S-ar putea să vă placă și
- Evolutionary Algorithms for Food Science and TechnologyDe la EverandEvolutionary Algorithms for Food Science and TechnologyÎncă nu există evaluări
- RV College of Engineering, Bengaluru-59: Self-Study Component-2Document20 paginiRV College of Engineering, Bengaluru-59: Self-Study Component-2Alishare Muhammed AkramÎncă nu există evaluări
- All Types of Cross ValidationDocument9 paginiAll Types of Cross ValidationPriya dharshini.GÎncă nu există evaluări
- Assignment 1:: Intro To Machine LearningDocument6 paginiAssignment 1:: Intro To Machine LearningMinh TríÎncă nu există evaluări
- Experiment 2.2 KNN ClassifierDocument7 paginiExperiment 2.2 KNN ClassifierArslan MansooriÎncă nu există evaluări
- Solution HW2Document6 paginiSolution HW2prakshiÎncă nu există evaluări
- Machine Learning AssignmentDocument2 paginiMachine Learning AssignmentNikhilesh RajaramanÎncă nu există evaluări
- 20mid0209 Lab - 6Document11 pagini20mid0209 Lab - 6R B SHARANÎncă nu există evaluări
- Ps 3Document3 paginiPs 3Annas MutiaraÎncă nu există evaluări
- Sentiment Analysis On TweetsDocument2 paginiSentiment Analysis On TweetsvikibytesÎncă nu există evaluări
- Tutorial 6Document8 paginiTutorial 6POEASOÎncă nu există evaluări
- Coincent - Data Science With Python AssignmentDocument23 paginiCoincent - Data Science With Python AssignmentSai Nikhil Nellore100% (2)
- Problem StatementDocument1 paginăProblem StatementBrianearlÎncă nu există evaluări
- Design of Experiments For The NIPS 2003 Variable Selection BenchmarkDocument30 paginiDesign of Experiments For The NIPS 2003 Variable Selection BenchmarkBayu Adhi NugrohoÎncă nu există evaluări
- UntitledDocument95 paginiUntitledSyed Hunain AliÎncă nu există evaluări
- Ell409 AqDocument8 paginiEll409 Aqlovlesh royÎncă nu există evaluări
- Regression Assg1Document2 paginiRegression Assg1rishib3003Încă nu există evaluări
- AIML Exp 9Document8 paginiAIML Exp 9Kartik GuleriaÎncă nu există evaluări
- ResultsDocument4 paginiResultsSeif MechtiÎncă nu există evaluări
- Final Project ReportDocument18 paginiFinal Project ReportjstpallavÎncă nu există evaluări
- PROPOSED SYSTEM - Google Docs 1 PDFDocument3 paginiPROPOSED SYSTEM - Google Docs 1 PDFJayadev HÎncă nu există evaluări
- COL 774: Assignment 2Document3 paginiCOL 774: Assignment 2Aditya KumarÎncă nu există evaluări
- CHAPTER 4 DiabetesDocument6 paginiCHAPTER 4 DiabetesSRPC ECEÎncă nu există evaluări
- TD2345Document3 paginiTD2345ashitaka667Încă nu există evaluări
- Vijaya MLDocument26 paginiVijaya MLVijayalakshmi Palaniappan83% (6)
- Week10 KNN PracticalDocument4 paginiWeek10 KNN Practicalseerungen jordiÎncă nu există evaluări
- Decision Trees and Random ForestsDocument25 paginiDecision Trees and Random ForestsAlexandra VeresÎncă nu există evaluări
- Team Alacrity - Amazon ML Challenge 2023 - Text FileDocument8 paginiTeam Alacrity - Amazon ML Challenge 2023 - Text Fileomkar sameer chaubalÎncă nu există evaluări
- ML Experiment No 06Document13 paginiML Experiment No 06Piyush HoodÎncă nu există evaluări
- Final Stage For Cocomo Using PCADocument8 paginiFinal Stage For Cocomo Using PCAVikas MahurkarÎncă nu există evaluări
- Assignment1 COMP723 2019Document4 paginiAssignment1 COMP723 2019imran5705074Încă nu există evaluări
- Python LearningDocument21 paginiPython LearningVinayÎncă nu există evaluări
- ML Module IiiDocument12 paginiML Module IiiCrazy ChethanÎncă nu există evaluări
- Assignment 5 1Document13 paginiAssignment 5 1Unnati ThakkarÎncă nu există evaluări
