S-ar putea să vă placă și
- Tables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesDe la EverandTables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesÎncă nu există evaluări
- Lec 09Document56 paginiLec 09xuanzhengxie726Încă nu există evaluări
- Lec 16Document15 paginiLec 16Thiago SallesÎncă nu există evaluări
- Test 1 SDocument2 paginiTest 1 SveechowÎncă nu există evaluări
- Slides SignalRepresentationDocument42 paginiSlides SignalRepresentationHuongNguyenÎncă nu există evaluări
- UniversityDocument3 paginiUniversitySudo27Încă nu există evaluări
- 2021 - w3 Math FoundationDocument24 pagini2021 - w3 Math FoundationM. AnggaÎncă nu există evaluări
- Comp Numerical Analysis ProblemsDocument7 paginiComp Numerical Analysis Problemskooobeng6Încă nu există evaluări
- EE263 Homework 3 SolutionsDocument16 paginiEE263 Homework 3 SolutionsLucky DeltaÎncă nu există evaluări
- Lesson 5: First Order Linear Differential Equations: William Mccallum 6 September 2005Document4 paginiLesson 5: First Order Linear Differential Equations: William Mccallum 6 September 2005RaymondÎncă nu există evaluări
- Cheat Sheet MAT230Document4 paginiCheat Sheet MAT230Aly SaeedÎncă nu există evaluări
- Vademecum PROB MLDocument14 paginiVademecum PROB MLanon_57840914Încă nu există evaluări
- Y FX PX FX: Rise RunDocument6 paginiY FX PX FX: Rise RunSage NorrieÎncă nu există evaluări
- MTH4100 Calculus I: Lecture Notes For Week 5 Thomas' Calculus, Sections 2.6 To 3.5 Except 3.3Document10 paginiMTH4100 Calculus I: Lecture Notes For Week 5 Thomas' Calculus, Sections 2.6 To 3.5 Except 3.3Roy VeseyÎncă nu există evaluări
- NLSC Sol Chp2v2Document6 paginiNLSC Sol Chp2v2Jennifer GonzalezÎncă nu există evaluări
- DifferentionDocument4 paginiDifferentionekin.saribasÎncă nu există evaluări
- 3 4 PontryaginDocument36 pagini3 4 PontryaginAbdesselem BoulkrouneÎncă nu există evaluări
- Classes of Operators On Hilbert Spaces Extended Lecture NotesDocument24 paginiClasses of Operators On Hilbert Spaces Extended Lecture Notestalha azanÎncă nu există evaluări
- MSM910 Homework 6 JunjieDocument3 paginiMSM910 Homework 6 JunjieJunjie XuÎncă nu există evaluări
- NumericalDocument20 paginiNumericalClaire TaborÎncă nu există evaluări
- MAST20005 Statistics Assignment 3Document8 paginiMAST20005 Statistics Assignment 3Anonymous na314kKjOAÎncă nu există evaluări
- 11 Sumt PDFDocument11 pagini11 Sumt PDFzikaÎncă nu există evaluări
- 4 - Proof of Existance and Uniqueness of SolutionsDocument12 pagini4 - Proof of Existance and Uniqueness of SolutionsNobody KnowsÎncă nu există evaluări
- Calculus CHAPTER 4Document29 paginiCalculus CHAPTER 4PrivilegeÎncă nu există evaluări
- Modelling Simulation 04Document23 paginiModelling Simulation 04fahmiÎncă nu există evaluări
- Week - 10Document34 paginiWeek - 10riotseeker12Încă nu există evaluări
- Calculus Iii Limits and Continuity of Functions of Two or Three VariablesDocument17 paginiCalculus Iii Limits and Continuity of Functions of Two or Three VariablesMuhammadÎncă nu există evaluări
- Existence Theorems: The Following Optimal Control Problem Has A Globally Optimal SolutionDocument6 paginiExistence Theorems: The Following Optimal Control Problem Has A Globally Optimal SolutionMohammed Abd El Djalil DJEHAFÎncă nu există evaluări
- Differentiation From First PrinciplesDocument3 paginiDifferentiation From First Principleslixus mwangiÎncă nu există evaluări
- Secant and Tangent LinesDocument7 paginiSecant and Tangent LinesAtta AwaisÎncă nu există evaluări
- Limits and ContinuityDocument25 paginiLimits and Continuitypranav kale100% (1)
- Basic DifferentationDocument116 paginiBasic DifferentationJerome Paul Edullantes Diokno-AlfonsoÎncă nu există evaluări
- Stability PDFDocument9 paginiStability PDFSubhasish MahapatraÎncă nu există evaluări
