementos de estadística para ingeniería: Un curso básicoDe la EverandElementos de estadística para ingeniería: Un curso básicoÎncă nu există evaluări
- Prueba T de StudentDocument24 paginiPrueba T de StudentAliciaT❤Încă nu există evaluări
- Variables Aleatorias HazaelDocument10 paginiVariables Aleatorias HazaelEdgar AmauryÎncă nu există evaluări
- EstadigrafosDocument12 paginiEstadigrafosAna Aracelli Lázaro100% (1)
- Análisis de Datos Categóricos - Prueba Chi-CuadradoDocument3 paginiAnálisis de Datos Categóricos - Prueba Chi-CuadradoSandra Cecilia Loaiza ChumaceroÎncă nu există evaluări
- Mat125 1 1 7Document65 paginiMat125 1 1 7Gabriel GutierrezÎncă nu există evaluări
- Distribuciones de ProbabilidadDocument57 paginiDistribuciones de ProbabilidadMona VegaoliÎncă nu există evaluări
- Tema 1 Estadistica Matematica PROBABILIDADES PDFDocument162 paginiTema 1 Estadistica Matematica PROBABILIDADES PDFDaniela LiChÎncă nu există evaluări
- Ejemplo de Distribucion de PoissonDocument2 paginiEjemplo de Distribucion de Poissonhenry SuarezÎncă nu există evaluări
- Tarea de Muestra (Estadística)Document11 paginiTarea de Muestra (Estadística)Kenneth MazabandaÎncă nu există evaluări
- Prueba de Hipotesis I 2019-2Document35 paginiPrueba de Hipotesis I 2019-2Ricardo Angel Berrio PerezÎncă nu există evaluări
- Estadística BásicaDocument99 paginiEstadística BásicatkruggerÎncă nu există evaluări
- Investigacion Unidad 5Document20 paginiInvestigacion Unidad 5Paola RuizÎncă nu există evaluări
- Probabilidades.-Ejercicios ResueltosDocument20 paginiProbabilidades.-Ejercicios ResueltosMario Orlando Suárez IbujésÎncă nu există evaluări
- Examen Septiembre 2014 Con SolucionesDocument16 paginiExamen Septiembre 2014 Con SolucionesAntonioÎncă nu există evaluări
- GEPB0O154Document2 paginiGEPB0O154David LLontopÎncă nu există evaluări
- 4 TALLER 1 Variables - Aleartorias - Continuas PDFDocument1 pagină4 TALLER 1 Variables - Aleartorias - Continuas PDFJuan Pablo Villalobos AguilarÎncă nu există evaluări
- ProbabilidadDocument34 paginiProbabilidadjesus caballero rayonÎncă nu există evaluări
- Análisis de CovarianzaDocument21 paginiAnálisis de CovarianzaDavid Misael Contreras SalazarÎncă nu există evaluări
- Notas de Clase Diseño de ExperimentosDocument61 paginiNotas de Clase Diseño de ExperimentosBaruck Lucho MixtegaÎncă nu există evaluări
- 3 - Práctica 2 - Distribución Conjunta y CondicionalDocument9 pagini3 - Práctica 2 - Distribución Conjunta y CondicionalValen MoranÎncă nu există evaluări
- Profesor: Juan Luis Espinoza ValledorDocument1 paginăProfesor: Juan Luis Espinoza ValledorTextos de IngenieriaÎncă nu există evaluări
- Unidad III VA PAB TMDocument80 paginiUnidad III VA PAB TMLuis CarbajalÎncă nu există evaluări
- Ejercicios de ProbabilidadesDocument12 paginiEjercicios de ProbabilidadesDANIEL JOSE PEZO BACAÎncă nu există evaluări
- Resumen Unidad 4 AlgebraDocument10 paginiResumen Unidad 4 AlgebraMisael NavaÎncă nu există evaluări
