S-ar putea să vă placă și
- Optimization For Data ScienceDocument18 paginiOptimization For Data ScienceVaibhav GuptaÎncă nu există evaluări
- IIT Optimization Lecture IntroDocument9 paginiIIT Optimization Lecture IntroteyqqgfnyphcyhwnexÎncă nu există evaluări
- MITOCW Lecture 3 Cube Root AlgorithmDocument13 paginiMITOCW Lecture 3 Cube Root AlgorithmAshley AndersonÎncă nu există evaluări
- Advanced Finite Element Analysis Prof. R. Krishnakumar Department of Mechanical Engineering Indian Institute of Technology, Madras Lecture - 2Document23 paginiAdvanced Finite Element Analysis Prof. R. Krishnakumar Department of Mechanical Engineering Indian Institute of Technology, Madras Lecture - 2abimanaÎncă nu există evaluări
- Linear ProgrammingDocument209 paginiLinear ProgrammingDuma DumaiÎncă nu există evaluări
- Optimization Techniques IntroductionDocument20 paginiOptimization Techniques IntroductionabhiÎncă nu există evaluări
- 07 09 P3-EnDocument3 pagini07 09 P3-EnBenÎncă nu există evaluări
- GROKKING ALGORITHM BLUEPRINT: A Comprehensive Beginner's Guide to Learn the Realms of Grokking Algorithms from A-Z and Become Efficient ProgrammersDe la EverandGROKKING ALGORITHM BLUEPRINT: A Comprehensive Beginner's Guide to Learn the Realms of Grokking Algorithms from A-Z and Become Efficient ProgrammersÎncă nu există evaluări
- NPT 2Document11 paginiNPT 2Vilayat AliÎncă nu există evaluări
- Multiple Quantifiers in Symbolic LogicDocument12 paginiMultiple Quantifiers in Symbolic LogicMiyÎncă nu există evaluări
- Advanced Linear ProgrammingDocument209 paginiAdvanced Linear Programmingpraneeth nagasai100% (1)
- Lec 61Document13 paginiLec 61anupriyaaaÎncă nu există evaluări
- Deep Learning Loss and Output FunctionsDocument15 paginiDeep Learning Loss and Output FunctionssixfacerajÎncă nu există evaluări
- 3fe0cc8ce9bb9a219tyutytutuytuff030a880619abc SioXozu-LooDocument13 pagini3fe0cc8ce9bb9a219tyutytutuytuff030a880619abc SioXozu-LooBild LucaÎncă nu există evaluări
- Advanced Finite Element Analysis Prof. R. Krishnakumar Department of Mechanical Engineering Indian Institute of Technology, Madras Lecture - 9Document24 paginiAdvanced Finite Element Analysis Prof. R. Krishnakumar Department of Mechanical Engineering Indian Institute of Technology, Madras Lecture - 9abimanaÎncă nu există evaluări
- TheFourierTransformAndItsApplicationsDocument12 paginiTheFourierTransformAndItsApplicationsNi PeterÎncă nu există evaluări
- Advanced Operations Research Prof. G. Srinivasan Department of Management Studies Indian Institute of Technology, MadrasDocument26 paginiAdvanced Operations Research Prof. G. Srinivasan Department of Management Studies Indian Institute of Technology, Madraskhalidscribd1Încă nu există evaluări
- Yousef ML Washin RegressionDocument590 paginiYousef ML Washin Regressionyousef shabanÎncă nu există evaluări
- Optimization techniques for solving nonlinear programming problemsDocument19 paginiOptimization techniques for solving nonlinear programming problemsAbaniÎncă nu există evaluări
- Factoring Trinomials Common Core Algebra 1 HomeworkDocument7 paginiFactoring Trinomials Common Core Algebra 1 Homeworkafefhojno100% (1)