- ClassificationDocument19 paginiClassificationstatyoungÎncă nu există evaluări
- Homework 4: Multivariate Analysis, S. S. Mukherjee, Fall 2018Document7 paginiHomework 4: Multivariate Analysis, S. S. Mukherjee, Fall 2018Durbadal GhoshÎncă nu există evaluări
- Lecture 4: Least SquaresDocument7 paginiLecture 4: Least Squaresbillie quantÎncă nu există evaluări
- Herstein Topics in Algebra Solution 5 3Document9 paginiHerstein Topics in Algebra Solution 5 3NandhiniÎncă nu există evaluări
- Newton's MethodDocument3 paginiNewton's MethodRJ BedañoÎncă nu există evaluări
- Math 122 Duke Day 5 NotesDocument3 paginiMath 122 Duke Day 5 NotesLuke MeredithÎncă nu există evaluări
- ECE 6151, Spring 2017 Lecture Notes 2: 1 Random ProcessDocument9 paginiECE 6151, Spring 2017 Lecture Notes 2: 1 Random ProcessLtarm LamÎncă nu există evaluări
- 2D Geometrical Transformations: Foley & Van Dam, Chapter 5Document34 pagini2D Geometrical Transformations: Foley & Van Dam, Chapter 5Ashutosh JhaÎncă nu există evaluări
- Lecture 11Document11 paginiLecture 11khoinguyennguyendac1Încă nu există evaluări
- ch1 PPTDocument74 paginich1 PPTEFRA BINIÎncă nu există evaluări
- Recitation 11: Based On Nesterov, Yurii. Introductory Lectures On Convex Optimization: A Basic CourseDocument3 paginiRecitation 11: Based On Nesterov, Yurii. Introductory Lectures On Convex Optimization: A Basic CourseRashmi PhadnisÎncă nu există evaluări
- 421HWDocument60 pagini421HWXiomara EscalanteÎncă nu există evaluări
- Preview of "Optimization - PDF"Document20 paginiPreview of "Optimization - PDF"Deepika2669Încă nu există evaluări
- Recitation 11: Based On Nesterov, Yurii. Introductory Lectures On Convex Optimization: A Basic CourseDocument3 paginiRecitation 11: Based On Nesterov, Yurii. Introductory Lectures On Convex Optimization: A Basic CourseRashmi PhadnisÎncă nu există evaluări
- 16.323 Principles of Optimal Control: Mit OpencoursewareDocument26 pagini16.323 Principles of Optimal Control: Mit Opencoursewaremousa bagherpourjahromiÎncă nu există evaluări
- UPSC Civil Services Main 1983 - Mathematics Calculus: Sunder LalDocument7 paginiUPSC Civil Services Main 1983 - Mathematics Calculus: Sunder Lalsayhigaurav07Încă nu există evaluări
- Herstein Topics in Algebra Solution 5 5Document6 paginiHerstein Topics in Algebra Solution 5 5NandhiniÎncă nu există evaluări
- Cee235bpresentation PDE Intro Part 2Document13 paginiCee235bpresentation PDE Intro Part 2delaram88Încă nu există evaluări
- Notes 16 Torsion Prop PDFDocument17 paginiNotes 16 Torsion Prop PDFKucinx GaronkÎncă nu există evaluări
- Mat 771 Functional Analysis Homework 5Document5 paginiMat 771 Functional Analysis Homework 5Yilma ComasÎncă nu există evaluări
- M2C3 Solution of Algebraic and Transcendental Newton Raphson MethodDocument5 paginiM2C3 Solution of Algebraic and Transcendental Newton Raphson MethodRohit Kumar DasÎncă nu există evaluări
- Exercise 8: XX XX X XX XX XX X X XX XXDocument1 paginăExercise 8: XX XX X XX XX XX X X XX XXhoney fatimaÎncă nu există evaluări
- Wazwaz IEch 3 S 2 S 3 P 8Document1 paginăWazwaz IEch 3 S 2 S 3 P 8honey fatimaÎncă nu există evaluări
- 1 Heat Equation On The Plate: Weston BargerDocument9 pagini1 Heat Equation On The Plate: Weston BargerranvÎncă nu există evaluări
- 2017optimalcontrol Solution AprilDocument4 pagini2017optimalcontrol Solution Aprilenrico.michelatoÎncă nu există evaluări
- Pde - T6Q9Document2 paginiPde - T6Q9Bumi BumsÎncă nu există evaluări
- Solutions PMT 2Document6 paginiSolutions PMT 2ankushsemaltiÎncă nu există evaluări
- Fuzzy Logic Control of Energy Storage System in Microgrid OperationDocument6 paginiFuzzy Logic Control of Energy Storage System in Microgrid OperationOmar Zeb KhanÎncă nu există evaluări