- Eventos Independientes y Probabilidad CondicionalDocument2 paginiEventos Independientes y Probabilidad CondicionalMael D. J Corrales BarbaÎncă nu există evaluări
- Más Ejercicios Sobre Sucesos y ProbabilidadDocument17 paginiMás Ejercicios Sobre Sucesos y ProbabilidadthoslianÎncă nu există evaluări
- Guía Informática 11° 3P.Document5 paginiGuía Informática 11° 3P.Paola silvaÎncă nu există evaluări
- Cap 5Document15 paginiCap 5Eivyn ArrietaÎncă nu există evaluări
- Silabos Diseño ExperimentosDocument3 paginiSilabos Diseño ExperimentosAnthony Zevallos GuzmanÎncă nu există evaluări
- Derivadas e IntegrantesDocument10 paginiDerivadas e IntegrantesDiegoHidalgoVergelÎncă nu există evaluări
- Intro EstadisticaDocument51 paginiIntro EstadisticaAnonymous OQxqdoÎncă nu există evaluări
- Chi CuadradaDocument23 paginiChi CuadradaDiana BaldeónÎncă nu există evaluări
- Ejercicios Resueltos Estimación Inferencia EstadísticaDocument9 paginiEjercicios Resueltos Estimación Inferencia EstadísticaMarcelohenÎncă nu există evaluări
- Análisis UnivariadoDocument37 paginiAnálisis UnivariadoMaka RaPu MosqueraÎncă nu există evaluări
- Número ComplejoDocument9 paginiNúmero ComplejoAidee FierroÎncă nu există evaluări
- Modulo3 2017Document27 paginiModulo3 2017Emilce Bogado MartinezÎncă nu există evaluări
- Diapos Estimación de Parámetros Intervalos de ConfianzaDocument25 paginiDiapos Estimación de Parámetros Intervalos de Confianzajorge macedoÎncă nu există evaluări
- Sucesiones Cuadr (AticasDocument7 paginiSucesiones Cuadr (AticasJuan BautistaÎncă nu există evaluări
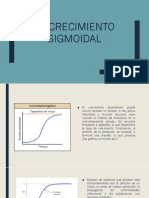
- El Crecimiento SigmoidalDocument15 paginiEl Crecimiento SigmoidalDaisy Medina ʚïɞÎncă nu există evaluări
- Divisibilidad Prof SiberioDocument24 paginiDivisibilidad Prof SiberiodanielodellaÎncă nu există evaluări
- RelprL3 6 Compl ResueltaDocument19 paginiRelprL3 6 Compl ResueltaRicardo Diaz HidalgoÎncă nu există evaluări
- Guía de Actividad 2. Movimiento de Proyectil y Caída LibreDocument9 paginiGuía de Actividad 2. Movimiento de Proyectil y Caída LibreKevin HerreraÎncă nu există evaluări
- 10 - Estadistica Descriptiva BivariadaDocument5 pagini10 - Estadistica Descriptiva BivariadaFernando JordanÎncă nu există evaluări
- Variable Aleatoria Discreta EjerciciosDocument10 paginiVariable Aleatoria Discreta EjerciciosAlbertoMaxAkiraKasayBejaranoÎncă nu există evaluări
- Capítulo3Estad IDocument12 paginiCapítulo3Estad IJuan MassÎncă nu există evaluări
- Tema 3. Aplicaciones de La IntegralDocument15 paginiTema 3. Aplicaciones de La IntegralFrancisco martinezÎncă nu există evaluări
- Práctica 4 - Teoría de La Probabilidad IDocument5 paginiPráctica 4 - Teoría de La Probabilidad IRaul GalindezÎncă nu există evaluări
- Leyes de Los Operadores Fundamentales Unión e IntersecciónDocument4 paginiLeyes de Los Operadores Fundamentales Unión e IntersecciónJohnny Vera100% (2)
- Teoria de La Proyeccion OrtogonalDocument21 paginiTeoria de La Proyeccion OrtogonalElisabeth Qeesoo Dee Lautner100% (1)
- Cuadernillo Probabilidad AnalistasDocument20 paginiCuadernillo Probabilidad AnalistasHoli Temmie GabrielÎncă nu există evaluări
