S-ar putea să vă placă și
- Oracle Data Integrator Installation GuideDocument47 paginiOracle Data Integrator Installation GuideAmit Sharma100% (1)
- Practitioners Guide For Business Development Planning in FPOsDocument70 paginiPractitioners Guide For Business Development Planning in FPOsMythreyi ChichulaÎncă nu există evaluări
- Web TechnologyDocument338 paginiWeb TechnologyAnshuman ShuklaÎncă nu există evaluări
- Huawei Core Roadmap TRM10 Dec 14 2011 FinalDocument70 paginiHuawei Core Roadmap TRM10 Dec 14 2011 Finalfirasibraheem100% (1)
- Oracle Information Integration, Migration, and ConsolidationDe la EverandOracle Information Integration, Migration, and ConsolidationÎncă nu există evaluări
- Product Guide TrioDocument32 paginiProduct Guide Triomarcosandia1974Încă nu există evaluări
- Semantic Web IntroductionDocument35 paginiSemantic Web IntroductionkhongminhphongÎncă nu există evaluări
- Integration Research and Design of The Bridge Maintenance Management SystemDocument6 paginiIntegration Research and Design of The Bridge Maintenance Management SystemSanket NaikÎncă nu există evaluări
- LRam (4,0)Document5 paginiLRam (4,0)Amardeep VishwakarmaÎncă nu există evaluări
- Research On The SCADA System Constructing MethodolDocument6 paginiResearch On The SCADA System Constructing Methodoldarshan bsÎncă nu există evaluări
- ETCW03Document3 paginiETCW03Editor IJAERDÎncă nu există evaluări
- Spe-195629-Ms Openlab: Design and Applications of A Modern Drilling Digitalization InfrastructureDocument22 paginiSpe-195629-Ms Openlab: Design and Applications of A Modern Drilling Digitalization InfrastructureSave NatureÎncă nu există evaluări
- Implementing Semantic Web Applications: Reference Architecture and ChallengesDocument15 paginiImplementing Semantic Web Applications: Reference Architecture and ChallengesAland MediaÎncă nu există evaluări
- Web Scraping With Python and Selenium: Sarah Fatima, Shaik Luqmaan Nuha Abdul RasheedDocument5 paginiWeb Scraping With Python and Selenium: Sarah Fatima, Shaik Luqmaan Nuha Abdul RasheedVanessa DouradoÎncă nu există evaluări
- 5.IJAEST Vol No 7 Issue No 2 APaaS Technology To Build Workflow Based Applications 212 216Document5 pagini5.IJAEST Vol No 7 Issue No 2 APaaS Technology To Build Workflow Based Applications 212 216helpdesk9532Încă nu există evaluări
- BTP ReportDocument14 paginiBTP ReportLakshaya TeotiaÎncă nu există evaluări
- Exam Seating ArrangementDocument3 paginiExam Seating ArrangementrjoshittaÎncă nu există evaluări
- R18a0517 Web Technologies MallareddyDocument141 paginiR18a0517 Web Technologies Mallareddysudheerbarri21Încă nu există evaluări
- Cloudbook WebsiteDocument13 paginiCloudbook WebsiteIJRASETPublicationsÎncă nu există evaluări
- Java Web FrameworkDocument5 paginiJava Web FrameworkAlfian AkbarÎncă nu există evaluări
- SOA SyllabusDocument3 paginiSOA SyllabusDeepa LakshmiÎncă nu există evaluări
- Java Web MVC Frameworks: Background, Taxonomy, and Examples: M.Sc. Certificate ModuleDocument60 paginiJava Web MVC Frameworks: Background, Taxonomy, and Examples: M.Sc. Certificate ModulerolzagÎncă nu există evaluări
- ch-3 AJDocument26 paginich-3 AJDhrutik PadashalaÎncă nu există evaluări
- Roshan ResumeDocument3 paginiRoshan ResumeRicha MalhotraÎncă nu există evaluări
- Testing Web Database Applications: Yuetang Deng Phyllis Frankl Jiong WangDocument12 paginiTesting Web Database Applications: Yuetang Deng Phyllis Frankl Jiong WangSrinivas RaoÎncă nu există evaluări
- Real-Time Auction Service Application Based On Frameworks Available For J2EE PlatformDocument5 paginiReal-Time Auction Service Application Based On Frameworks Available For J2EE Platformskumar51907740Încă nu există evaluări
- Semantic Technologies in The SIMDAT Grid Project: Application Specific Adaptions Application Specific AdaptionsDocument3 paginiSemantic Technologies in The SIMDAT Grid Project: Application Specific Adaptions Application Specific Adaptionshyoung65Încă nu există evaluări
- IRJMETS Research PaperDocument5 paginiIRJMETS Research PaperkrishÎncă nu există evaluări
- Resume Mar 2010 ArchitectDocument5 paginiResume Mar 2010 ArchitectSudarsan SridharanÎncă nu există evaluări