- Unit 2: Prevention of Hypertension: Department of Home and Health Sciences Aiou IslamabadDocument55 paginiUnit 2: Prevention of Hypertension: Department of Home and Health Sciences Aiou IslamabadOmar Zeb KhanÎncă nu există evaluări
- List of Provisionally Eligible in Eligible Candidates Inspector KP Police 05 2019Document21 paginiList of Provisionally Eligible in Eligible Candidates Inspector KP Police 05 2019Omar Zeb KhanÎncă nu există evaluări
- Employment Form BPS 17 AdministrationDocument4 paginiEmployment Form BPS 17 AdministrationOmar Zeb KhanÎncă nu există evaluări
- FESCO NTS - Candidate (Portal)Document2 paginiFESCO NTS - Candidate (Portal)Omar Zeb KhanÎncă nu există evaluări
- 04 Fuzzy Relations With ExamplesDocument40 pagini04 Fuzzy Relations With ExamplesOmar Zeb KhanÎncă nu există evaluări
- Nutrition Policy, Healthcare Reforms, and Population Based ChangeDocument48 paginiNutrition Policy, Healthcare Reforms, and Population Based ChangeOmar Zeb KhanÎncă nu există evaluări
- Important Contacts 7Document1 paginăImportant Contacts 7Omar Zeb KhanÎncă nu există evaluări
- Detection and Enumeration of Microbes in Foods: by DR Zaheer AhmedDocument77 paginiDetection and Enumeration of Microbes in Foods: by DR Zaheer AhmedOmar Zeb KhanÎncă nu există evaluări
- Objective: CLC Clear All Close AllDocument3 paginiObjective: CLC Clear All Close AllOmar Zeb KhanÎncă nu există evaluări
- Topic6 - SMC ObserversDocument20 paginiTopic6 - SMC ObserversOmar Zeb KhanÎncă nu există evaluări
- Real-Time Parameter Estimation: Instructor: Dr. Muhammad Jawad KhanDocument30 paginiReal-Time Parameter Estimation: Instructor: Dr. Muhammad Jawad KhanOmar Zeb KhanÎncă nu există evaluări
- 03 Fuzzy Inference SystemDocument47 pagini03 Fuzzy Inference SystemOmar Zeb Khan100% (1)
- 02 Fuzzy Logic and Fuzzy SetsDocument50 pagini02 Fuzzy Logic and Fuzzy SetsOmar Zeb KhanÎncă nu există evaluări
- 1 - Lecture - 5 & 6 - AC - STR PDFDocument47 pagini1 - Lecture - 5 & 6 - AC - STR PDFOmar Zeb KhanÎncă nu există evaluări
- Introduction To Adaptive Control: Instructor: Dr. Muhammad Jawad KhanDocument48 paginiIntroduction To Adaptive Control: Instructor: Dr. Muhammad Jawad KhanOmar Zeb KhanÎncă nu există evaluări
- 01 Fuzzy Logic-Introduction - 13juneDocument28 pagini01 Fuzzy Logic-Introduction - 13juneOmar Zeb KhanÎncă nu există evaluări
- 1 - Lecture - 5 & 6 - AC - RLSEDocument38 pagini1 - Lecture - 5 & 6 - AC - RLSEOmar Zeb KhanÎncă nu există evaluări
- Real-Time Parameter Estimation: Instructor: Dr. Muhammad Jawad KhanDocument30 paginiReal-Time Parameter Estimation: Instructor: Dr. Muhammad Jawad KhanOmar Zeb KhanÎncă nu există evaluări
- Real-Time Parameter Estimation: Instructor: Dr. Muhammad Jawad KhanDocument33 paginiReal-Time Parameter Estimation: Instructor: Dr. Muhammad Jawad KhanOmar Zeb KhanÎncă nu există evaluări
- Topic7 - Chattering AttenuationDocument21 paginiTopic7 - Chattering AttenuationOmar Zeb KhanÎncă nu există evaluări
- Higher Order Sliding Mode Control: Capital University of Science and Technology, IslamabadDocument14 paginiHigher Order Sliding Mode Control: Capital University of Science and Technology, IslamabadOmar Zeb KhanÎncă nu există evaluări
- Introduction To Nonlinear Control Lecture # 6 State Feedback StabilizationDocument56 paginiIntroduction To Nonlinear Control Lecture # 6 State Feedback StabilizationOmar Zeb KhanÎncă nu există evaluări
- Integral Sliding Mode Control: Capital University of Science and Technology, IslamabadDocument16 paginiIntegral Sliding Mode Control: Capital University of Science and Technology, IslamabadOmar Zeb KhanÎncă nu există evaluări
- EE364a Homework 3 Solutions: 0 N 0 1 N N 1 1 N N 0 0Document19 paginiEE364a Homework 3 Solutions: 0 N 0 1 N N 1 1 N N 0 0Omar Zeb KhanÎncă nu există evaluări
- Topic3 - First Order SMCDocument24 paginiTopic3 - First Order SMCOmar Zeb KhanÎncă nu există evaluări
