S-ar putea să vă placă și
- Programação Matemática: Otimização Linear e Não LinearDe la EverandProgramação Matemática: Otimização Linear e Não LinearÎncă nu există evaluări
- 06 Estimacao PontualDocument68 pagini06 Estimacao PontualSobre tudo e menos nada100% (1)
- Amostra PilotoDocument6 paginiAmostra Pilotoprofiriojunior100% (1)
- Capitulo 3 - Distribuicoes Amostrais e Estimacao Pontual de Parametros 2Document76 paginiCapitulo 3 - Distribuicoes Amostrais e Estimacao Pontual de Parametros 2isaac LopesÎncă nu există evaluări
- Artigo 65062bc9 ArquivoDocument13 paginiArtigo 65062bc9 ArquivoBruce ChombeÎncă nu există evaluări
- 1 06 Distribuicoes Amostrais PDFDocument49 pagini1 06 Distribuicoes Amostrais PDFWenderson Gomes BarbosaÎncă nu există evaluări
- Capitulo 7 1Document71 paginiCapitulo 7 1Rodrigues Lcn SlarÎncă nu există evaluări
- Minimizando Ramificações em Árvores GeradorasDe la EverandMinimizando Ramificações em Árvores GeradorasÎncă nu există evaluări
- Cap+5 Estimacao+PontualDocument16 paginiCap+5 Estimacao+PontualBeatriz SantosÎncă nu există evaluări
- Teorema Do Limite CentralDocument3 paginiTeorema Do Limite CentralKAROLINE KELLY CUNHA DA SILVAÎncă nu există evaluări
- 5 - EPE - Estimação Pontual e Intervalar - Profº Eduardo Campos - 11-02-14 PDFDocument13 pagini5 - EPE - Estimação Pontual e Intervalar - Profº Eduardo Campos - 11-02-14 PDFCassio MelloÎncă nu există evaluări
- Testes de AderênciaDocument6 paginiTestes de AderênciaCaio CabralÎncă nu există evaluări
- Estimacão EstatísticaDocument10 paginiEstimacão EstatísticaDavid MarquesÎncă nu există evaluări
- Resumo Sobre Análise Estatística de Dados - IVDocument15 paginiResumo Sobre Análise Estatística de Dados - IVRobson Timoteo DamascenoÎncă nu există evaluări
- Aula 05 - Simulação Aplicada À ProduçãoDocument30 paginiAula 05 - Simulação Aplicada À ProduçãoMurilo MottaÎncă nu există evaluări
- A12 ArtigoDocument35 paginiA12 ArtigoBiancaÎncă nu există evaluări
- Seleção de Características em Machine LearningDocument10 paginiSeleção de Características em Machine LearningWALLACE APARECIDO MERCANTEÎncă nu există evaluări
- Metodologia para Análise Quantitativa IRDocument31 paginiMetodologia para Análise Quantitativa IRMarli CorreaÎncă nu există evaluări
- Novos Resultados Sobre A Distribuição Empírica Da Estatística de Teste para o Sensoriamento Espectral Por Sob A Hipótese H1Document4 paginiNovos Resultados Sobre A Distribuição Empírica Da Estatística de Teste para o Sensoriamento Espectral Por Sob A Hipótese H1leonardo lucasÎncă nu există evaluări
- Aula Estimação Do Tamanho Da AmostraDocument44 paginiAula Estimação Do Tamanho Da AmostraRui ChiluluÎncă nu există evaluări
- Trabalho de Estatistica Parte IDocument5 paginiTrabalho de Estatistica Parte Iweresten laquissoneÎncă nu există evaluări
- 03 - E13 - Prop-Namost - SlidesDocument56 pagini03 - E13 - Prop-Namost - SlidesArtur MirandaÎncă nu există evaluări
- Nota de Aula 10 - Distribuição de Frequência em HidrologiaDocument10 paginiNota de Aula 10 - Distribuição de Frequência em HidrologiaLuisa AraújoÎncă nu există evaluări
- Medidas de LocalizaçãoDocument4 paginiMedidas de LocalizaçãoEdu IEPÎncă nu există evaluări
- AmostragemDocument33 paginiAmostragemMaiky Christyan dos Santos MartinsÎncă nu există evaluări
- Livro Técnico - Apostila - de - Estatistica - Aplicada - UNIFEIDocument263 paginiLivro Técnico - Apostila - de - Estatistica - Aplicada - UNIFEIalexandrelymaÎncă nu există evaluări
- Winstat Regressao Polinomial PDFDocument6 paginiWinstat Regressao Polinomial PDFThiago NettoÎncă nu există evaluări
- Estatística ExperimentalDocument3 paginiEstatística ExperimentalRafael VilelaÎncă nu există evaluări
- WeibullDocument20 paginiWeibullCarlosÎncă nu există evaluări