- Project Report Text Editor in JavaDocument10 paginiProject Report Text Editor in JavaKuldeep SharmaÎncă nu există evaluări
- " Haryana Engineering College ": Minor ProjectDocument6 pagini" Haryana Engineering College ": Minor ProjectAkhil KumarÎncă nu există evaluări
- Fin Irjmets1686210967Document4 paginiFin Irjmets1686210967Yemar MekuantÎncă nu există evaluări
- Project Report Gym-1Document7 paginiProject Report Gym-1Ishu SainiÎncă nu există evaluări
- An Effective Web Usage Analysis Using Fuzzy Clustering: P.Nithya, P.SumathiDocument6 paginiAn Effective Web Usage Analysis Using Fuzzy Clustering: P.Nithya, P.SumathimerrinÎncă nu există evaluări
- Comparative Analysis On Front-End Frameworks For Web ApplicationsDocument12 paginiComparative Analysis On Front-End Frameworks For Web ApplicationsIJRASETPublicationsÎncă nu există evaluări
- Automation of Open Electives: IarjsetDocument6 paginiAutomation of Open Electives: Iarjsetshashank trvvietÎncă nu există evaluări
- A Technical Report of RagaDocument17 paginiA Technical Report of RagaRamya SurviÎncă nu există evaluări
- 1 s2.0 S0164121219300408 MainDocument15 pagini1 s2.0 S0164121219300408 MainArtur WodołazskiÎncă nu există evaluări
- (Techtutus4U) : Major Project ReportDocument55 pagini(Techtutus4U) : Major Project ReportAndrew MartinÎncă nu există evaluări
- Resume DiveDocument2 paginiResume Divelomesh021Încă nu există evaluări
- SQL Injection Attack and Guard Technical Research: $Gydqfhglq&Rqwuro (Qjlqhhulqjdqg, Qirupdwlrq6FlhqfhDocument5 paginiSQL Injection Attack and Guard Technical Research: $Gydqfhglq&Rqwuro (Qjlqhhulqjdqg, Qirupdwlrq6FlhqfhPramono PramonoÎncă nu există evaluări
- E-Commerce Development Using AngularJS Framework ADocument11 paginiE-Commerce Development Using AngularJS Framework AMinh TrịnhÎncă nu există evaluări
- A Soa Based E-Learning System For Teaching Fundamental Informations of Computer Science CoursesDocument5 paginiA Soa Based E-Learning System For Teaching Fundamental Informations of Computer Science Coursesijbui iirÎncă nu există evaluări
- Design of E-Learning System Using Service Oriented Architecture (SOA)Document50 paginiDesign of E-Learning System Using Service Oriented Architecture (SOA)Akash KumarÎncă nu există evaluări
- EJ Question BankDocument4 paginiEJ Question BankPrince Aryan KhanÎncă nu există evaluări
- Oracle: Jagannath Gupta Institute of Engineering & TechnologyDocument51 paginiOracle: Jagannath Gupta Institute of Engineering & TechnologyAnkush TankÎncă nu există evaluări
- Implement of CAD/CAM/CAE Integrated Technology For Out Shell of Digital CameraDocument5 paginiImplement of CAD/CAM/CAE Integrated Technology For Out Shell of Digital CameraSureshKumarÎncă nu există evaluări
- Firedetective: Understanding Ajax Client/Server InteractionsDocument8 paginiFiredetective: Understanding Ajax Client/Server InteractionsBalsasaÎncă nu există evaluări
- Mohammed: 2-MG-ORAINS-966-EG: Name CodeDocument12 paginiMohammed: 2-MG-ORAINS-966-EG: Name Codea.elcobtanÎncă nu există evaluări
- Kevin Nil Son ResumeDocument6 paginiKevin Nil Son Resumecosmo100% (1)
- A Study of Pattern Analysis Techniques of Web UsageDocument4 paginiA Study of Pattern Analysis Techniques of Web Usageijbui iirÎncă nu există evaluări
- Selva KumarDocument10 paginiSelva Kumarselvaatusa100% (2)
- ADBL Project Report (11,12,20)Document6 paginiADBL Project Report (11,12,20)Avanish TiwariÎncă nu există evaluări
- Semantic Approach For Improving Pattern Quality in Web Usage MiningDocument7 paginiSemantic Approach For Improving Pattern Quality in Web Usage MiningVaibhav SawantÎncă nu există evaluări
- An Effective Query System Using Llms and Langchain IJERTV12IS060161Document3 paginiAn Effective Query System Using Llms and Langchain IJERTV12IS060161Suriya Suresh KarthikeyanÎncă nu există evaluări
- Design and Implementation Issues For Modern Remote LaboratoriesDocument13 paginiDesign and Implementation Issues For Modern Remote LaboratoriesdiegoantivirusÎncă nu există evaluări
- Implementing Semantic Web Applications Reference ADocument16 paginiImplementing Semantic Web Applications Reference ALincolnÎncă nu există evaluări