- The Fourier Transform and Its ApplicationsDocument15 paginiThe Fourier Transform and Its ApplicationsNi PeterÎncă nu există evaluări
- Lec 33Document20 paginiLec 33SaidÎncă nu există evaluări
- QdbkvD4N UsDocument17 paginiQdbkvD4N UsTheoÎncă nu există evaluări
- Software Testing Logic CoverageDocument19 paginiSoftware Testing Logic Coverage1367 AYUSHA KATEPALLEWARÎncă nu există evaluări
- Optimization: Practice Problems Assignment ProblemsDocument11 paginiOptimization: Practice Problems Assignment ProblemsNardo Gunayon FinezÎncă nu există evaluări
- Week 009 Calculus I - OptimizationDocument7 paginiWeek 009 Calculus I - Optimizationvit.chinnajiginisaÎncă nu există evaluări
- Lec 5Document6 paginiLec 5Ravi KumarÎncă nu există evaluări
- When Is The Function Increasing?Document11 paginiWhen Is The Function Increasing?Official-site suuÎncă nu există evaluări
- Optimization From Fundamentals Prof. Ankur Kulkarni Department of Systems and Control Engineering Indian Institute of Technology, Bombay Lecture - 1ADocument5 paginiOptimization From Fundamentals Prof. Ankur Kulkarni Department of Systems and Control Engineering Indian Institute of Technology, Bombay Lecture - 1Asinojkumar malipronÎncă nu există evaluări
- Lec 2Document10 paginiLec 2teyqqgfnyphcyhwnexÎncă nu există evaluări
- Foundation of Optimization Prof. Dr. Joydeep Dutta Department of Mathematics and Statistics Indian Institute of Technology, Kanpur Lecture - 1Document11 paginiFoundation of Optimization Prof. Dr. Joydeep Dutta Department of Mathematics and Statistics Indian Institute of Technology, Kanpur Lecture - 1Souvik MitraÎncă nu există evaluări
- Intuitive Calculus Lessons ExplainedDocument17 paginiIntuitive Calculus Lessons Explainedaslam844Încă nu există evaluări
- Classifying Problems by ComplexityDocument6 paginiClassifying Problems by ComplexityRima MkhÎncă nu există evaluări
- Newton Raphson Method Maths CourseworkDocument6 paginiNewton Raphson Method Maths Courseworkafazbsaxi100% (2)
- Limit Lessons: Where To Begin?Document17 paginiLimit Lessons: Where To Begin?aslam844Încă nu există evaluări
- Instructor (Brad Osgood) :it's True, You Know. There I Was, Lying There and The Cop SaidDocument12 paginiInstructor (Brad Osgood) :it's True, You Know. There I Was, Lying There and The Cop SaidMohan KumarÎncă nu există evaluări
- Structural DynamicsDocument16 paginiStructural DynamicsSushanta Kumar RoyÎncă nu există evaluări
- Instructor (Brad Osgood) :are We On? I Can't See. It Looks Kinda Dark. I Don't Know. ItDocument12 paginiInstructor (Brad Osgood) :are We On? I Can't See. It Looks Kinda Dark. I Don't Know. ItElisée NdjabuÎncă nu există evaluări
- Advanced Operations Research Prof. G. Srinivasan Department of Management Studies Indian Institute of Technology, MadrasDocument20 paginiAdvanced Operations Research Prof. G. Srinivasan Department of Management Studies Indian Institute of Technology, Madrasammar sangeÎncă nu există evaluări
- Lec 37Document12 paginiLec 37maherkamelÎncă nu există evaluări
- Computability Theory: An Introduction to Recursion Theory, Students Solutions Manual (e-only)De la EverandComputability Theory: An Introduction to Recursion Theory, Students Solutions Manual (e-only)Încă nu există evaluări