- ME233 Sp16 L19 Least Squares Parameter EstimationDocument49 paginiME233 Sp16 L19 Least Squares Parameter EstimationOmar Zeb KhanÎncă nu există evaluări
- A Survey of Cross-Infection Control Procedures: Knowledge and Attitudes of Turkish DentistsDocument5 paginiA Survey of Cross-Infection Control Procedures: Knowledge and Attitudes of Turkish Dentistsbie2xÎncă nu există evaluări
- Study Abroad at Drexel University, Admission Requirements, Courses, FeesDocument8 paginiStudy Abroad at Drexel University, Admission Requirements, Courses, FeesMy College SherpaÎncă nu există evaluări
- Shur JointDocument132 paginiShur JointCleiton Rodrigues100% (1)
- Listening and Speaking ActivitiesDocument41 paginiListening and Speaking Activitiesdaroksay50% (2)
- PIM-NMB40103 - Course Learning Plan-Jan 2017Document5 paginiPIM-NMB40103 - Course Learning Plan-Jan 2017FirzanÎncă nu există evaluări
- TM11-5855-213-23&P - AN-PVS4 - UNIT AND DIRECT SUPPORT MAINTENANCE MANUAL - 1 - June - 1993Document110 paginiTM11-5855-213-23&P - AN-PVS4 - UNIT AND DIRECT SUPPORT MAINTENANCE MANUAL - 1 - June - 1993hodhodhodsribd100% (1)
- PreDefined VB - Net FunctionsDocument10 paginiPreDefined VB - Net FunctionsMohd NafishÎncă nu există evaluări
- Performance ViceDocument7 paginiPerformance ViceVicente Cortes RuzÎncă nu există evaluări
- Partition AgreementDocument4 paginiPartition AgreementFulgue Joel67% (12)
- Project ReportDocument12 paginiProject ReportSasi DharÎncă nu există evaluări
- Complete Science For Cambridge Lower Secondary PDFDocument2 paginiComplete Science For Cambridge Lower Secondary PDFSultan_Alattaf60% (10)
- Measures of Central Tendency Ungrouped DataDocument4 paginiMeasures of Central Tendency Ungrouped DataLabLab ChattoÎncă nu există evaluări
- Chapter 5 - Launch Vehicle Guidance Present Scenario and Future TrendsDocument20 paginiChapter 5 - Launch Vehicle Guidance Present Scenario and Future TrendsAdrian ToaderÎncă nu există evaluări
- Cost Comp - MF UF Vs TraditionalDocument8 paginiCost Comp - MF UF Vs TraditionalahanraÎncă nu există evaluări
- Vortex MotionDocument6 paginiVortex MotionEreenÎncă nu există evaluări
- DesignationDocument21 paginiDesignationGayl Ignacio TolentinoÎncă nu există evaluări
- Ielts Writing Key Assessment CriteriaDocument4 paginiIelts Writing Key Assessment CriteriaBila TranÎncă nu există evaluări
- B2+ UNIT 10 Test Answer Key HigherDocument2 paginiB2+ UNIT 10 Test Answer Key HigherMOSQUITO beats100% (1)
- NCERT Solutions For Class 12 English Flamingo Chapter 8Document3 paginiNCERT Solutions For Class 12 English Flamingo Chapter 8AKASH KUMARÎncă nu există evaluări
- Research PaperDocument154 paginiResearch Paperleo lokeshÎncă nu există evaluări
- Ridpath History of The United StatesDocument437 paginiRidpath History of The United StatesJohn StrohlÎncă nu există evaluări
- Technical Note - Measurement MicrophonesDocument4 paginiTechnical Note - Measurement MicrophonesWillFonsecaÎncă nu există evaluări
- Health Center LetterDocument2 paginiHealth Center LetterIyah DimalantaÎncă nu există evaluări
- The Eight Types of Interview QuestionsDocument2 paginiThe Eight Types of Interview QuestionsKayla Camille A. Miguel100% (1)
- 1996 Umbra-One-1996Document125 pagini1996 Umbra-One-1996ziggy00zaggyÎncă nu există evaluări
- GradDocument74 paginiGradMoHamedÎncă nu există evaluări
- DAAD WISE Summer Internship ReportDocument2 paginiDAAD WISE Summer Internship ReportVineet Maheshwari100% (1)
- Sample QuestionsDocument6 paginiSample QuestionsKrisleen AbrenicaÎncă nu există evaluări
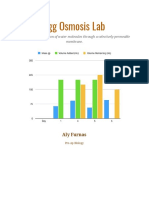
- Egg Osmosis LabDocument5 paginiEgg Osmosis Labapi-391626668Încă nu există evaluări
- V10 - Key (Checked & Apd by Graham)Document4 paginiV10 - Key (Checked & Apd by Graham)HưởngÎncă nu există evaluări