- Introdução A Meta-AnáliseDocument51 paginiIntrodução A Meta-AnáliseAle MeirellesÎncă nu există evaluări
- 03-Conferencia 2 Medidas de ResumoDocument13 pagini03-Conferencia 2 Medidas de Resumorivaldobras99Încă nu există evaluări
- Análise de Dados No RDocument25 paginiAnálise de Dados No RFernanda BeatrizÎncă nu există evaluări
- Morettin e Bussab Estatastica Basica 6 eDocument8 paginiMorettin e Bussab Estatastica Basica 6 ePedro BarcaroloÎncă nu există evaluări
- Cordas Vibrantes - Resultados e DiscussõesDocument6 paginiCordas Vibrantes - Resultados e DiscussõesVinicius BarretoÎncă nu există evaluări
- 1 - IntroduçãoDocument37 pagini1 - IntroduçãoLara Schimith BergheÎncă nu există evaluări
- Infer en CIADocument23 paginiInfer en CIAFabrício Rodrigues Barbosa0% (2)
- CCSA - Centro de Ciências Sociais e Aplicadas: Universidade Presbiteriana MackenzieDocument19 paginiCCSA - Centro de Ciências Sociais e Aplicadas: Universidade Presbiteriana MackenzieWendell RochaÎncă nu există evaluări
- ApostilaDocument205 paginiApostilaLetícia Schneider Ferrari0% (1)
- Ciência de Dados - Clustering - Cap5Document40 paginiCiência de Dados - Clustering - Cap5JoséÎncă nu există evaluări
- 02-CTP Processamento Dos DadosDocument14 pagini02-CTP Processamento Dos Dadosrivaldobras99Încă nu există evaluări
- Conceitos Estatistica InferencialDocument7 paginiConceitos Estatistica InferencialISABELA RITA DOS SANTOS ROSSIÎncă nu există evaluări
- Nidade: Estimação de ParâmetrosDocument24 paginiNidade: Estimação de ParâmetrosRodrigues Lcn SlarÎncă nu există evaluări
- Capítulo IV - Estimação de Parâmetros-MateriaisDocument12 paginiCapítulo IV - Estimação de Parâmetros-Materiaisnicolas25garcia2002Încă nu există evaluări
- Trabalho para Segunda AvaliaçãoDocument6 paginiTrabalho para Segunda AvaliaçãoJeferson LuizÎncă nu există evaluări
- Probabilidade e Estatística - 01 - 27-09-2021Document12 paginiProbabilidade e Estatística - 01 - 27-09-2021PAULA TEIXEIRA DOS SANTOSÎncă nu există evaluări
- Aula 1 2o Sem - Estatistica - 2017 - Parte 1Document42 paginiAula 1 2o Sem - Estatistica - 2017 - Parte 1Deivison FelicianoÎncă nu există evaluări
- Aula Caracterizao 1Document34 paginiAula Caracterizao 1Igor HenriqueÎncă nu există evaluări
- Atividades de Dados CategóricosDocument11 paginiAtividades de Dados CategóricosFrancisco Huemerson de Sousa PintoÎncă nu există evaluări
- Aula 1 1o Sem Estatistica 2020 Parte 2Document45 paginiAula 1 1o Sem Estatistica 2020 Parte 2Carlos Alberto SouzaÎncă nu există evaluări
- Estatistica CCM NA5Document23 paginiEstatistica CCM NA5Josias-aaaÎncă nu există evaluări
- 3461-Texto Do Artigo-7007-1-10-20190909Document5 pagini3461-Texto Do Artigo-7007-1-10-20190909Dionisio NetoÎncă nu există evaluări
- EstimacaoDocument4 paginiEstimacaoHeitor AlvesÎncă nu există evaluări
- Est at Is Tic ADocument263 paginiEst at Is Tic AKlew Cleudiney Theodoro Brandão0% (2)
- Aula - Inferência EstatísticaDocument98 paginiAula - Inferência EstatísticaAndressa ImprotaÎncă nu există evaluări
- Ee FD 05 ConversaodeenergiaDocument3 paginiEe FD 05 ConversaodeenergiaWesley de PaulaÎncă nu există evaluări
- Modelo de Ebers MollDocument1 paginăModelo de Ebers MollWesley de PaulaÎncă nu există evaluări
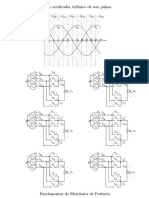
- Gabarito 6pulsosDocument1 paginăGabarito 6pulsosWesley de PaulaÎncă nu există evaluări
- Questionário de Revisão Sobre TransformadoresDocument2 paginiQuestionário de Revisão Sobre TransformadoresWesley de PaulaÎncă nu există evaluări
- Aula5 Interruptorsimples2 3 Secoes Paralelo PDFDocument18 paginiAula5 Interruptorsimples2 3 Secoes Paralelo PDFWesley de PaulaÎncă nu există evaluări
- CCCDocument95 paginiCCCWesley de PaulaÎncă nu există evaluări
- Cap InvDocument24 paginiCap InvWesley de PaulaÎncă nu există evaluări