- Paul's Online Math NotesDocument4 paginiPaul's Online Math NotesAnonymous ox4NSRÎncă nu există evaluări
- Psych MKR 2Document18 paginiPsych MKR 2Vilayat AliÎncă nu există evaluări
- Unit 1 - Operation Research and Supply Chain - WWW - Rgpvnotes.inDocument30 paginiUnit 1 - Operation Research and Supply Chain - WWW - Rgpvnotes.inkp4041392Încă nu există evaluări
- Instructor (Brad Osgood) :I Wonder How Long I Can Keep This Up. All Right. So The FirstDocument13 paginiInstructor (Brad Osgood) :I Wonder How Long I Can Keep This Up. All Right. So The FirstElisée NdjabuÎncă nu există evaluări
- Lec20 PDFDocument27 paginiLec20 PDFANKUSHÎncă nu există evaluări
- NPTEL FEM Lec4Document35 paginiNPTEL FEM Lec4EliÎncă nu există evaluări
- Newton Raphson Method c3 CourseworkDocument4 paginiNewton Raphson Method c3 Courseworkafazapfjl100% (2)
- Introduction To Finite Element Method Dr. R. Krishnakumar Department of Mechanical Engineering Indian Institute of Technology, Madras Lecture - 14Document21 paginiIntroduction To Finite Element Method Dr. R. Krishnakumar Department of Mechanical Engineering Indian Institute of Technology, Madras Lecture - 14mahendranÎncă nu există evaluări
- Lec 1Document26 paginiLec 1Tahir AbbasÎncă nu există evaluări
- Section 5Document78 paginiSection 5Dr. Yogesh SrivastavaÎncă nu există evaluări
- Lec 27Document20 paginiLec 27Vilayat AliÎncă nu există evaluări
- Free and The Bound Variables. Ok?Document11 paginiFree and The Bound Variables. Ok?MiyÎncă nu există evaluări
- Swayam EngDocument34 paginiSwayam EngsriramchaudhuryÎncă nu există evaluări
- Instructor (Mehran Sahami) :alrighty. Welcome Back To Yet Another Fun-Filled ExcitingDocument21 paginiInstructor (Mehran Sahami) :alrighty. Welcome Back To Yet Another Fun-Filled ExcitingNitish PathakÎncă nu există evaluări
- Instructor (Andrew NG) :okay, Good Morning. Welcome Back. So I Hope All of You HadDocument14 paginiInstructor (Andrew NG) :okay, Good Morning. Welcome Back. So I Hope All of You HadSethu SÎncă nu există evaluări
- Maximizing Paper Roll ProductionDocument11 paginiMaximizing Paper Roll ProductionteyqqgfnyphcyhwnexÎncă nu există evaluări
- Lecture-1-Introduction To Soft Computing PDFDocument11 paginiLecture-1-Introduction To Soft Computing PDFእመ እጓልÎncă nu există evaluări
- Attacking Problems in Logarithms and Exponential FunctionsDe la EverandAttacking Problems in Logarithms and Exponential FunctionsEvaluare: 5 din 5 stele5/5 (1)
- Six Sigma Sampling PlansDocument42 paginiSix Sigma Sampling PlansabraÎncă nu există evaluări
- 8 QualityDocument26 pagini8 QualitymaherkamelÎncă nu există evaluări
- Acceptance SamplingDocument19 paginiAcceptance Samplingpm3dÎncă nu există evaluări
- Beyond Taguchi's Concept of The Quality Loss Function: Atul Dev, Pankaj JhaDocument5 paginiBeyond Taguchi's Concept of The Quality Loss Function: Atul Dev, Pankaj JhamaherkamelÎncă nu există evaluări
- Introduction To Six SigmaDocument30 paginiIntroduction To Six SigmaadysubagyaÎncă nu există evaluări
- Basic Chart ConceptsDocument13 paginiBasic Chart ConceptsmaherkamelÎncă nu există evaluări