- XSTK Câu hỏiDocument19 paginiXSTK Câu hỏiimaboneofmyswordÎncă nu există evaluări
- Features ElectionDocument18 paginiFeatures ElectionAlokÎncă nu există evaluări
- Description: Hint: Perform Steps As Mentioned BelowDocument11 paginiDescription: Hint: Perform Steps As Mentioned BelowAnish Kumar100% (1)
- COM4509/6509 MLAI - Assignment Part 2 Brief: This Link This LinkDocument5 paginiCOM4509/6509 MLAI - Assignment Part 2 Brief: This Link This LinkSyed AbdulllahÎncă nu există evaluări
- (Lab4) CNNDocument2 pagini(Lab4) CNNprojectdirectorÎncă nu există evaluări
- Data Mining Models and Evaluation TechniquesDocument59 paginiData Mining Models and Evaluation Techniquesspsberry8Încă nu există evaluări
- Machine LearningDocument56 paginiMachine LearningMani Vrs100% (3)
- Report AIDocument7 paginiReport AIIQRA IMRANÎncă nu există evaluări
- Ai HW1Document25 paginiAi HW1Minh NguyễnÎncă nu există evaluări
- Data Mining - Weka 3.6.0Document5 paginiData Mining - Weka 3.6.0Navee JayakodyÎncă nu există evaluări
- Rev Insurance Business ReportDocument4 paginiRev Insurance Business ReportPratigya pathakÎncă nu există evaluări
- Project - Machine Learning-Business Report: By: K Ravi Kumar PGP-Data Science and Business Analytics (PGPDSBA.O.MAR23.A)Document38 paginiProject - Machine Learning-Business Report: By: K Ravi Kumar PGP-Data Science and Business Analytics (PGPDSBA.O.MAR23.A)Ravi KotharuÎncă nu există evaluări
- Programming With R Test 2Document5 paginiProgramming With R Test 2KamranKhan50% (2)
- Lab3Block1 2021-1Document3 paginiLab3Block1 2021-1Alex WidénÎncă nu există evaluări
- Assignment 3 Q1Document5 paginiAssignment 3 Q1PratyushÎncă nu există evaluări
- Lab 5Document2 paginiLab 5Daejuswaram GopinathÎncă nu există evaluări
- Introduction To Machine Learning: K-Nearest Neighbors: Zhongheng ZhangDocument7 paginiIntroduction To Machine Learning: K-Nearest Neighbors: Zhongheng ZhangEthan MananiÎncă nu există evaluări
- TwoStep Cluster AnalysisDocument19 paginiTwoStep Cluster Analysisana santosÎncă nu există evaluări
- Assignment 3 Pattern RecognistionDocument2 paginiAssignment 3 Pattern RecognistionShahzad IqbalÎncă nu există evaluări
- Scikit LearnDocument17 paginiScikit LearnRRÎncă nu există evaluări
- ML Project Shivani PandeyDocument49 paginiML Project Shivani PandeyShubhangi Pandey100% (2)
- A Short Introduction To CaretDocument10 paginiA Short Introduction To CaretblacngÎncă nu există evaluări
- Statistical Learning Master ReportsDocument11 paginiStatistical Learning Master ReportsValentina Mendoza ZamoraÎncă nu există evaluări
- Assignment 3 - LP1Document13 paginiAssignment 3 - LP1bbad070105Încă nu există evaluări
- Week 7 Laboratory ActivityDocument12 paginiWeek 7 Laboratory ActivityGar NoobÎncă nu există evaluări
- Machine Learning NotesDocument6 paginiMachine Learning NotesNikhita NairÎncă nu există evaluări
- Package Jsonlite': R Topics DocumentedDocument14 paginiPackage Jsonlite': R Topics DocumentedAdilson KhouriÎncă nu există evaluări
- Customer Churn Prediction Project: Group CDocument12 paginiCustomer Churn Prediction Project: Group CRohit NÎncă nu există evaluări
- JukicDocument18 paginiJukicAman SinghÎncă nu există evaluări
- Data Engineering With Databricks DaDocument232 paginiData Engineering With Databricks Davitlesh.sfÎncă nu există evaluări
- PracticalsDocument72 paginiPracticalsprogrammer100% (1)
- Final-Exam MathDocument8 paginiFinal-Exam MathJeybi SedilloÎncă nu există evaluări
- Literature Review Synthesis AnalysisDocument7 paginiLiterature Review Synthesis Analysisc5ryek5a100% (1)