- Aplicacao de Paralelismo de Mosfet de Potencia em Conversores Quase RessonantesDocument8 paginiAplicacao de Paralelismo de Mosfet de Potencia em Conversores Quase RessonantesWesley de PaulaÎncă nu există evaluări
- Lista de EstatisticaDocument8 paginiLista de EstatisticaGuilherme Da SilÎncă nu există evaluări
- Apostila de GeoestatisticaDocument78 paginiApostila de Geoestatisticaagnobel dantas silva100% (2)
- Modelagem de Equações Estruturais No Software RDocument89 paginiModelagem de Equações Estruturais No Software RDaniloCastroLopesOliveiraÎncă nu există evaluări
- Exemplos 6Document5 paginiExemplos 6Diogo LucenaÎncă nu există evaluări
- (Livro Completo) Ler e Apresentar Artigos Científicos - André Azeredo e Lucas Primo - EBM Academy 2020Document74 pagini(Livro Completo) Ler e Apresentar Artigos Científicos - André Azeredo e Lucas Primo - EBM Academy 2020Brena100% (1)
- 3 O Erro de MediçãoDocument69 pagini3 O Erro de MediçãoRosineia BergamaschiÎncă nu există evaluări
- Propriedades Dos EstimadoresDocument5 paginiPropriedades Dos EstimadoresMarcelo SantosÎncă nu există evaluări
- ConfiabilidadeDocument128 paginiConfiabilidadeNicolas De NadaiÎncă nu există evaluări
- Mae311 l3Document11 paginiMae311 l3Wyara Vanesa MouraÎncă nu există evaluări
- Censo Demográfico 2000: Documentação Dos Microdados Da AmostraDocument165 paginiCenso Demográfico 2000: Documentação Dos Microdados Da AmostraclralexÎncă nu există evaluări
- Notas de Aula SignificanciaDocument10 paginiNotas de Aula SignificanciaJessica de AbreuÎncă nu există evaluări
- Cap 3Document90 paginiCap 3RÎncă nu există evaluări
- Monografia Defendida - Jonas VilanculosDocument52 paginiMonografia Defendida - Jonas VilanculosJustinoNatalino100% (1)
- Analise de RegressãoDocument24 paginiAnalise de RegressãofernandacbpereiraÎncă nu există evaluări
- Estimação PontualDocument40 paginiEstimação PontualFátima SalgadoÎncă nu există evaluări
- TP2 - Erros em Química Analítica e Tratamento de ResultadosDocument6 paginiTP2 - Erros em Química Analítica e Tratamento de ResultadosJoao Filipe Pereira Azevedo Aluno AECA 2020-21Încă nu există evaluări
- Apostila 1 - Importância Da Estatística e Conceitos BásicosDocument9 paginiApostila 1 - Importância Da Estatística e Conceitos BásicosAllan Reis100% (11)
- ArquivoDocument9 paginiArquivoCarlos Alberto VasquezÎncă nu există evaluări
- Nit-Dicla-21 - 04 - Expressão Da Incerteza de Medição - InmetroDocument29 paginiNit-Dicla-21 - 04 - Expressão Da Incerteza de Medição - InmetroluroguitaÎncă nu există evaluări
- PERT ProbabilísticoDocument13 paginiPERT ProbabilísticoFrederico de AlmeidaÎncă nu există evaluări
- Ajustamento de ObservaçõesDocument95 paginiAjustamento de ObservaçõesGelito_MarcosÎncă nu există evaluări
- Fascículo de Estatística Descritiva 2 Ano Enfermagem 2023Document47 paginiFascículo de Estatística Descritiva 2 Ano Enfermagem 2023Nobrigas AlfredoÎncă nu există evaluări
- Exercicios ResolvidosDocument28 paginiExercicios ResolvidosThiago SouzaÎncă nu există evaluări
- 2.2 Cálculos Da Regressão Dos Mínimos QuadradosDocument22 pagini2.2 Cálculos Da Regressão Dos Mínimos QuadradossergioÎncă nu există evaluări
- Econometria - Aula 02Document55 paginiEconometria - Aula 02Michel TagimaÎncă nu există evaluări
- Exerci Cio 4Document3 paginiExerci Cio 4Luciane Silva Marques100% (1)
- Estimadores de Máxima Verossimilhança - Inferência - Portal ActionDocument3 paginiEstimadores de Máxima Verossimilhança - Inferência - Portal ActionFábio Constancio Almeida da SilvaÎncă nu există evaluări
- Estimação PontualDocument5 paginiEstimação PontualjosueÎncă nu există evaluări
- Aula Anlise de VarinciaDocument34 paginiAula Anlise de Varinciaarthurgds4Încă nu există evaluări
- Exercicios Mat2215Document16 paginiExercicios Mat2215Andressa FariasÎncă nu există evaluări