- Attributes Data: Binomial and Poisson DataDocument31 paginiAttributes Data: Binomial and Poisson DatamaherkamelÎncă nu există evaluări
- PQ Unit-IiDocument6 paginiPQ Unit-IimaherkamelÎncă nu există evaluări
- Inspection, Quality Control, and Assurance SHEET (1) : 6-If The Mean Value of The Measured Stress Was 15 KG/MMDocument1 paginăInspection, Quality Control, and Assurance SHEET (1) : 6-If The Mean Value of The Measured Stress Was 15 KG/MMmaherkamelÎncă nu există evaluări
- Quality Assurance and Quality ControlDocument17 paginiQuality Assurance and Quality Controltraslie0% (1)
- The Quality Improvement Model: Is Process Capable?Document19 paginiThe Quality Improvement Model: Is Process Capable?maherkamelÎncă nu există evaluări
- Chapter 9Document9 paginiChapter 9Rasha Abduldaiem ElmalikÎncă nu există evaluări
- Define Process in 40 CharactersDocument18 paginiDefine Process in 40 Charactersmaherkamel100% (1)
- GE2022 TQM Notes 2 PDFDocument15 paginiGE2022 TQM Notes 2 PDFBalakumar MurugesanÎncă nu există evaluări
- Gage R&RDocument24 paginiGage R&ROMAR CECEÑASÎncă nu există evaluări
- Acceptance SamplingDocument19 paginiAcceptance Samplingpm3dÎncă nu există evaluări
- ISO History (Brief) and Basic FactsDocument9 paginiISO History (Brief) and Basic FactsmaherkamelÎncă nu există evaluări
- Forming 2 PDFDocument43 paginiForming 2 PDFNeoXana01Încă nu există evaluări
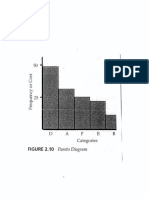
- Pareto and QualityDocument1 paginăPareto and QualitymaherkamelÎncă nu există evaluări
- HW1 2Document2 paginiHW1 2maherkamelÎncă nu există evaluări
- HW3 ADocument2 paginiHW3 Ajambu99Încă nu există evaluări
- Chapter 9Document9 paginiChapter 9Rasha Abduldaiem ElmalikÎncă nu există evaluări
- Basics 1Document7 paginiBasics 1maherkamelÎncă nu există evaluări
- Course 649Document2 paginiCourse 649jambu99Încă nu există evaluări
- HW 1Document2 paginiHW 1maherkamelÎncă nu există evaluări
- Mechanics 2Document14 paginiMechanics 2maherkamelÎncă nu există evaluări
- ME 423 Machine DesignDocument2 paginiME 423 Machine DesignmaherkamelÎncă nu există evaluări
- ChatterDocument9 paginiChattermaherkamelÎncă nu există evaluări
- Quality Lecture NotesDocument23 paginiQuality Lecture NotesmaherkamelÎncă nu există evaluări
- Me338 10Document2 paginiMe338 10maherkamelÎncă nu există evaluări
- QM in Library PDFDocument25 paginiQM in Library PDFgaurav sharmaÎncă nu există evaluări
- Computer & ITDocument148 paginiComputer & ITMohit GuptaÎncă nu există evaluări
- Pepar OtDocument4 paginiPepar Otarjun16012024Încă nu există evaluări
- GraphsDocument409 paginiGraphsAsafAhmadÎncă nu există evaluări
- Ant Colony Optimization ExplainedDocument23 paginiAnt Colony Optimization ExplainedChitransh ShrivastavaÎncă nu există evaluări
- Question4 - Questions 2 - CSE423 Courseware - Bux - BRAC University PDFDocument4 paginiQuestion4 - Questions 2 - CSE423 Courseware - Bux - BRAC University PDFRakeen Ashraf ChowdhuryÎncă nu există evaluări
- Convolutional CodingDocument42 paginiConvolutional Codingtkg1357Încă nu există evaluări
- Process Scheduling AlgorithmsDocument3 paginiProcess Scheduling AlgorithmsKartik VermaÎncă nu există evaluări