- Excel Factor 17 Lookup and Return Multiple MatchesDocument5 paginiExcel Factor 17 Lookup and Return Multiple MatchessalehgigÎncă nu există evaluări
- 07.IBM DeepFlash Sales Education v1.2Document36 pagini07.IBM DeepFlash Sales Education v1.2sherpard muzuvaÎncă nu există evaluări
- Cross Reference ThesisDocument7 paginiCross Reference Thesismariapolitepalmdale100% (2)
- Intermec Printer Language IPL Developers Guide Old PDFDocument112 paginiIntermec Printer Language IPL Developers Guide Old PDFira_ferÎncă nu există evaluări
- Adams - Hash Joins OracleDocument15 paginiAdams - Hash Joins Oraclerockerabc123Încă nu există evaluări
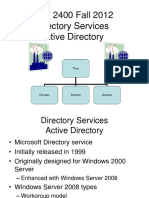
- 01-Introduction To Active DirectoryDocument24 pagini01-Introduction To Active DirectoryUwintije Jean PaulÎncă nu există evaluări
- Making Sense of The Semantic Web: Nova Spivack CEO & Founder Radar NetworksDocument36 paginiMaking Sense of The Semantic Web: Nova Spivack CEO & Founder Radar NetworksRocelle UriarteÎncă nu există evaluări
- User Manual For FDC 2.1Document13 paginiUser Manual For FDC 2.1Jeni FragaÎncă nu există evaluări
- NSA CSI-SCRM-SBOM-Management-v1.1 Jan Update 20240104Document14 paginiNSA CSI-SCRM-SBOM-Management-v1.1 Jan Update 20240104Luis Enrique TorresÎncă nu există evaluări
- TechnicalDocument97 paginiTechnicalsekharansixÎncă nu există evaluări
- Database Programming With PL/SQL 6-1: Practice Activities: Introduction To Explicit CursorsDocument5 paginiDatabase Programming With PL/SQL 6-1: Practice Activities: Introduction To Explicit CursorsMohammad AlomariÎncă nu există evaluări
- What Is Research PDFDocument12 paginiWhat Is Research PDFMatevz ArconÎncă nu există evaluări
- Executive Profile Core Competencies: Manoj Mohandas MenonDocument2 paginiExecutive Profile Core Competencies: Manoj Mohandas MenonAnisha KoushalÎncă nu există evaluări
- Oracle Quality SetupDocument10 paginiOracle Quality Setupapi-3717169100% (6)
- SoalDocument63 paginiSoalRhydo SwagerÎncă nu există evaluări
- Dabur+vatika+shampoo+project Docx1Document82 paginiDabur+vatika+shampoo+project Docx1Faisal ZakariaÎncă nu există evaluări
- 1 - Introduction To Database SystemsDocument38 pagini1 - Introduction To Database Systemscharanika23Încă nu există evaluări
- Program: B.Tech Course: Cse2004 - Dbms Database Management Systems Lab Cycle Sheet 2Document5 paginiProgram: B.Tech Course: Cse2004 - Dbms Database Management Systems Lab Cycle Sheet 2Namratha ThataÎncă nu există evaluări
- SQL LDocument62 paginiSQL LShiva Sena ChowhanÎncă nu există evaluări
- Er+Mapping+ Normalization: Group - 6Document9 paginiEr+Mapping+ Normalization: Group - 619Z337 - PAVITHRA YAZHINI G KÎncă nu există evaluări
- CO4703 Assignment Brief 2020-2021Document6 paginiCO4703 Assignment Brief 2020-2021M shayan JavedÎncă nu există evaluări
- MSGTXT TBLDocument19 paginiMSGTXT TBLsravanÎncă nu există evaluări
- Network Programming Elective)Document2 paginiNetwork Programming Elective)Atanu GhoshÎncă nu există evaluări
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziDe la Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziÎncă nu există evaluări
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveDe la EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveÎncă nu există evaluări
- Generative AI: The Insights You Need from Harvard Business ReviewDe la EverandGenerative AI: The Insights You Need from Harvard Business ReviewEvaluare: 4.5 din 5 stele4.5/5 (2)