- Oracle Data Integrator Architecture: RepositoriesDocument5 paginiOracle Data Integrator Architecture: Repositoriesrujuta_kulkarni_2Încă nu există evaluări
- Migrate To AJAXDocument14 paginiMigrate To AJAXSivaraman ViswanathanÎncă nu există evaluări
- Traffic Engineering in Software-Defined NetworkingDocument12 paginiTraffic Engineering in Software-Defined NetworkingJamilCerezoÎncă nu există evaluări
- Java/J2EE Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesDe la EverandJava/J2EE Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesÎncă nu există evaluări
- Research Proposal IntroductionDocument8 paginiResearch Proposal IntroductionIsaac OmwengaÎncă nu există evaluări
- Unit 5 Andhra Pradesh.Document18 paginiUnit 5 Andhra Pradesh.Charu ModiÎncă nu există evaluări
- Codex Standard EnglishDocument4 paginiCodex Standard EnglishTriyaniÎncă nu există evaluări
- Case Notes All Cases Family II TermDocument20 paginiCase Notes All Cases Family II TermRishi Aneja100% (1)
- SDFGHJKL ÑDocument2 paginiSDFGHJKL ÑAlexis CaluñaÎncă nu există evaluări
- 0063 - Proforma Accompanying The Application For Leave WITHOUT ALLOWANCE Is FORWARDED To GOVERNMEDocument4 pagini0063 - Proforma Accompanying The Application For Leave WITHOUT ALLOWANCE Is FORWARDED To GOVERNMESreedharanPN100% (4)
- Frigidaire Parts and Accessories CatalogDocument56 paginiFrigidaire Parts and Accessories CatalogPedro RuizÎncă nu există evaluări
- Intelligent Smoke & Heat Detectors: Open, Digital Protocol Addressed by The Patented XPERT Card Electronics Free BaseDocument4 paginiIntelligent Smoke & Heat Detectors: Open, Digital Protocol Addressed by The Patented XPERT Card Electronics Free BaseBabali MedÎncă nu există evaluări
- A Survey On Multicarrier Communications Prototype PDFDocument28 paginiA Survey On Multicarrier Communications Prototype PDFDrAbdallah NasserÎncă nu există evaluări
- Bismillah SpeechDocument2 paginiBismillah SpeechanggiÎncă nu există evaluări
- MCS Valve: Minimizes Body Washout Problems and Provides Reliable Low-Pressure SealingDocument4 paginiMCS Valve: Minimizes Body Washout Problems and Provides Reliable Low-Pressure SealingTerry SmithÎncă nu există evaluări
- Question Bank For Vlsi LabDocument4 paginiQuestion Bank For Vlsi LabSav ThaÎncă nu există evaluări
- Circuitos Digitales III: #IncludeDocument2 paginiCircuitos Digitales III: #IncludeCristiamÎncă nu există evaluări
- Brochure 2017Document44 paginiBrochure 2017bibiana8593Încă nu există evaluări
- Copeland PresentationDocument26 paginiCopeland Presentationjai soniÎncă nu există evaluări
- Gmo EssayDocument4 paginiGmo Essayapi-270707439Încă nu există evaluări
- SettingsDocument3 paginiSettingsrusil.vershÎncă nu există evaluări
- Dmta 20043 01en Omniscan SX UserDocument90 paginiDmta 20043 01en Omniscan SX UserwenhuaÎncă nu există evaluări
- Data Sheet: Elcometer 108 Hydraulic Adhesion TestersDocument3 paginiData Sheet: Elcometer 108 Hydraulic Adhesion TesterstilanfernandoÎncă nu există evaluări
- Ramp Footing "RF" Wall Footing-1 Detail: Blow-Up Detail "B"Document2 paginiRamp Footing "RF" Wall Footing-1 Detail: Blow-Up Detail "B"Genevieve GayosoÎncă nu există evaluări
- FBW Manual-Jan 2012-Revised and Corrected CS2Document68 paginiFBW Manual-Jan 2012-Revised and Corrected CS2Dinesh CandassamyÎncă nu există evaluări
- HP Sustainability Impact Report 2018Document147 paginiHP Sustainability Impact Report 2018Rinaldo loboÎncă nu există evaluări
- PHP IntroductionDocument113 paginiPHP Introductionds0909@gmailÎncă nu există evaluări
- Kicks: This Brochure Reflects The Product Information For The 2020 Kicks. 2021 Kicks Brochure Coming SoonDocument8 paginiKicks: This Brochure Reflects The Product Information For The 2020 Kicks. 2021 Kicks Brochure Coming SoonYudyChenÎncă nu există evaluări
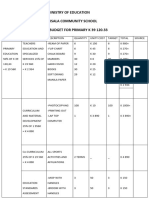
- Ministry of Education Musala SCHDocument5 paginiMinistry of Education Musala SCHlaonimosesÎncă nu există evaluări
- Political Positions of Pete ButtigiegDocument12 paginiPolitical Positions of Pete ButtigiegFuzz FuzzÎncă nu există evaluări
- XI STD Economics Vol-1 EM Combined 12.10.18 PDFDocument288 paginiXI STD Economics Vol-1 EM Combined 12.10.18 PDFFebin Kurian Francis0% (1)