- Data Structure (DS) Solved Mcqs Set 4Document7 paginiData Structure (DS) Solved Mcqs Set 4sfarithaÎncă nu există evaluări
- Adams - Hash Joins OracleDocument15 paginiAdams - Hash Joins Oraclerockerabc123Încă nu există evaluări
- DM DW QBDocument4 paginiDM DW QBM.A rajaÎncă nu există evaluări
- 1 - Unit 1 - Assignment 1 GuidanceDocument3 pagini1 - Unit 1 - Assignment 1 GuidanceNguyen Huu Anh Tuan (FGW HCM)Încă nu există evaluări
- 4.2 Evaluating PolynomialsDocument6 pagini4.2 Evaluating PolynomialsAndrew AndrewÎncă nu există evaluări
- Demonstration of Heap & Quick Sorting Techniques: Presented By: Group No-22, Section-3C Roll No.s-57,16Document11 paginiDemonstration of Heap & Quick Sorting Techniques: Presented By: Group No-22, Section-3C Roll No.s-57,16taniaÎncă nu există evaluări
- Informed SearchDocument43 paginiInformed SearchHassan VilniusÎncă nu există evaluări
- Design and Analysis of AlgorithmDocument48 paginiDesign and Analysis of AlgorithmromeofatimaÎncă nu există evaluări
- Adding - Subtracting.multiplying Polynomials Around The RoomDocument11 paginiAdding - Subtracting.multiplying Polynomials Around The RoomjessicarrudolphÎncă nu există evaluări
- Gauss-Siedel Method: Major: All Engineering Majors Authors: Autar KawDocument35 paginiGauss-Siedel Method: Major: All Engineering Majors Authors: Autar Kawpassword86Încă nu există evaluări
- Aim: To Evaluate A Definite Integral by Simpson's 3/8 Rule AlgorithmDocument3 paginiAim: To Evaluate A Definite Integral by Simpson's 3/8 Rule Algorithmpriyadarshini212007Încă nu există evaluări
- Matrix and Graph Operations in Sparse FormatsDocument44 paginiMatrix and Graph Operations in Sparse FormatsAbhik DasguptaÎncă nu există evaluări
- String Search AlgorithmDocument6 paginiString Search AlgorithmVaishali RaviÎncă nu există evaluări
- Gls University Bca Sem - Iii Data Structure-0301302Document26 paginiGls University Bca Sem - Iii Data Structure-0301302Heet RamiÎncă nu există evaluări
- Computer Oriented Numerical Methods 4Document2 paginiComputer Oriented Numerical Methods 4Theophilus ParateÎncă nu există evaluări
- Lec-6 List ADT & Linked ListsDocument60 paginiLec-6 List ADT & Linked ListsTaqi ShahÎncă nu există evaluări
- OS SRTF Scheduling Algorithm - JavatpointDocument3 paginiOS SRTF Scheduling Algorithm - JavatpointOM PRAKASH GUPTAÎncă nu există evaluări
- Overlap Add SaveDocument8 paginiOverlap Add SaveShailendra BÎncă nu există evaluări
- Practical Programming Algorithms and Data StructuresDocument53 paginiPractical Programming Algorithms and Data StructuresUtsav SinghÎncă nu există evaluări
- Final - Assessment-MOGAJI GABRIEL ROTIMI - R1812D7158691 - UU-COM-3005-42931Document23 paginiFinal - Assessment-MOGAJI GABRIEL ROTIMI - R1812D7158691 - UU-COM-3005-42931CS TECHNOLOGYÎncă nu există evaluări
- ID5059 May 2021 Exam SolutionsDocument6 paginiID5059 May 2021 Exam SolutionsTev WallaceÎncă nu există evaluări
- Alogorithm and DS PG DAC - Aug 19Document34 paginiAlogorithm and DS PG DAC - Aug 19ravi malegaveÎncă nu există evaluări
- Daa Lab SampleDocument79 paginiDaa Lab SampleShiva TejÎncă nu există evaluări