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldDe la EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldEvaluare: 4.5 din 5 stele4.5/5 (55)
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeDe la EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeEvaluare: 4.5 din 5 stele4.5/5 (69)
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindDe la EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindÎncă nu există evaluări
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)De la EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)Încă nu există evaluări
- Four Battlegrounds: Power in the Age of Artificial IntelligenceDe la EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceEvaluare: 5 din 5 stele5/5 (5)
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldDe la EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldEvaluare: 4.5 din 5 stele4.5/5 (107)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewDe la EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewEvaluare: 4.5 din 5 stele4.5/5 (104)
- Working with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)De la EverandWorking with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)Evaluare: 5 din 5 stele5/5 (5)
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessDe la EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessÎncă nu există evaluări
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesDe la EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesEvaluare: 4.5 din 5 stele4.5/5 (13)
- Artificial Intelligence: A Guide for Thinking HumansDe la EverandArtificial Intelligence: A Guide for Thinking HumansEvaluare: 4.5 din 5 stele4.5/5 (30)
- Python Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionDe la EverandPython Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionEvaluare: 5 din 5 stele5/5 (2)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsDe la EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsÎncă nu există evaluări
- Make Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryDe la EverandMake Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryÎncă nu există evaluări
- A Brief History of Artificial Intelligence: What It Is, Where We Are, and Where We Are GoingDe la EverandA Brief History of Artificial Intelligence: What It Is, Where We Are, and Where We Are GoingEvaluare: 4.5 din 5 stele4.5/5 (3)
- T-Minus AI: Humanity's Countdown to Artificial Intelligence and the New Pursuit of Global PowerDe la EverandT-Minus AI: Humanity's Countdown to Artificial Intelligence and the New Pursuit of Global PowerEvaluare: 4 din 5 stele4/5 (4)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkDe la EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkEvaluare: 4 din 5 stele4/5 (7)
- The Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsDe la EverandThe Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsÎncă nu există evaluări
- Hands-On System Design: Learn System Design, Scaling Applications, Software Development Design Patterns with Real Use-CasesDe la EverandHands-On System Design: Learn System Design, Scaling Applications, Software Development Design Patterns with Real Use-CasesÎncă nu există evaluări
- System Design Interview: 300 Questions And Answers: Prepare And PassDe la EverandSystem Design Interview: 300 Questions And Answers: Prepare And PassÎncă nu există evaluări
- Architects of Intelligence: The truth about AI from the people building itDe la EverandArchitects of Intelligence: The truth about AI from the people building itEvaluare: 4.5 din 5 stele4.5/5 (21)