- Teo Limite Central Distrib Media MuestralDocument8 paginiTeo Limite Central Distrib Media MuestralLeonel PalominoÎncă nu există evaluări
- 4.0 Distribucion de PoissonDocument14 pagini4.0 Distribucion de PoissonAndrz De La Fuente VigilÎncă nu există evaluări
- Eficiencia de Los Estimadores. Muestreo SistemáticoDocument7 paginiEficiencia de Los Estimadores. Muestreo SistemáticoJuan Carlos TalaveraÎncă nu există evaluări
- Prueba de PermutacionDocument9 paginiPrueba de PermutacionMarioEstebanPérezRodríguez100% (1)
- Inferencia Estadistica 2 Guillermo RamirezDocument25 paginiInferencia Estadistica 2 Guillermo RamirezDomenico ZuzoloÎncă nu există evaluări
- Probabilidad Condicional, Total y Teorema de BayesDocument13 paginiProbabilidad Condicional, Total y Teorema de BayesTruan Alberto Gracia Carbón100% (1)
- Intervalo de Confianza para La Media de Una Distribución NormalDocument9 paginiIntervalo de Confianza para La Media de Una Distribución NormalJavierÎncă nu există evaluări
- Unidad 1 Parte A EST1Document89 paginiUnidad 1 Parte A EST1Ricardo Andre CienfuegosÎncă nu există evaluări
- AE - Probabilidad y Estadística - Material Didáctico - 125520Document86 paginiAE - Probabilidad y Estadística - Material Didáctico - 125520Ramírez Vega Diana AndreaÎncă nu există evaluări
- ES Guia Delphi Marco Cantu DesarrolloDocument502 paginiES Guia Delphi Marco Cantu Desarrollocova5609Încă nu există evaluări
- ES Guia Practica Del Desarrollo Aplicaciones Windows en Net FreeDocument412 paginiES Guia Practica Del Desarrollo Aplicaciones Windows en Net Freecova5609100% (1)
- Delphi Database Español Jorge VillalobosDocument679 paginiDelphi Database Español Jorge VillalobosAnonimo Sin Nombre67% (3)
- ES IOS Desarrollo Aplicaciones Iosandroid CharteDocument614 paginiES IOS Desarrollo Aplicaciones Iosandroid Chartenokia2nokia100% (1)
- ES Aprenda JBuilder Con Charlie CalvertDocument952 paginiES Aprenda JBuilder Con Charlie Calvertcova5609Încă nu există evaluări
- CoreAPIsp PDFDocument825 paginiCoreAPIsp PDFJuan PujolÎncă nu există evaluări
- Delphi API GraficoDocument939 paginiDelphi API GraficoivancmlÎncă nu există evaluări
- Estadistica1 1Document80 paginiEstadistica1 1carlosllbÎncă nu există evaluări
- Adiós Dolor de EspaldaDocument637 paginiAdiós Dolor de EspaldapepeÎncă nu există evaluări
- Monografia Met. Inv. Cientifica CT Primera ParteDocument59 paginiMonografia Met. Inv. Cientifica CT Primera ParteMauriciogonzalez1Încă nu există evaluări
- Problemas Resueltos de Estadist - Sergio ZubelzuDocument240 paginiProblemas Resueltos de Estadist - Sergio Zubelzuorfeo0610100% (6)
- Estadisica TeoriaDocument68 paginiEstadisica TeoriaDiego Juan Alarcon Sanchez100% (1)
- Curso CompleetoDocument91 paginiCurso CompleetoElizabeth CollinsÎncă nu există evaluări
- Documento Final Estadc3adsticas PDFDocument116 paginiDocumento Final Estadc3adsticas PDFIrving Jeanpiere Zenteno LópezÎncă nu există evaluări
- Variables Hidrometereológicas Asociadas Al Cambio Climático en Girardot y La Región Del Alto MagdalenaDocument16 paginiVariables Hidrometereológicas Asociadas Al Cambio Climático en Girardot y La Región Del Alto MagdalenaWalid CuelloÎncă nu există evaluări
- Problemas Resueltos de Estadistica Aplicada A Las Ciencias SocialesDocument298 paginiProblemas Resueltos de Estadistica Aplicada A Las Ciencias SocialesRudox69Încă nu există evaluări
- Usos y Limitaciones de Los Metodos de Analisis Multivariado en La Investiga EpidemiologicaDocument5 paginiUsos y Limitaciones de Los Metodos de Analisis Multivariado en La Investiga Epidemiologicacova5609Încă nu există evaluări
- SeriesF - 28S Manual de Organizacion EstadisticaDocument101 paginiSeriesF - 28S Manual de Organizacion Estadisticacova5609Încă nu există evaluări
- TEORIA DEL MUESTREO Muestras Aleatorias Errores enDocument90 paginiTEORIA DEL MUESTREO Muestras Aleatorias Errores ennn357Încă nu există evaluări
- Steel Robert G - Bioestadistica Principios Y Procedimientos 2ed PDFDocument640 paginiSteel Robert G - Bioestadistica Principios Y Procedimientos 2ed PDFJerry Vivas Torrez100% (1)
- Bioestadistica 2Document71 paginiBioestadistica 2Marcia Andrea Rencoret InfanteÎncă nu există evaluări
- Metodos de Muestreo para Las Encuestas Agricolas FAO-1990Document325 paginiMetodos de Muestreo para Las Encuestas Agricolas FAO-1990cova5609Încă nu există evaluări
- Metodos Determinar Fuentes Sodio en AlimentacionDocument42 paginiMetodos Determinar Fuentes Sodio en Alimentacioncova5609Încă nu există evaluări
- Problemas Existentes - Estadistica e Investiga AgrariaDocument15 paginiProblemas Existentes - Estadistica e Investiga Agrariacova5609Încă nu există evaluări
- Nociones y Fundamentos Estadísticos en La Investigacion AgricolaDocument95 paginiNociones y Fundamentos Estadísticos en La Investigacion Agricolajustorfc100% (2)
- Modelo Medir Variabilidad Del Suelo Por Medio Del Analisis Geoespacial 2017Document44 paginiModelo Medir Variabilidad Del Suelo Por Medio Del Analisis Geoespacial 2017cova5609Încă nu există evaluări
- Metodos de Estadistica para Evaluar Influencia de Factores Medioambientales en CancerDocument406 paginiMetodos de Estadistica para Evaluar Influencia de Factores Medioambientales en Cancercova5609Încă nu există evaluări
- Metodos Estadisticos AlternativosDocument149 paginiMetodos Estadisticos AlternativosTobiasÎncă nu există evaluări
- Metodos Apropiados Investiga y Eval en Agricultura UrbanaDocument86 paginiMetodos Apropiados Investiga y Eval en Agricultura Urbanacova5609Încă nu există evaluări
- Eje 3 Analisis de DatosDocument12 paginiEje 3 Analisis de DatosMamboYepezÎncă nu există evaluări
- Formulario Prob GDCDocument11 paginiFormulario Prob GDCJosuè Priego SanabriaÎncă nu există evaluări
- Practica 7 Distribuciones Muestrales e Intervalo de Confianza-1Document4 paginiPractica 7 Distribuciones Muestrales e Intervalo de Confianza-1Alejandro LaraÎncă nu există evaluări
- VarianzaDocument12 paginiVarianzaAlejandro SanchezÎncă nu există evaluări
- Metodos ProbabilisticosDocument6 paginiMetodos ProbabilisticosK-05Încă nu există evaluări
- Tarea1 - Yerlany - Ramirez EsDocument9 paginiTarea1 - Yerlany - Ramirez EsYerlanyRamirezMedinaÎncă nu există evaluări
- Dia 3. AED y ProfilingDocument73 paginiDia 3. AED y ProfilingSimon RodriguezÎncă nu există evaluări
- Laboratorioestadistico 3Document22 paginiLaboratorioestadistico 3Dl DenhisÎncă nu există evaluări
- Taller 2 de Estadistica PDFDocument7 paginiTaller 2 de Estadistica PDFAndrea VegaÎncă nu există evaluări
- Test Estadística y Epidemiología - PREAMIRDocument14 paginiTest Estadística y Epidemiología - PREAMIRLUIS ALBERTO AYALA ESTRADAÎncă nu există evaluări
- Modulo IX Estadistica IDocument21 paginiModulo IX Estadistica IJosué Sauceda SilvaÎncă nu există evaluări
- EstadísticaDocument36 paginiEstadísticaClopkÎncă nu există evaluări
- Clase 3Document76 paginiClase 3Rodrigo Lagos ChavezÎncă nu există evaluări
- Entregable 2 Calidad TotalDocument13 paginiEntregable 2 Calidad TotalLuis CrisólogoÎncă nu există evaluări
- Universidad de San Carlos de Guatemala CDocument10 paginiUniversidad de San Carlos de Guatemala CKanika KhanÎncă nu există evaluări
- DeberDocument8 paginiDeberEvelyn Chucay ChachaÎncă nu există evaluări
- Tarea Semana 3Document7 paginiTarea Semana 3Jonahtan AguilarÎncă nu există evaluări
- Hoja 1Document2 paginiHoja 1dulzo35100% (1)
- BIOESTADISTICA-anexo-Guía Estadística DescriptivaDocument2 paginiBIOESTADISTICA-anexo-Guía Estadística DescriptivaSILVIA BETANCURÎncă nu există evaluări
- Qué Es La EstadísticaDocument10 paginiQué Es La EstadísticaJesus DiazÎncă nu există evaluări
- APznzaY5JYAWd - 2xR0PYUHR4depEA7Dx5UDihNmb1tH 7SJzW9xsnIcsOtACcqJ9pMVj4kSLcF8irAWpK - wXx0r5zS e9gtxD55vMIrPmm5BeZkD9cO2rwQySLQff40KGzuLRqFdykgIqVgbDocument1 paginăAPznzaY5JYAWd - 2xR0PYUHR4depEA7Dx5UDihNmb1tH 7SJzW9xsnIcsOtACcqJ9pMVj4kSLcF8irAWpK - wXx0r5zS e9gtxD55vMIrPmm5BeZkD9cO2rwQySLQff40KGzuLRqFdykgIqVgbNaye MedinaÎncă nu există evaluări
- S02.s1 - MaterialDocument24 paginiS02.s1 - Materialgabriel chunga yucraÎncă nu există evaluări
- Tipos de VarianzaDocument26 paginiTipos de VarianzaFlorencia Denise SandinÎncă nu există evaluări
- Unidad 6 Distribuciones ContinuasDocument4 paginiUnidad 6 Distribuciones ContinuasLuis Achoy BustamanteÎncă nu există evaluări
- Explica 10Document13 paginiExplica 10Manuel BuendiaÎncă nu există evaluări
- EstadísticasDocument15 paginiEstadísticasMaster GtaÎncă nu există evaluări
- Elementos de Inferencia Estadística Experimentos Con Uno y Dos TratamientosDocument8 paginiElementos de Inferencia Estadística Experimentos Con Uno y Dos TratamientosemmanuelÎncă nu există evaluări
- Dominio MatematicoDocument88 paginiDominio MatematicoPool LescanoÎncă nu există evaluări
- Teoria y Ejercicios Distribucion Muestral de La MuestraDocument11 paginiTeoria y Ejercicios Distribucion Muestral de La MuestraKaren ValeriaÎncă nu există evaluări
- Práctica Calificada - Simón Ordoñez MalaverDocument20 paginiPráctica Calificada - Simón Ordoñez MalaverEDMIR SIM�N ORDO�EZ MALAVERÎncă nu există evaluări